Findings

See also how people tried to help Junior and the conclusions we draw from this study.
Performance
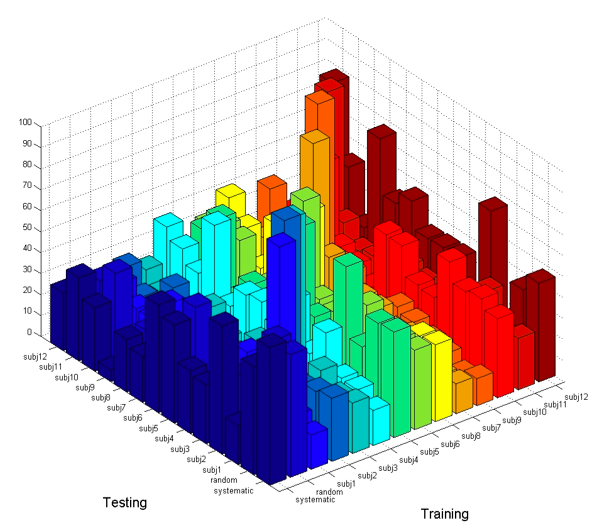
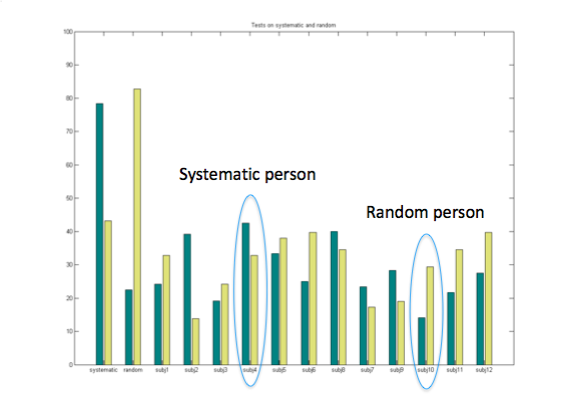
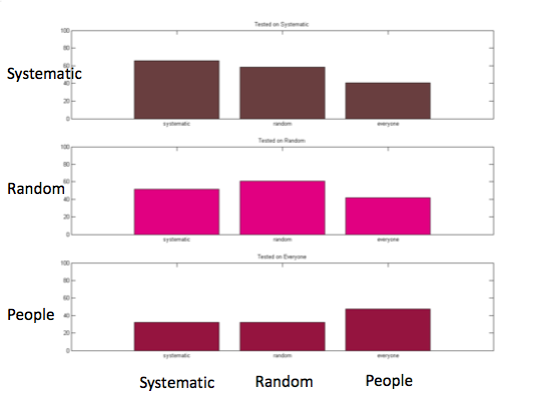

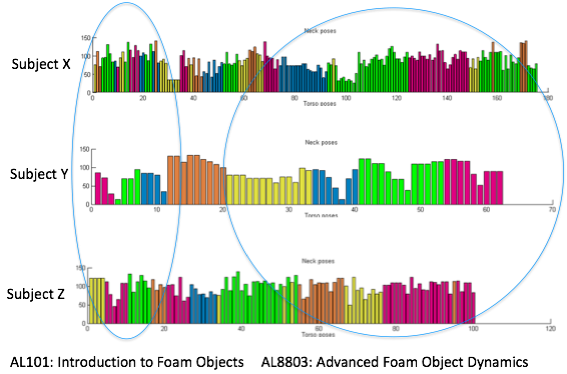
One controversial issue is how to test what has been learned by the robot. Initially we were thinking about testing with “canonical affordances” however we realized it is biased towards the social training. Similarly a random test or a systematic test would be based for the non-social training methods. Therefore we first tested every training set (systematic, random and 12 subjects) against each other.
We also trained a classifier with the combination of all teachers and got similar results.
We couldn’t find any significant difference in the t-test on any of the performance tests given above. This is natural since there is some notion of randomness and systematicness in humans behaviors. We also found that some subjects performed better on the systematic test while others performed better on the random test.
Differences
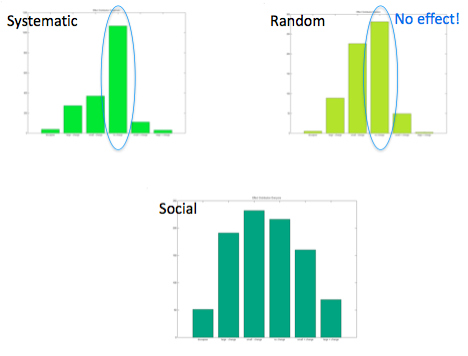
Despite the above results we believe that there are some significant differences in the training data obtained in each case. When we looked at the distribution of effect values for social and non-social cases we observed that the non-social case has much more samples in which the effect is “nothing happened”. Below are the distribution of the effect “change in x direction” which has the possible values of “object disappeared”, small/big change to the left/right and no change.
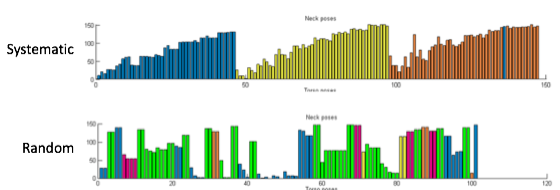
We also observed a difference in the temporal aspect of the training in different cases. We found that people start by shortly presenting each object at the beginning, and than moving on to more extensive training with each object, trying out different configurations.