ObjectSpaces
People
Goals
- Develop vision-based methods for recognizing complex human activities and
actions.
- methods for detecting and recognizing physical interactions between a person and objects in the surroundings.
- methods for recognizing multi-tasked activities
Publications
-
D. Moore, I. Essa, M. Hayes, "ObjectSpaces: Context Management for Human Activity Recognition," Proceedings of the 2nd Annual Conference on Audio-Visual Biometric Person
Authentification, Washington, D.C., March 1999. (Compressed Poscript | PDF)
- Moore, D., I. Essa, and M. Hayes, "Exploiting Human Actions and
Object Context for Recognition Tasks", In Proceedings of IEEE
International Conference on Computer Vision 1999 (ICCV99), Corfu,
Greece, March 1999. Also available as Georga Tech, GVU
Center Tech Report No. GIT-GVU-TR-99-11 (Abstract
| PS.Z | PDF)
- Moore, D. "Vision-Based Recognition of Action using Context,"
PhD Thesis, School of Electrical and Computer Engineering, Georgia Institute
of Technology, 2000. (PS.zip
| PDF, PPT
Slides, Web
page)
- Moore, Essa, "Recognizing Multitasked Activities using Stochastic
Context-Free Grammar, In Proceedings of Workshop on Models
versus Exemplars in Computer Vision, held in Conjunction with IEEE CVPR
2001, Kauai, Hawaii, December 2001. [PDF]
- Moore, Essa, "Recognizing Multitasked Activities using Stochastic
Context-Free Grammar, using Video" In Proceedings of AAAI 2002, Edmonton,
CANADA, August 2002. [PDF]
Demos
- MPEG Videos of Black Jack (recognition of multi-tasked activities, using
Semantic Context Free Grammer (SCFG)).
- Video 1: Scanning two People Playing Black Jack! [ mpg
]
- Video 2: Playing Black Jack with Some CHEATING [ mpg
]
- Video 3: Playing Black Jack with LOTS of CHEATING [ mpg
]
Results
ObjectSpaces
ObjectSpaces is an architecture that facilitates vision-based action and object recognition. We have developed ObjectSpaces as a hierarchical framework for representing prior knowledge about image contents that uses familiar object-oriented contructs call
ed classes. We also present system processes, or layers, for facilitating feature extraction, motion characterization, and scene-wide context management.
|
Indigenous hand-based actions, such as flip forward, are associated with this
book object.
|

Figure 1. Overhead view of scene with known objects highlighted.
|
- Object-oriented classes are created for each object type - Article, Person & Scene.
- Objects serve as containers for holding prior & newly discovered context.
- We track the hands of people using color & motion.
- Contact between objects and people is detected by looking for overlap between article and hand regions.
- After contact, we employ hidden Markok models (HMMs) to identify related actions associated with an object.
- We integrate image- and action-based evidence to classify unknown objects.
The Architecture
Our architecture uses an adaptive bottom-up and top-down strategy with multiple, integrated layers. This framework supports multi-domain applications, context abstraction, & class reuse. The layers facilitate mutual information to be shared when needed. F
or example, a person model in the Object layer supplies the Extraction layer with parameters that help guide color blob tracking. Likewise, blob trajectories that represent hand regions are passed back to the respective person object. The free exchange of
information throughout the layers helps to offset limitations caused by strictly bottom-up or top-down approaches. The complimentary usage of context will enable this architecture to recover from failures or inconsistencies that occur at either the lowes
t or highest levels of abstraction in the system.
