| |
Credit
Screening
|
§ Back § |
| |
Credit
Screening
|
§ Back § |
This file concerns credit card applications. All attribute names
and values have been changed to meaningless symbols to protect
confidentiality of the data.
This dataset is interesting because there is a good mix of
attributes -- continuous, nominal with small numbers of
values, and nominal with larger numbers of values. There
are also a few missing values.
Number of Instances: 690
Number of Attributes: 15 + class attribute
Class Distribution
+: 307 (44.5%)
-: 383 (55.5%)
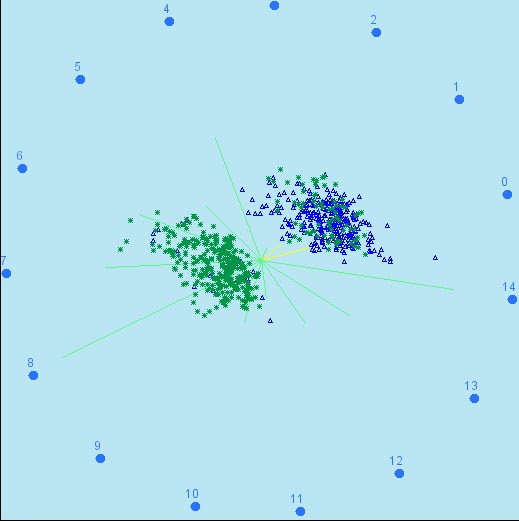
Vista visualization: 14.5% unseparated items, can
be observed in the blue cluster.