![[ 2 ]
A = Ix IxIy ,
IxIy I2y](index0x.png)
The purpose of Project 2 was to explore local feature matching by recreating parts of Lowe’s SIFT pipeline [1]. This report is structured according to the three major challenges that were addressed in the project: keypoint identification, feature description, and feature matching. For each stage of the project, multiple approaches were taken to improve the accuracy of image matching.
The first step in feature matching between images was to identify keypoints. The Harris Corner detector was implemented to identify corners in the images [2]. The autocorrelation matrix
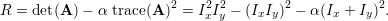
Identifying Local Maxima To improve distribution of feature points about the image, image dilation was used to identify local maxima of the corner value matrix. Identifying local maxima above a threshold produced a greatly reduced number of keypoints, which improved execution time at the cost of accuracy.
Adaptive Non-Maximal Suppression To improve distribution of selected feature points about the entire image rather than about areas with high contrast, adaptive non-maximal suppression (ANMS) was implemented [3]. The implementation of ANMS was essentially an exhaustive nearest-neighbour search which was used to identify the nearest-neighbour with a higher corner value; the distance to this neighbour is the radius described by Brown et. al. in [3]. The feature points were sorted by their radii, and the top N were chosen.
A baseline feature descriptor was generated by normalizing a 16 × 16 pixel patch to unit magnitude; this provided a simple baseline comparison for more complicated feature descriptors.
A SIFT-like descriptor was implemented about each keypoint identified by the Harris Corner detector. The polar form of the image gradients Ix and Iy were determined in a 16 × 16 pixel neighbourhood centred on the feature point. The neighbourhood was discretized into 16 4 × 4 pixel cells. In each cell, a histogram of 8 gradient orientations (-180∘ : 45∘ : 180∘) was built by adding the magnitudes corresponding to these gradients to each bin of the histogram. The histograms of each cell were concatenated into a single 128 element feature vector for each keypoint, and the feature vector was normalized to unit length.
PCA Feature Descriptor Principle component analysis (PCA) was used to reduce the dimensionality of the 128 element feature descriptor to 32. PCA was considered as a method of reducing the lengthy execution time of the program.
Using the feature descriptors for each feature identified by the Harris Corner detector, an exhaustive nearest-neighbour search algorithm was implemented to determine matches between feature points in different images. The nearest neighbour distance ratio (NNDR) defined by Mikolajczyk and Schmid [4] was used to determine match confidence of each feature point to its nearest neighbour; the NNDR is given by:
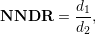
kd-Tree for KNN Approximation Rather than exhaustively search for the 2-NN of each feature point, a kd-tree was used as in [1] to reduce computation time by approximating the first and second nearest neighbours for each feature point.
The following results are presented for the Notre Dame image pair to identify the effects of the various modifications to the original project. The following parameters were used: α = 0.3, corner value thresholding was set to 0.08, and confidence thresholding was set to 0.8.
The baseline implementation of local feature matching between images for this report uses the the Harris Corner detector to identify keypoints, the SIFT-like feature to describe them, and an exhaustive 2NN search to match features between images. With this pipeline, accuracy as high as 92.00% was recorded by taking the top 100 most confident matches.
To examine the quality SIFT-like feature descriptor, the normalized image patch feature descriptor was used. All else being equal, the normalized image patch feature descriptor was capable of 40% accuracy. A significant improvement in local feature matching between images was achieved by implementing the SIFT-like feature descriptor, easily yielding 70% accuracy before parameter tuning. The massive increase in accuracy can be attributed to the invariance of the SIFT feature descriptor.
The baseline implementation presented above was modified primarily to improve execution time–three approaches were taken in this regard, each improving execution time at a cost of accuracy. First, thresholding of a dilation of the corner value matrix was used to identify local maxima. Second, rather than exhaustively determining the 2 nearest neighbours for NNDR and feature point matching, a kd-tree was used to make an approximation of the 2NN search. Lastly, PCA was used to reduce the size of the feature vector from 128 elements to 32. Combining local maxima identification and kd-tree search reduced execution time from the order of minutes to approximately 12 seconds with a modest drop in accuracy to 78%. By comparison, PCA had a negligible effect on execution time, so the loss of accuracy incurred did not merit its use.
Adaptive non-maximal suppression was implemented, and while the it was successful in distributing the keypoints throughout the image, a decrease in accuracy was observed. This decrease in accuracy was not caused by the ANMS, but rather by the feature matching, highlighting a major limitation of the methods employed. In situations in which the same features are not identified between images, accuracy can be expected to be poor. Thresholding the confidence of the matches helped reduce the effect of having few feature points in the intersection of the feature points of both images, but more sophisticated methods should be employed to achieve marked improvements in feature matching between images. A method of rejecting features for which no match exists would achieve such improvements. RANSAC has obvious application to rejecting poorly matched features and would likely improve the results.
Figure 2 shows a side-by-side comparison of the top 100 matched feature point pairs identified for a trial using the kd-tree nearest neighbour approximation that resulted in 85% accuracy.
Figure 3 highlights the limitation of the nearest neighbours matching algorithm. While the use of kd-tree approximations to the nearest neighbours was partly responsible for some mismatches, of the points that were incorrectly matched, it is evident that many did not have a correct match (e.g. the intersection of the feature points of each image was not large enough to achieve perfect matching). Identifying these outlying feature points is an obvious next step in improving local feature matching between images.
The Gaudi Episcopal image pair shown in Figure 4 highlights the difficulties noted above and accentuates them with differences in scale and illumination between the images, making confident matching difficult. While tuning can improve accuracy, both keypoint detection and the matching method employed were largely responsible for poor accuracy observed.
Figures 5 and 6 are presented without knowing ground truth accuracy to demonstrate that despite the limitations of the pipeline, qualitatively reasonable accuracies can be achieved. Feature points in both the House and Statue image pairs are clearly shared, and the image matching appears reasonable. The fact that ground truth is unknown highlights the fact that we do not have a metric of the confidence of an image match itself; this would be a useful metric to judge the quality of an image match.
While the results demonstrate that image matching was reasonably successful on multiple image pairs, limitations of the matching methods were a major limitation of the pipeline. Future work should address this limitation by implementing a more sophisticated matching algorithm such as RANSAC. Aside from limitations of the methods themselves, parameter tuning is a major concern. For each image pair, altering thresholds had a significant effect on the number of interest points detected and the number of confident matches. To improve image matching by local feature matching, a general (preferably automatic) method of tuning should be devised.
[1] D. G. Lowe, “Object recognition from local scale-invariant features,” in Seventh International Conference on Computer Vision, 1999.
[2] C. Harris and M. J. Stephens, “A combined corner and edge detector,” in Alvey Vision Conference, 1988.
[3] M. Brown, R. Szeliski, and S. Winder, “Multi-image matching using multi-scale oriented patches,” in IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005.
[4] K. Mikolajczyk and C. Schmid, “A performance evaluation of local desciptors,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004.