- Extraction Layer - provides tracking and motion analysis facilities
- Object Layer - contains all scene articles and people objects
- Scene Layer - supervises interactions and provides domain-specific context
|
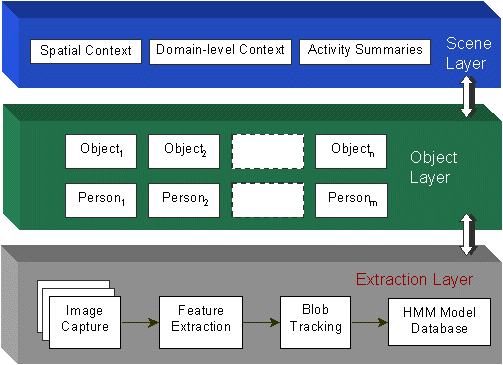
Figure 2. Information discovery, sharing, & archiving across layers.
|
The Article Class
A class is simply a data structure or properties and methods needed for implementing tasks and holding information. We begin by establishing the objects in the environment that we will focus on, deriving classes from Article for each type. Associ
ated with each object is a finite state machine driven by contact with a person. Object state or a query from the Scene layer triggers other object functions. For example, initial contact with an object forces a transition from the inactive state t
o the tentative state. If the contact turns out to be transient, the object returns to the inactive state; otherwise, it progresses to the active state, which initiates a contact event and a request to the Extraction layer to compare
hand motions against pre-trained motion models. A contact event is a record that maintains information about the interaction, such as the duration, the person performing the action, and a description of the action, if available. The Article class
is
- parent class for all non-person objects in environment,
- used to create Generalized Class Models (GCMs), which are created for every child within the class hierarchy. GCMs contain region- and image-based descriptions that are representative of all instantiations of that particular class.
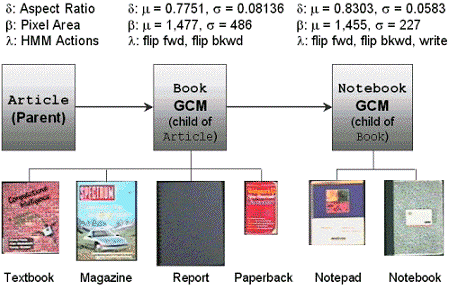
Figure 3. We look for evidence throughout the class hierarchy to differentiate between classes sharing the same parent.
Class Book : child of Article
Bounding Box [35,71,0,50]
Centroid (53,25)
Event Array [14:05:31,14:06:11,LEFTHAND,person1,flip forward]
HMMs [flip forward, flip backward]
Boolean Variables
moveable (T)
occluded (F)
contact (F)
Figure 4. Example of a book object created from parent class Article.
The Person Class
The person class works in tandem with the Extraction layer to locate people based on a model of a person. This view-based model is characterized by the arm/hand components as well as the head/torso component, as seen in Figure 5. The former component is c
haracterized by physical properties, such as hand size and skin color, as well as physiological considerations, like arm span. Likewise, size and shape specify the head/torso region. Skin color is described by an array containing all of the flesh tones in
the person's hands. This color distribution is used in the Extraction layer to assist in the segmentation the hands. We elect to use the YUV color space instead of RGB because of its separation of the luminance and chrominance bands.
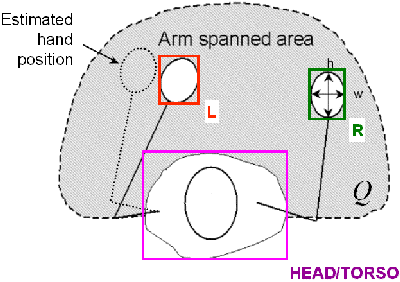
Figure 5. Model of Person includes parameters for describing hand and head/torso regions.
|
- region centroid
- color distribution
- pixel area
- perimeter edge count
- aspect ratio
- arm spanned area
- estimate of future hand position
|
The Scene Class
The Scene layer, derived from the Scene class, lies at the highest level of abstraction in the system and pays "attention" to the Object and Extraction layers. It maintains a list of scene objects and person objects. We also construct a matrix to
hold conditional probabilities between every two articles. This layer searches for correlations between object interactions in order to classify particular activities or to identify certain human behaviors. We can embed domain-specific context of our env
ironment at this level.

