Project 4 / Scene Recognition with Bag of Words
Introduction
This project has two primary parts:
- Getting Features: by getting tiny images and then by getting bags of SIFT.
- Classifying Featurs: by utilizing nearest neighber classifier and then by SVM classification.
The Algorithm
Get tiny images is a fairly rudimentary implementation - this function resizes the image so that it is "tiny," and then reshapes it for easier comparison.
Get bags of SIFTs get descriptive patches of the image. The most similar vocabulary word to a patch is assigned with a histogram representation.
Step size experimentation in Get Bags of SIFTs drastically affected the results of this project. I started out with a step size of 15 and moved gradually down, testing incrementally. At 10, the accuracy was around 45%. At 8, accuracy was around 57%. Finally, step sizes of 5 and 6 were optimal, producing accuracies of around 63%.
The Nearest Neighbor Classifier finds the best label for each test image by finding the difference between all training images and all testing images. The images are then paired by their minimum difference. The corresponding training image label is then assigned to the testing image.
The SVM Classifier separates images of a certain category from images not in that category. This occurs by finding some line that then classifies the images into a binary classification.
Lambda experimentation had high effect on the results of this project. I started with 1 and worked my way all the way down to what worked optimally for my configuration, .000001. Using 1 as lambda yielded an accuracy of about 39%, whereas using .000001 yielded an accuracy of about 63%.
 Get Features: Get Tiny Images
Classification: Nearest Neighbor
Accuracy: 19.1%
Get Features: Get Tiny Images
Classification: Nearest Neighbor
Accuracy: 19.1%
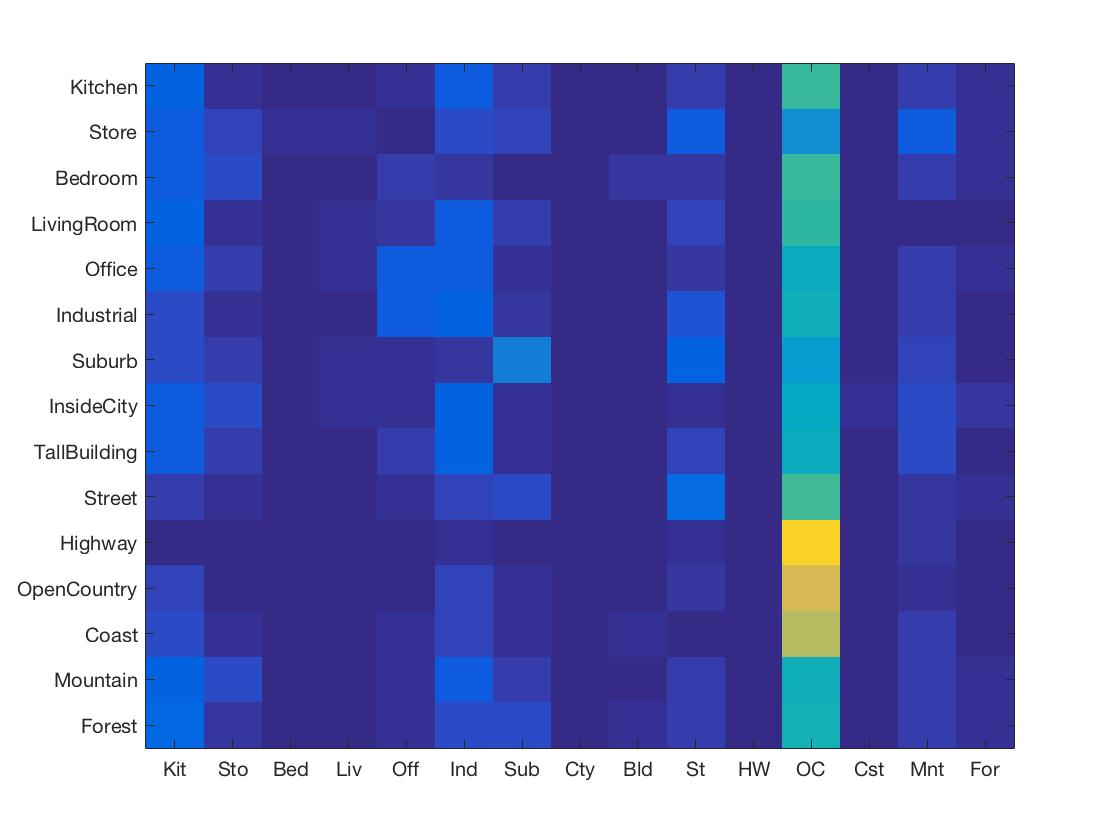 Get Features: Get Tiny Images
Classification: SVM
Accuracy: 11.6%
Get Features: Get Tiny Images
Classification: SVM
Accuracy: 11.6%
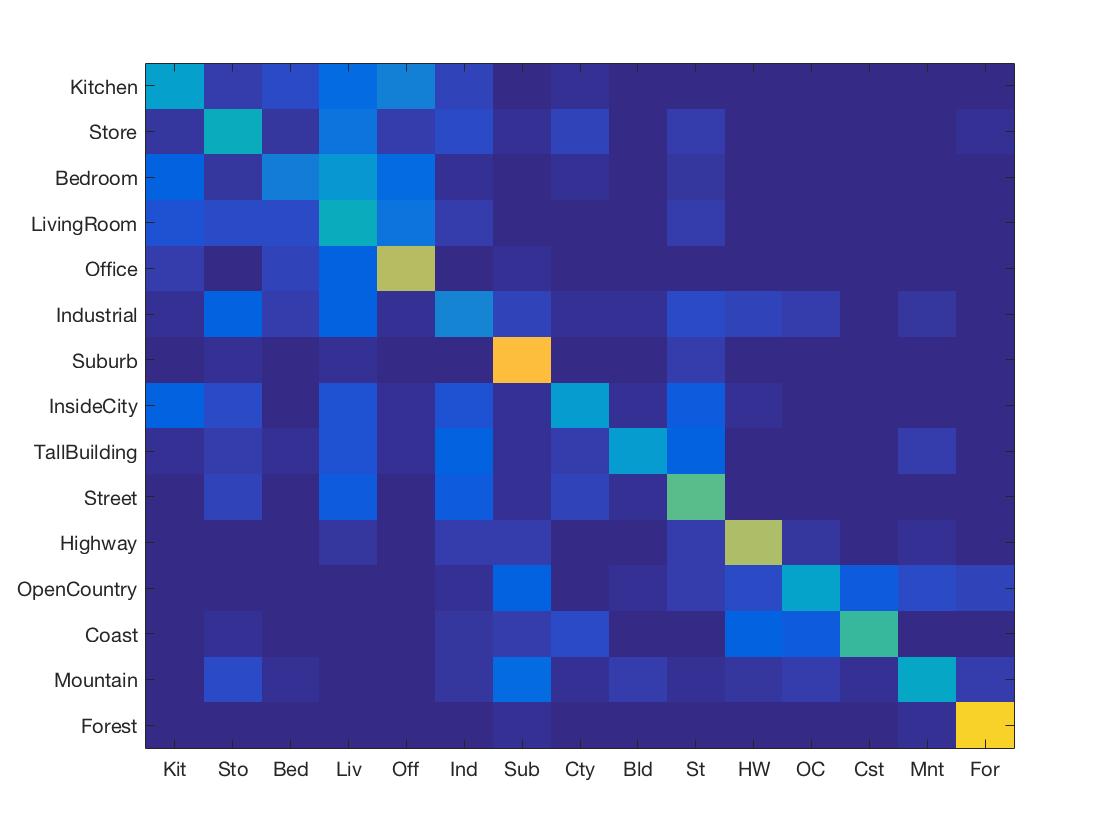 Get Features: Get Tiny Images
Classification: Nearest Neighbor
Accuracy: 48.3%
Get Features: Get Tiny Images
Classification: Nearest Neighbor
Accuracy: 48.3%
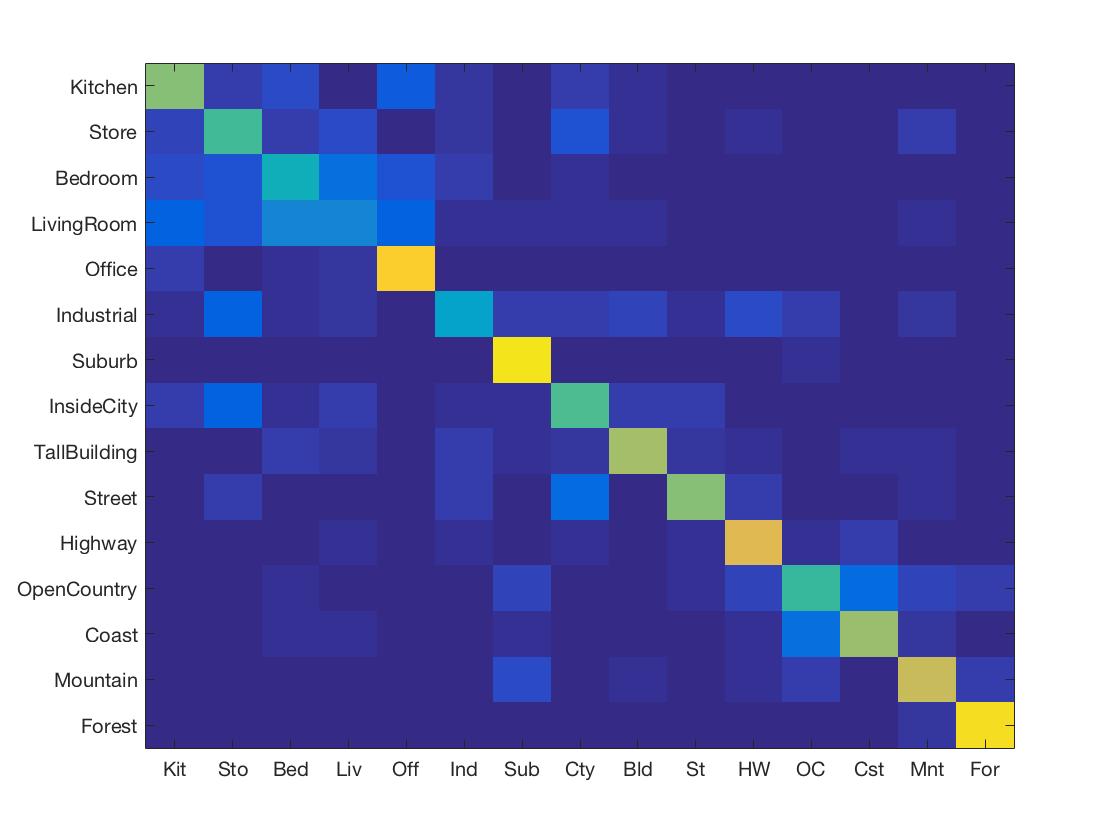 Get Features: Get Tiny Images
Classification: SVM
Accuracy: 62.6%
Get Features: Get Tiny Images
Classification: SVM
Accuracy: 62.6%