School of computer science
Georgia Institute of Technology
CS6290HPCA Fall 2009
Programming assignment #3
Due: Tuesday, December 1, 6:00 pm
Hyesoon Kim, Instructor
This is an individual assignment. You can discuss this assignment with other classmates but you should do your assignment individually. Please follow the submission instructions. If you do not follow the submission file names, you will not receive the full credit. Please check the class homepage to see the latest update. Your code must run on killerbee[1-3,5].cc.gatech.edu with g++4.1.
Overview
This assignment is composed of three parts: Part 1: Complete the memory system. Part 2: Add SMT feature, Part 3(extra credit): Simulation. (part 1 and part 2: 100 points)
Part 1: Complete the memory system
Step 1:
You need to fill the dcache_access function in this assignment. I-cache is still a perfect cache for this assignment
To activate your dcache structure, you must turn off KNOB_PERFECT_DCACHE.
e.g.) ../../../pin -t obj-intel64/sim.so -perfect_dcache 0 -readtrace 1 -- /bin/ls
Note that KNOB_PERFECT_DCACHE should work even after you implement a data cache. Hence, when KNOB_PERFECT_DCACHE value is 1, regardless of data cache size, all the cache access should be cache hit.
The cache has a 64B block size, true LRU and write-through policy. D-cache access latency is set by KNOB_DCACHE_LATENCY. Note that, a load execution cycle is determined by the cache access time not the load operation latency itself. Hence, if there is a cache miss, the processor needs to wait KNOB_MEM_LATENCY cycles. We assume that the cache and the memory have enough read/write ports so all the memory requests can be handled simultaneously. You do not need to differentiate between store and load. Even store miss, the processor cannot retire the store instruction waits until the store miss is completed.
KNOB_DCACHE_SIZE, and KNOB_DCACHE_WAY set the cache configurations. Cache size should use a K-Byte unit
e.g) ../../../pin -t obj-intel64/sim.so -perfect_dcache 0 -dcache_size 1 -dcache_way 4 -readtrace 1 -- /bin/ls
cache size = 1KB, 1024/4/64=4 sets
To provide hints for building a cache, a stand alone cache simulator, cache.cc (inside lab3.tar.gz) is provided. You can design your own cache structure.
Step 2:
You need to implement a MSHR to handle memory latency correctly.
The size of MSHR is determined by KNOB_ROB_SIZE to simplify the problem. (In actual hardware, there will be fewer number of MSHR entries than ROB size.
Summary of how to handle memory instructions
- Step 1: A memory instruction is fetched, decoded, and executed. In the execution stage, it does not do any useful work for memory instructions.
- Step 2: In MEM_stage, the instruction checks dcache. (If you already have removed the mem stage,
you perform this step 2 in the EX stage.)
- Step 3(cache hit): If a cache hit, the instruction will be moved to the WB stage after KNOB_DCACHE_LATENCY.
- Step 3(cache miss): If a cache miss,
- Step 4: the instruction searches MSHR using memory address. If there is a match (i.e., the memory address is the same), the processor records the instruction id into the MSHR entry. The instruction's ready cycle is the same as the ready cycle in the MSHR. (the simulator stores op pointer inside the MSHR entry.)
When the simulator checks MSHR, it checks cache block address not the actual memory address. Because we always brining the entire cache block.
- Step 5: If there is no match in MSHR, the processor creates an entry in the MSHR and sends the memory request into the memory. To simplify the memory system modeling, we assume that the memory request will be serviced KNOB_MEM_LATENCY cycle later. Since we always set the size of MSHR as the size of ROB, there is always a free entry to insert a new request.
- Step 6: Every cycle, the simulator checks MSHR and see whether there are ready requests. (i.e. MSHR->ready_cycle > cycle_count). If yes, then all ops in the MSHR entry should broad cast tags. We insert the block into the cache at that moment.
After we insert the block into the cache, we free the MSHR entry. The ops in the ready MSHR entry are ready to retire.
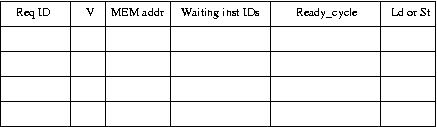
relevant data structures:
Req ID: op->inst_id should be OK to fill out this field.
