![[Georgia Tech]](gt.gif)
![[GVU]](gvu.gif)
![[People]](people.gif)
![[Search]](search.gif)
Back to Home Page
Animated Speakers
Video-driven facial animation
The Animated Speakers Kit allows to generate automatically 2D and 3D facial animation directly from the analysis of any speaker's video sequence. It results in a perfectly lip-synched animation as the facial motion is continuously captured and coded in terms of four phonetically-oriented parameters, or Facial Speech Parameters (FSP). The system is based on an analysis-by-synthesis method. An accurate 3D model is learned off-line from an expert phonetician subject to statistically learn the fundamental bio-mechanical degrees of freedom in speech production expressed by the FSP. Using a morphological adaptation, these degrees of freedom are re-mapped on any new subject to analyze his facial motion. The video analysis consists in an optimization procedure which aligns a textured version of the 3D model and the incoming video footage. The facial motion coded by the FSP is re-targeted to 2D and 3D animation.
The hypothesis explored in this work is to test if the coding of facial morphology and the coding of facial motion can be separated. Currently, we explored this hypothesis in the domain of speech production with this set of FSP parameters (articulatory hypothesis), which have shown some speakers independent properties.
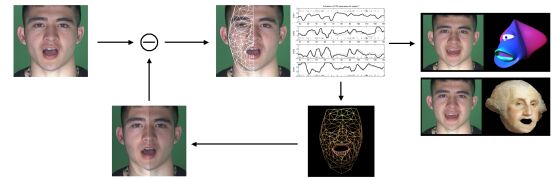
Analysis by Synthesis method to extract, code and re-target facial motion
The movie Animated Speakers (20MB) presents in a 2 minutes presentation several results of the video tracking process and the resulting facial animations.
1. Linear model of facial speech motion
registration of 3D data
The registration of 3D data from a reference subject is extracted from 3 calibrated camera by stereoscopic reconstruction.
A set of 34 shapes are collected (vowels and consonants in different vocalic contexts) to cover the whole phonetic space.


statistical learning of Facial Speech Parameters (FSP)
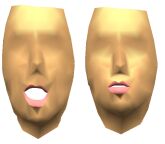
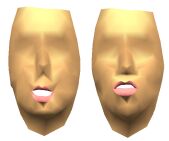
Once those shapes have been collected, an iterative statistical analysis is applied to separate and linearly code the influence of jaw and lips on the facial motion. This analysis shows a phonetically-oriented coding into four main parameters : (1) jaw opening (FSP1), (2) lips rounding (FSP2), (3) lips closure (FSP3) and (4) lips raising (FSP4). Any new 3D shape is coded as a linear combination of the variations along the 4 FSP parameters.
Facial Speech Parameters
| jaw opening FSP1 |
lips rounding (FSP2) |
lips closure (FSP3) |
lips raising (FSP4) |
 |
 |
 |
 |
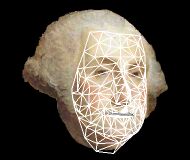
model alignment
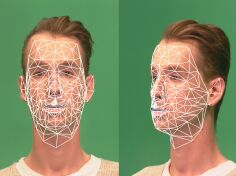
Based on the selection of 20 facial features on one single image in rest position, the original 3D model is adapted to any new subject's morphology. The linear deformation of this new shape are coded by the same FSP extracted from the reference speaker (articulatory hypothesis).

2. Video tracking
FSP extraction
Once the model has been adapted to the new subject on one single image in rest position, a texture map can be attached to the 3D model controlled by the FSP. For any new incoming video footage of this subject, the facial motion is captured and coded automatically by finding the optimal configuration of FSP values, which minimizes the difference between the original image and the textured version of the model.
tracking of the reference subject




tracking of new subjects after morphological adaptation




3. Facial Animation
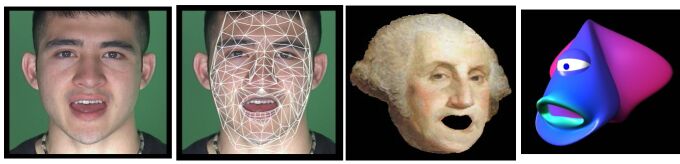
2D facial animation
Similarly to the new subject adaptation, the model can be adapted to any "face" image to provide a texture-map to the 3D model. Once the motion has been coded in terms of FSP parameters from a speaker, an animation of the image aligned to the model can be obtained from a video footage, giving a perfect lip-synch.


3D facial animation
Animation of 3D NURBS-based character is performed by assigning a morphing targets to every extreme variations of each of the 4 FSP parameters. This leads to a more natural gesture-oriented design of targets (shape for maximum opening of the jaw, maximum spreading of the lips, etc.), by opposition to traditional lip-synch animation which requires an expert knowledge on facial shape related to sound production from the animator.


Related articles
L. Reveret, I. Essa
Visual Coding and Tracking of Speech Related Facial Motion (PS.gz | PDF)
In CUES 2001 Workshop, Held in conjuction with CVPR 2001, Lihue, Hawaii,
Dec 2001,
also available as Georgia Tech, GVU Center Tech Report No. GIT-GVU-TR-01-16
L. Reveret, C. Benoit
A New 3D Lip Model for Analysis and Synthesis of Lip Motion in Speech Production (PS.gz | PDF)
Proc. of the Second ESCA Workshop on Audio-Visual Speech Processing, AVSP'98, Terrigal, Australia, Dec. 4-6, 1998.
L. Reveret, G. Bailly, P. Badin
MOTHER: A new generation of talking heads providing a flexible articulatory control for video-realistic speech animation (PS.gz |
PDF)
Proc. of the 6th Int. Conference of Spoken Language Processing, ICSLP'2000, Beijing, China, Oct. 16-20, 2000.
Sponsors.
- National Science Foundation.
Contact Information:
reveret@cc.gatech.edu
College of Computing
Georgia Institute of Technology
Atlanta, GA 30332-0280
Last Modified: 04:32:13 PM Thu, Aug 24, 1900 by Lionel Reveret (reveret@cc.gatech.edu)