Figure 6. P(R|Z1) > {P(R|Z2), P(R|Z3)} where R represents a hand region.
|
Spatial context regarding the location of articles in the surroundings can be embedded into Activity zones to facilitate tracking and recognition. Consider non-overlapping regions that represent a region in the image specified by a bounding box and a pro
bability.
|
Class Reuse
- Domain-specific context embedded in Scene Layer
- Architecture supports multiple domains by abstracting context in highest layers
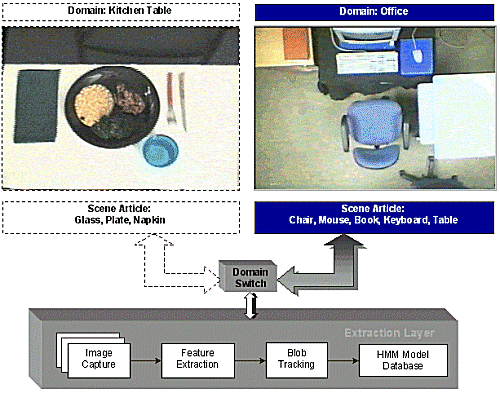
Figure 7. Framework accommodates context abstraction for application in multiple domains.
Recognizing Hand-based Actions
To determine which items in the surroundings are handled, the location of a person's hands must be recovered. We segment skin-colored blobs from each frame using a predefined color table. Starting with a snapshot of the scene at time t, I(t), we r
ifle through each pixel in the image looking for members of the color distribution. Using connected components, we propagate through B(t) to produce a set of binary regions or "blobs." Candidate blobs that do not match the profile supplied by the p
erson model are eliminated. Hand position information is accummulated in a buffer, then passed over to an HMM module that tried to identify known actions previously associated with a particular object.
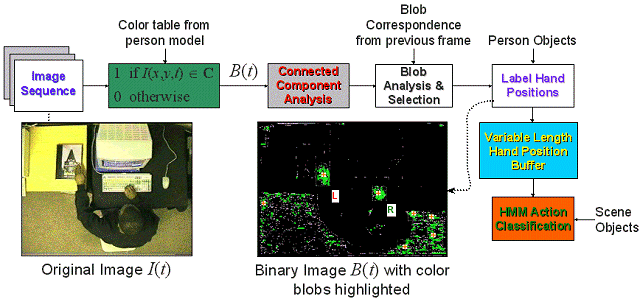
Figure 8. Process of tracking the hands and recovering meaningful actions associated with an object.
Hidden Markov Models (HMMs)
The Hidden Markov Model (HMM) can be described as a finite-state machine characterized by two stochastic processes: one process determines state transitions and is unobservable. The other produces the output observations for each state. The states are no
t directly determined by the observations; hence, the states are hidden. One of the goals of the HMM then becomes to uncover the most likely sequence of states that produced the observations.
HMMs are used to recover hand-based actions. We use HMMs because they handle space and time variable data well. To model actions that take place throughout the scene, hand position (centroid) alone is used to construct the observation feature. Our approac
h assumes a fixed, overhead camera (8'-10' from floor) so scale variation is insignificant because perspective projection distortion is small. We anticipate that actions can occur any place within the scene. However, Cartesian position is not translation
and rotation invariant. Unfortunately, observational components expressed as derivatives tend to erode the Viterbi's dynamic time warping of data, which in turn, compromises our handling of time variations.
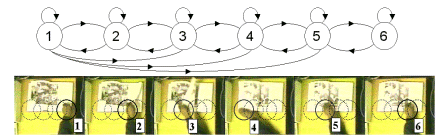
Figure 9. 6 state, semi-ergodic HMM with skip transitions and corresponding states of "flip forward" action.
To normalize motion displacement, objects provide affine transformations to deal with translation and rotation. As the hands transverse through space during some action, they pass through certain normalized areas in the image space that correspond to the
HMM's states. Hand transitions from area to area generate a sequence of states, which is used to characterize an action. We assumed all actions are single-handed motions. However, image-based methods mentioned earlier can be invoked to detect hand pair in
teraction with an object. During training, 20 examples for each action captured by the same person are manually segmented. Deliberate rest states are used as delimiters to parse individual actions during testing. The continuous HMM shown in Figure 9 was e
mpirically selected to optimize recognition. After some testing, we found this model topology to perform better than strictly "left-to-right" structures.