V: Valid bit of this entry. Valid(true) does not mean the corresponding memory instruction is ready.
MEM addr: memory addresses
Waiting insts IDs: link list or arrays. This should have (op *)
Ready_cycle: the ready cycle when memory request is completed.
Ld or St: indication of load and store.
from op structure
op->ld_vaddr: load address
op->st_vaddr: store address
op->mem_read_size: load memory size
op->mem_write_size: store memory size
Knobs related to this assignment
KNOB_DCACHE_SIZE: data cache size (kbytes) (default value: 512)
KNOB_DCACHE_WAY: N-way set associative data cache (default value: 4)
KNOB_DCACHE_LATENCY: cache latency when a cache hit (default value: 5)
KNOB_MEM_LATENCY: cache access cycle when a cache miss ( default value: 100)
You have to update dcache_hit_count, dcache_miss_count accordingly.
Part 2: Adding an SMT feature
In this assignment, you will extend your superscalar processor to support SMT.
We need multiple steps to support the SMT feature.
Adding SMT feature requires modifications in multiple places in the simulator.
Additional data structures must be added. addme3.txt file is provided inside lab3.tar.gz file.
Knobs related to this assignment
KNOB_MAX_THREAD_NUM: number of threads that can be executed together (default 1, max 4)
KNOB_TRACE_NAME2: set the input trace file name2
KNOB_TRACE_NAME3: set the input trace file name3
KNOB_TRACE_NAME4: set the input trace file name4
First, you need to make the simulator run correctly right after you add addme3.txt file. addme3.txt file changes get_op function and add thread_id into op_struct. You need to use new trace.cpp, sim_pin.cpp, simknob.h and userknob.h. lab3.tar.gz file contains these new files.
Because now the system handles multiple traces, before you add SMT feature, you need to make it sure
that your simulator still runs one thread just like before and then you add features to support multi traces.
In a real architecture simulator, simulation ending condition should be more complicated. However, in this assignment, we do not change the ending conditions. Therefore, simulator reads from only remaining traces until all the traces are finished. max_inst_count is based on the sum of all threads.
Fetch Stage
Fetch needs to fetch from multiple threads.
get_op(Op *) function is now updated to fetch from multiple threads.
Deciding which thread to fetch is also a research topic. Several papers have been proposed to increase
a processor's utilization. In this assignment, we just simply use a round-robin fashion. add_me3.txt file already has this feature.
op->thread_id shows which thread id of each op.
After fetch, the simulator accesses a branch predictor just like before.
In the real hardware, the hardware needs multiple PCs.
You need to have different GHR for each thread.
However, a 2-bit counter table is shared among all threads
Branch misprediction handling
When a thread is mispredicted, you must set br_stall[op->thread_id] = true.
When the mispredicted instruction is resolved in the execution stage, you should reset br_stall[op->thread_id]=false.
get_op function checks br_stall and if there is a misprediction, it doesn't fetch from the mispredicted thread.
please look at updated addme3.txt
Decode Stage
The simulator inserts ops into the ROB just like before.
When there is a space, the simulator also inserts an op into the scheduler.
We do not really need them but in theory, we need to have multiple of reg, so
we need reg[MAX_THREAD][NUM_REG].
Rename
We need to have multiple RAT tables.
If you have used reg_map for programming assignment #2, you need to change reg_map[NUM_REG] to reg_man[MAX_THREAD][NUM_REG].
(Note that you could use KNOB_MAX_THREAD_NUM.Value() to allocate the exact amount of memory space at run-time or you can use MAX_THREAD to allocate the structure in advance. )
Now, whenever you access reg_map structure, you always use op->thread_id to index different reg_map structure.
Schedule
No modification is needed. Just whenever the sources are ready, the simulator removes instructions from the scheduler and send them to execution stage.
This works for an out of order scheduler. In-order scheduler, even if the oldest op is not ready,
if there are ready instructions from other threads, that should be scheduled. However, to simplify the assignment, we do not provide this feature.
