Overview
In this project I implemented a local feature matching pipeline which uses Harris corener detector to find interest points and SIFT descriptor to describe local features. Except for the baseline implementation, I also implemented PCA-SIFT to reduce the dimensionality of features and speedup the matching process.
Matching accuracy on Notre Dame image pairs is 84% for the 100 most confident matches, and 89% for Mount Rushmore pairs.


Result of top 100 most confident matches, 84 are correct.
.jpg)
.jpg) Result of top 100 most confident matches, 89 are correct.
Result of top 100 most confident matches, 89 are correct.
Interest Point Detection
So the first step in this local feature matching is, obviously, to find potential keypoint that can be used to match between images(unless we want to compare every pixel!). These points need to be distinctive enough that the detector will find these same point over all possible image. Harris corner detector is one of the widely used method and will be the baseline algorithm for keypoint detection in this project. The Harris's score of being a corner can be computed by:
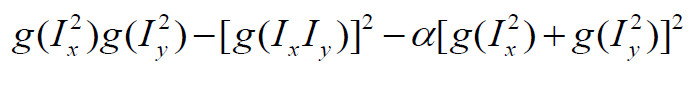

Harris corner results with threshold = 0.01 * max score
- Compute image gradient Ix and Iy (convolve with horizontal and vertical derivative of Gaussian), then Ix^2, Iy^2 and IxIy, convolve these terms with Gaussian filter, and plug into the equation to get cornerness score R
- Threshold out points below certain score, 0.01 * Rmax.
Local Feature Description
My implementation of SIFT descriptor mostly follows David Lowe's paper Distinctive image features from scale-invariant keypoints.The following is my steps of computing SIFT feature.
- Find the image patch (16 x 16) around interest point accoring to feature width at the scale this point is detected.
- Compute gradient magnitude and direction of this patch.
- Use a Gaussian to weight the magnitude.
- Histergram statistics. In each cell (4 x 4), put every pixel into 8 bins according to its direction relative to the dominant direction, and accumulate the gradient magnitude.
- Normalize the feature vector to unit length. Chop off values over 0.2 and normalize again.
Feature Matching
The matching process is pretty straight forward. I just compare the Euclidean distance between each pair of keypoints, according to how different their features are. In this project, I use distance ratio between 2 nearest neighbors as a criteria, i.e. confidence = 1 - d1/d2, which will be sorted before output as the 100 most confident matches.
Other Results
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
PCA-SIFT
It computes the x and y (gradient) derivatives over a 39 × 39 patch and then reduces the resulting 3042-dimensional vector to 36 using principal component analysis (PCA)
.jpg)
.jpg)
The matching accuracy of Notre Dame pairs is 1.69%, after using PCA-SIFT. It means we did't capture the feature when reducing its dimension using PCA. Detailed feature engineering should be done here.