Object Classification
Throughout video acquisition and analysis, we collect evidence that is assessed in order to label and summarize activity as well as to identify unknown objects and people. To develop awareness of human actions as well as unknown objects introduced to a sc
ene, we merge extracted representations of motion with prior knowledge to synthesize beliefs. Bayes' theorem weighs the strength of belief in a hypothesis against prior knowledge and observed evidence. In addition, it provides attractive features, includi
ng: (1) its ability to pool evidence from various sources while making a hypothesis, and (2) its amenability to recursive or incremental calculations, especially when evidence is accumulated over time. These features motivate our application of Bayesian c
lassification to summarize activities and resolve unknown objects.
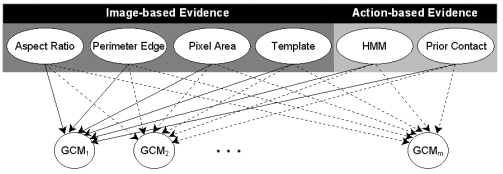
Figure 10. Belief network corresponding to a naive Bayesian classifier for selecting the most likely GCM.
VARS
The system has been implemented using C++ to run under the Win9x/NT environment in near real-time. Our approach insists on a static view of the scene from a ceiling mounted camera position. Video was acquired using color CCD cameras and a framegrabber (fr
ames acquired in YUV color space). The Vision-based Action Recognition System is shown below as it captures interactive events.
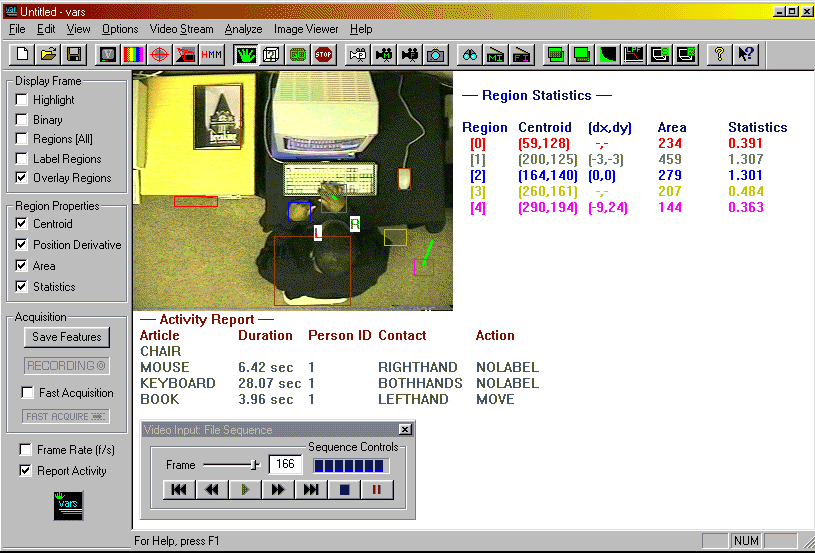
Figure 11. VARS is shown above as it captures interactive events. VARS runs on any Windows NT/9x platform in real-time (w/ framegrabber) or from stored image sequences. This system has been developed by Darnell Moore.
Results and Experiments
Experiment I: Recognizing new objects
To demonstrate detection and recognition of newly introduced objects, several of the objects (book, notebook, printer, and mouse) were carried into the scene after the background was acquired. The system was already aware of several other objects in the r
oom, including a keyboard, chair, and desk. Segmentation began immediately as initial image-based evidence of the unknown objects was acquired and initial beliefs were forged. As a person interacted with both known and unknown objects, the strength of bel
ief grew in proportion to the number of actions identified, as shown in Figure 12. New action- or image-based information is extracted for one of the four unknowns during each "event" period. Rough shape and size information was sufficient for establishin
g Z1 and Z2 early on (event 1), but not for Z3 and Z4. While relevant actions were quickly able to classify Z1 as a notebook, conflicting actions registered to Z2 during events 12, 20, and 25, respectively, compromised belief testimony. Although Z3 has no
actions associated with it, moderate belief can still be established by monitoring it's interaction with the keyboard. In general, however, articles such as Z3 stand a greater chance of being mislabeled if actions associated with other GCMs are performed
while interacting with it. Classification probability for Z1 through Z4 after 33 events (acquired over 1500 frames) was 97%, 94%, 79%, and 95%, respectively. Closer inspection reveals that 7, 12, 8, and 8 events for Z1 through Z4, respectively, were need
ed to achieve this degree of classification.
