Project 4 / Scene Recognition with Bag of Words
This project deals with the problem of Object Recognition.
The following tasks and extra credit enhancements were completed.- Tiny image representation
- Bag of Sift Representation
- Nearest Neighbor classifier
- One vs All Linear SVM classifier
- Kernel codebook encoding (Extra Credit 1)
- Finding optimal number of cluster centers for Kernel Codebook encoding (Extra Credit 1)
- Evaluating performance by varying vocabulary size (Extra Credit 2)
- Adding gist descriptors (Extra Credit 3)
The final accuracy with [bag_of_sift + gist descriptor + svm + kernel codebook encoding (3 clusters)] came to about 77%
Tiny Image Representation + Nearest Neighbor Classifier
Each image is resized to 16*16 dimensions and then converted to a 1*256 vector representation. The vectors were mean normalized by subtracting the mean and dividing by the standard deviation along each dimension.
mu = mean(image_feats, 1);
variance = var(image_feats);
image_feats = bsxfun(@minus, image_feats, mu);
image_feats = bsxfun(@rdivide, image_feats, sqrt(variance));
For the nearest neigbor classifier, L2 distance metric was used to return the label of the point in the training set which is closest to the test example. The accuracy achieved after this stage was around 19.3%. The following figure shows the confusion matrix.
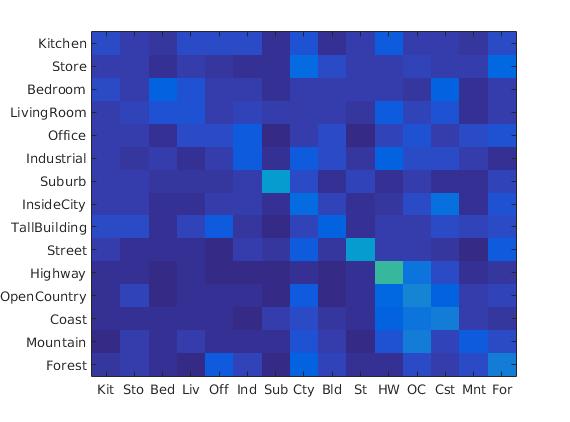
Bag of Sift + Nearest Neighbor Classifier
The bag of sift is similar to the bag of words model which relies on the existence of a vocabulary of visual words. The vocabulary is computing average SIFT vectors from a large number of images. These can be computed by a standard clustering technique. In this project we used K-means. Given these visual word cluster centers available, to compute the feature vector representation of an image, we compute the SIFT feature vectors and build a histogram of counts of feature vectors assigned to the each cluster center. A SIFT feature from an image casts a vote of 1 to the nearest cluster center. Later on, we improve this model by the Kernel Codebook Method and Gist features. After implementing this, the average accuracy achieved was around 53.7%
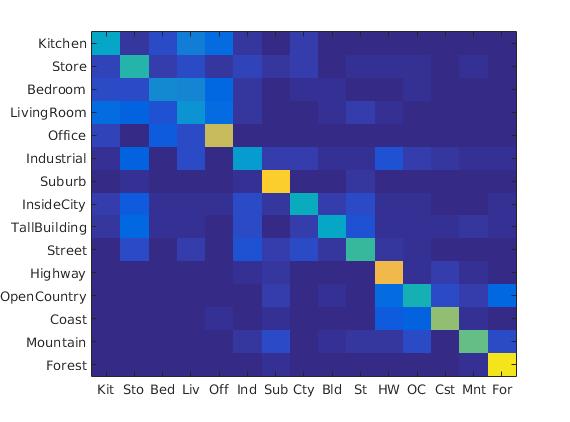
Bag of Sift + SVM Classifier
We now use a linear SVM classifier instead of a nearest neighbor classifier. The SVM is inherently a two class classifier and thus to use it for multiclass classification we train several SVMs in the one-vs-all fashion. We train as many SVMs as there are categories in the dataset. The first SVM is trained with positive examples belonging to all objects belonging to that category and all negative examples as objects not belonging to that category.
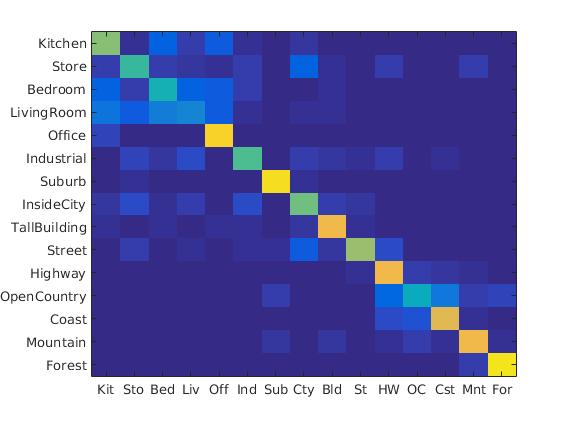
Parameter Tuning
Though I did not use a formal grid search or a cross validation set to tune the various parameters I tried various values of the parameters and report the ones which gave the best performance. The following are the list of parameters which were varied and experimented with.- vl_dsift parameters: size'4' and step '8' gave the best performance, although it was very slow. We also used the 'fast' param to speeden things up
- svm lambda: 0.0001, higher values than this gave worst performance
- Vocabulary size and Kernel Encoding parameters are discussed separately in the next section of the report.