Execution
At the execution stage, when the simulator broadcast the results, just make it sure that it sets dependent instructions only for the same thread id ops. If you have used inst_id for tag, you do not need to do any additional work since inst_id is unique including all the threads.
Memory
We assume that the memory addresses that we have is physical address. So you do not need to differentiate memory addresses among threads.
WB
When instructions are retired, it has to be in-order within a thread. Across threads, the processor can retire instructions out of order. In programming assignment #2, when an op is not finished, we stop the retirement. In this assignment, even though an op is not finished, if there are finished ops from other threads, the processor should retire them.
Hence, if you have used data structures in prog2_hits.html, your code would be something like this.
for (int ii = 0; ii < KNOB_MAX_THREAD_NUM.Value(); ii++) {
thread_retire_stop[ii] = false;
}
retired_thread_here = 0;
for ( traverse rob structure using whatever data structure that you have) {
if (op->done && !thread_retire_stop[op->thread_id] ) {
// free rob
// free op
retire_count++;
if (retire_count ==KNOB_ISSUE_WIDTH.Value()) {
break;
}
} else {
if ((thread_retire_stop[op->thread_id]==false) {
retired_thread_here;
thread_retire_stop[op->thread_id] = true;
}
if (retired_thread_here > KNOB_MAX_THREAD_NUM.Value()) break;
}
}
}
Stats
Now, we need to collect stats per thread rather than all threads together.
We collect separate retired_instruction_thread, bp_miss_count_thread, bp_corr_predict_thread, dcache_miss_count_thread, dcache_hit_count_thread counters. The simulator should update retired_instruction, bp_miss_count, bp_corr_predict, dcache_miss_count, dcache_hit_count with all threads also.
For example, for branch misprediction counts,
if (bp_corr) {
bp_corr_predict++;
bp_corr_predict_thread[op->thread_id] = bp_corr_predict_thread[op->thread_id]+1;
}
Submission Guide
Please do not turn in pzip files(trace files). Trace file sizes are so huge so they will cause a lot of problems.
(Tar the lab3 directory. Gzip the tarfile and submit lab3.tar.gz file at T-square)
Please make it sure the directory name is lab3!
cd pin-2.6-27887-gcc.4.0.0-ia32_intel64-linux/source/tools
cd lab3
make clean
rm *.pzip
cd ..
tar cvf lab3.tar lab3
gzip lab3.tar
Part 3: (Extra 20 pts): Simulation
Due date for Part 3 is in class. Thursday, December 3
Include your simulation results in a report. You do not need to submit any traces.
The default configurations are
gshare history length: 12
issue width: 4
out of order scheduler
ROB size: 64
scheduler size: 16
cache size, way: 512KB 4 way
Dcache latency: 5 cycles
mem latency: 100 cycles
Use 2 benchmarks: one is very memory intensive and the other is non-memory intensive. (a simple matrix multiplication would use lots of memory operations.)
- Vary the cache size ( 128KB, 512KB, 1MB, and 2MB) and measure the IPC and cache hit ratio. Discuss the performance improvements. Estimate a working set size based on the evaluated four points.
Where you see a big cache hit ratio increment when you increase the cache size is the estimated working set size.
- Vary rob size from 32, 64, 128, 256, 512, and 1024 and vary the knob_mem_latency from 6, 50, 100 and enable perfect dcache (total 4 test cases). Discuss the rob size effect as we increase cache latency.
- Vary scheduler size when rob size is 128. scheduler size 8, 36, 64, 128.
Discuss the effects of scheduler.
(Hints, the size of scheduler shouldn't be that much sensitive. Why? )
2-way SMT architecture.
- For SMT, create 2 benchmarks using 3 traces (trace1+trace2, trace1+trace3, trace2+trace3). Show weighted IPC results.
weighted ipc = Sigma(i,n) (ipc_smt(i)/ipc_alone(i))/n
- Classify three traces as memory intensive or not. Discuss the performance impacts.
- Discuss branch prediction accuracy effect in SMT. Do you see degradation compared to a single thread running? why or why not?
- You could notice that one benchmark finishes much faster than others. Discuss how we should
simulate benchmarks to reduce the simulation errors.