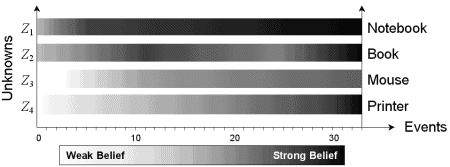
Figure 12. The strength of belief (proportional to grayscale) as image and action events are registered to one of four unknowns.
Experiment II: Recognition from action alone
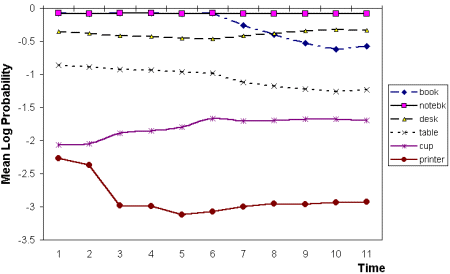
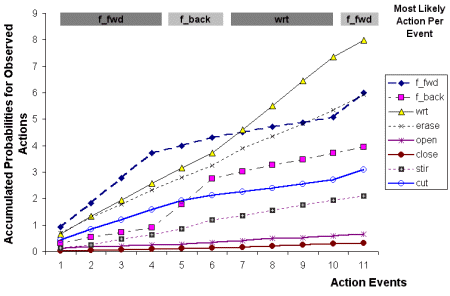
Experiments were also conducted to evaluate the strength of action-based evidence alone. Figure 13-a shows the mean log probability of candidate GCMs after 11 action events that were acquired over 583 frames. Note that belief was shared between the GCM fo
r notebook and book until event 7, when "write" was the most probable action observed, consequently rejecting book. Figure 13-b shows the accumulated likelihoods of several actions as they occurred throughout this sequence. It a
lso reveals the potential for actions to be confused. Note that some actions that never actually occurred, such as "erase," have high, accumulated probabilities, suggesting that it may be similar several of the gestures performed. As a testament to inferr
ing classification from action, adding initial image-based evidence to this action-based information yields results that were only 3% higher.
 (a) (a)
|
 (b) (b)
|
Figure 13. (a) Mean log probability of GCM classification over several action events; (b) Shows the accumulated likelihoods of several actions as they occurred throughout the corresponding sequence, with the most probable action per eve
nt highlighted.
Experiment III: Recognizing objects in the background
To demonstrate detection of unaware objects from action, we performed several eating actions ( stir, cut, feed) in an undeclared space in the scene. When actions, such as stir, occur for more than one GCM, belief is shared. Without image-based segm
entation, motion normalization suffers, resulting in lower action recognition rates and occasional mislabeling. (Notice in events 8 and 9 in Figure 14, "open" and "erase" were mistaken for "feed" and "cut".) The table GCM exhibits the strongest
belief, as shown in Figure 14. The suggested bounding box, determined by the new activity zone, appropriately covers all of the area where the activity takes place and can be used to indicate future contact with the table.
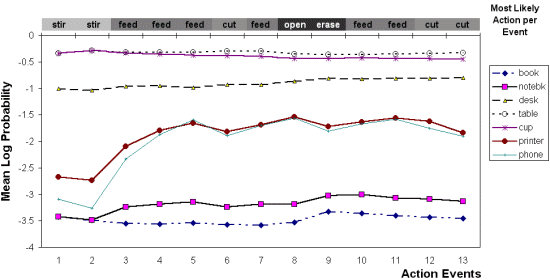
Figure 14. GCM Mean log probability of unknown object without image-based segmentation