Extra Credit
Kernel Codebook Encoding
In the kernel codebook encoding, each feature vector instead of casting a hard vote to the nearest cluster center casts a weighted vote to k nearest clusters. I experimented with the value of optimal k
Optimal number of clusters in kernel codebook encoding and the dispersion effect
The following are the results of accuracy numbers with various k (bagofsift+svm) and a vocabulary size of 100.| k | Accuracy |
|---|---|
| 1 | 64.3 |
| 2 | 63.9 |
| 3 | 64.5 |
| 4 | 63.2 |
| 8 | 62.9 |
| 16 | 59.1 |
| k | Accuracy |
|---|---|
| 1 | 66.1 |
| 2 | 67.3 |
| 3 | 69.3 |
| 4 | 68.5 |
| 8 | 66.9 |
| 16 | 64.9 |
k = 3;
Y = Y(:,1:k); %Pick the first k smallest distances
I = I(:,1:k); %Pick the first k smallest distances
Y = 1./Y;
Y = exp(Y);
Y = bsxfun(@rdivide, Y, sum(Y,2)); %normalized votes
for j=1:num_features
feature_votes(j,I(j,:)) = Y(j,:);
end
hist = sum(feature_votes,1); %1*vocab_size
hist = hist./norm(hist);
Effect of vocabulary size on performance
The following are the results of accuracy numbers with various vocabulary sizes (bagofsift+svm + kernel_encoding(3)).| Vocabulary Size | Accuracy |
|---|---|
| 20 | 49.9 |
| 50 | 61.6 |
| 100 | 64.5 |
| 120 | 66.4 |
| 160 | 68.0 |
| 200 | 69.3 |
| 300 | 69.8 |
| 400 | 69.7 |
Adding spatial features via Gist descriptors
Bag of words model does not capture spatial information. Gist descriptors for an image work by partitioning the image into finer sub-regions and computing the histogram of local features found inside each sub-region. This resulting "spatial pyramid" is a simple and efficient extension to the bag of words model. We used the Gist descriptor matlab code provided on the website. The performance after adding the gist features, jumped up to 77.0%. We used a simple concatenation of vectors i.e. we concatenated the gist descriptor vector for the image with the histogram obtained by the SIFT feature vector and fed it to an SVM.Scene classification results visualization
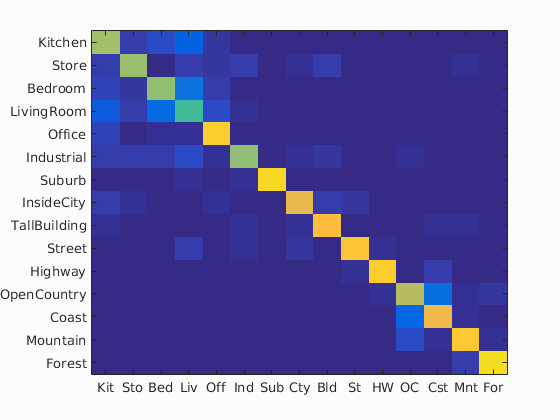
Accuracy (mean of diagonal of confusion matrix) is 0.770
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
|---|---|---|---|---|---|---|---|---|---|
| Kitchen | 0.660 |  |
 |
 |
 |
 InsideCity |
 Office |
 LivingRoom |
 Mountain |
| Store | 0.650 |  |
 |
 |
 |
 LivingRoom |
 Industrial |
 TallBuilding |
 TallBuilding |
| Bedroom | 0.630 |  |
 |
 |
 |
 LivingRoom |
 TallBuilding |
 LivingRoom |
 Store |
| LivingRoom | 0.520 |  |
 |
 |
 |
 Store |
Kitchen |
 OpenCountry |
 Street |
| Office | 0.890 |  |
 |
 |
 |
 Kitchen |
 Bedroom |
 Kitchen |
 Kitchen |
| Industrial | 0.640 |  |
 |
 |
 |
 Store |
 InsideCity |
 OpenCountry |
 TallBuilding |
| Suburb | 0.920 |  |
 |
 |
 |
 Bedroom |
 Store |
 LivingRoom |
 Store |
| InsideCity | 0.790 |  |
 |
 |
 |
 Industrial |
 TallBuilding |
 Office |
 Street |
| TallBuilding | 0.830 |  |
 |
 |
 |
 InsideCity |
 InsideCity |
Bedroom |
 OpenCountry |
| Street | 0.850 |  |
 |
 |
 |
 TallBuilding |
 Highway |
 LivingRoom |
 LivingRoom |
| Highway | 0.880 |  |
 |
 |
 |
 OpenCountry |
 Street |
 Bedroom |
 LivingRoom |
| OpenCountry | 0.690 |  |
 |
 |
 |
 Industrial |
 Coast |
 Forest |
 Forest |
| Coast | 0.810 |  |
 |
 |
 |
 InsideCity |
 OpenCountry |
 OpenCountry |
 OpenCountry |
| Mountain | 0.860 |  |
 |
 |
 |
 Forest |
 Forest |
 Coast |
 OpenCountry |
| Forest | 0.930 |  |
 |
 |
 |
 OpenCountry |
 Mountain |
 Mountain |
 Mountain |
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||