Project 2: Local Feature Matching


|
| Accuracy = 97% |


|
| Accuracy = 83% |
Interest Point Detection.
I implemented the Harris corner detector that says that corners are good interest points. Corners are unique in that they exhibit large contrast changes (gradients), and they are easier to localize (as opposed to straight line segments that suffer from the aperture problem). I used a simple response function that is calculated at each pixel based on the x and y derivaties of an image convolved with Gaussians like:
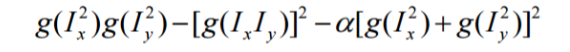
My
- Step 1: Convolve the image with a Gaussian.
- Step 2: Compute the x and y gradients of this new image.
- Step 3: Calculate Ix^2, Iy^2, Ixy.
- Step 4: Use the above formula to produce a 'corner response' (scalar interest measure) value for each pixel and convolve this with a larger Gaussian.
- Step 5: Find the local maximas by running a sliding window over this response matrix, and clamp the non-maximas to 0.
- Step 6: Now, for all the points, check if their value is greater than an acceptance_threshold and also if they do not lie too close to the boundary. Append the x and y coordinates of these points to the respective column vectors.
Some parameter tunings that I made to achieve really high accuracies for Notre Dame (97%) and Mount Rushmore(83%):
- An acceptance_threshold of 0.15
- Local_window size as feature_width/2.
- Gaussean sigmas = 0.5, smaller filter of size 3x3 and larger filter of size 7x7.
Instead of looking for local maxima in the interest function, that can lead to an uneven distribution of feature points across the image, e.g., points will be denser in regions of higher contrast, i used ANMS to mitigate this problem. Algoirhtm:
- Step 1: Create a distance matrix of the distance between all pairs of interest points.
- Step 2: Sort D's columns.
- Step 3: For every candidate interest point I search that point's neighbors in increasing order of distance.
- Step 4: The first found point where our candidate point's corner response value is 10% larger gives us the r value for that candidate point.
- Step 5: Return the points with r>threshold_r.
After trying several values for thresholding r, i decided to go with 0.002.
|
|
| Accuracy = 97% |
Local Feature Descriptors.
After producing a set of interesting points, the second step in the pipeline is to create features that describe each of these points. The descriptor should ideally be robust to lighting and viewpoint changes while still being highly discriminating. The SIFT descriptor consists of gradient magnitude-weighted histograms of gradient orientations. I divided the feature window into a grid (4x4). For each cell of this grid, I created a histogram on the image's gradient orientations, weighted by the magnitude of the gradient. Appending these histograms from each cell, I created my feature vectors with the following properties:
- Feature_width waas set to 16 for best accuracies.
- Every feature is made up of 128 dimensions.
- Every feature has been normalized to unit length.
My
- Step 1:Calculate the gradient (magnitude and orientation) of the image.
- Step 2: For each interest point, do the following:
- Step 2.1: Construct a feature_width X feature_width window centered on the interest point.
- Step 2.2: Iterate through the window as a grid, cell by cell and for each cell do the following:
- Step 2.2.1: Compute a histogram of the gradient orientations in that cell and weight it with the gradient magnitudes. Since there are 8 bins, I divided the orientation space into equal 45 degree intervals.
- Step 2.2.2:Append the histogram vector (8x1) to the feature_vector.
- Step 2.3:Normalize the feature vector(128x1), clamp it at a threshold (0.2), renormalize it.
- Step 2.4:Add it to the list of features.
I experimented with different feature sizes and cell sizes by changing the feature_width and ultimately decided to stick with a feature width of 16,cell size of 4x4, feature size of 128, giving highest accuracy of 97% for the Notre Dame pair of images. below are the results I obtained after tuning:


|
| feature_width = 8, Feature size = 64, cell size = 2x2, Accuracy = 77% |


|
| feature_width = 32, Feature size = 512, cell size = 8x8, Accuracy = 89% |
I also observed that the run time was proportionally increasing with the increase in feature size.
Feature Matching.
Now that the 2 useful feature descriptors are available, the next step in the pipeline is to match these features. I implemented the K-Nearest Neighbour search to find the 2 closest interest points in Image2 for every interest point in Image1. And then used the ratio of their distances for the "Nearest neighbour Ratio Test".
My
- Step 1: Find the 2 closest features in Image2 for every feature in Image 1 using knnsearch.
- Step 2:The closest feature is the matched feature. For this matched pair, compute the confidence as (1-nn_ratio).
- Step 3: Sort these matched pairs by decreasing confidence and return the matches.
Knnsearch (kd-tree) ran slightly faster than doing the naive pdist2 computation and then sorting this matrix. Another confidence metric that I tried was (1/nn_ratio) which yielded slightly poorer results than (1-nn_ratio). (1-nn_ratio) I feel is a better metric as on expanding it is the ratio of the difference(d2-d1) with d2.
Episcopal Gaudi performance.


|
| Accuracy = 5% |
My entire pipeline and paramter-tuning worked really well for images with minor differences in size and orientation such as Notre Dame and Mount Rushmore. However, for the Gaudi pair of images, it does not scale well as the 2 images are very different and a scale-invariant version is needed. A terribly low accuracy of 5% was obtained.