Project 4 / Scene Recognition with Bag of Words
Tiny Images + KNN
This was the weakest classifier I built, but still did about 2-3 times as good as random chance.
Effect of K
For this experiment I changed the value of K to observe the results. The nearest k neighbors simply vote for which classification to give it, and ties are broken arbitrarily.
| k=1 | k=2 | k=3 | k=4 | k=5 | k=10 | k=100 |
|---|---|---|---|---|---|---|
| 0.191 | 0.183 | 0.183 | 0.194 | 0.191 | 0.182 | 0.169 |
Increasing k too much actually lowers the accuracy, since the instances can sometimes be close to each other in euclidean distance without actually being in the same class.
Effect of Image Size
For this experiment I changed the size of the images and set k=1 for all trials. The numbers represent the width and height of the images.
| 2 | 4 | 8 | 16 | 32 |
|---|---|---|---|---|
| 0.117 | 0.197 | 0.205 | 0.191 | 0.178 |
Clearly too small or too large images lower accuracy. This makes sense intuitively since there will be a lot of "empty" space between nearest neighbors as images get larger. Conversely a lot of important data is lost when images get too small.
Bag of Words + KNN
To take it a step up from tiny images, we collect sift features for each image and do nearest neighbors with those.
Effect of K
| k=1 | k=2 | k=3 | k=4 | k=5 | k=10 | k=100 |
|---|---|---|---|---|---|---|
| 0.523 | 0.490 | 0.513 | 0.512 | 0.519 | 0.515 | 0.460 |
Just like in the tiny images case, small k values tend to do better. However the SIFT features seem to be much less noisy. Consequently there are a lot more neighbors clustered together in the same class, allowing k to become moderately large before accuracy starts suffering greatly.
Bag of Words + SVM
For the SVM classifier I experimented with different kernels as well as the effects of different spatial pyramid heights on the bag of sift features. The SVM classifier outperforms KNN since it is capable of looking at every feature and builds a robust model. Since the data is very high dimensional, SVM performs very well with just a linear kernel.
Effect of Kernel
For this experiment I used different kernels for the SVM to classify results.
| Linear | 2-poly | 3-poly | 4-poly | Gaussian/RBF |
|---|---|---|---|---|
| 0.667 | 0.668 | 0.656 | 0.623 | 0.519 |
Clearly linear is a good kernel for this problem, with increasing polynomial degrees causing overfitting and lowering accuracy on the test set. The RBF kernel is likely just not very good at separating the data in this domain.
Effect of Pyramid Height
For this experiment I implemented the spatial pyramid as described in Lazebnik et al 2006.
| 1 layer | 3 layers | 5 layers |
|---|---|---|
| 0.667 | 0.688 | 0.693 |
Increasing the number of layers in the pyramid has diminishing returns, it takes exponentially longer for SVM to run on thousands of features, so it is best to keep the height small. However it is clear that retaining some spatial information about the SIFT features is important in increasing accuracy.
Best Result
This was achieved by sampling 200 words from each image to build the vocabulary, using 3 layers in the SIFT spatial pyramid, and using a quadratic kernel for the SVM.
Some interesting observations:
- The forest false negatives seem to be mostly open country with leaf-like features in them.
- The office false positives seem to be a lot of house images with counters that might resemble office tables / bookshelves.
- Suburb, coast, highway, and forest classifiers seemed to do the best. These scenes do have lots of very distinctive features that would be frequently picked up by SIFT classifiers.
- Conversely the worst classifiers open country, bedroom, living room, store, and kitchen are very diverse scenes that would have many variations even among instances in the same class. Finding many common SIFT features would be very hard.
Scene classification results visualization
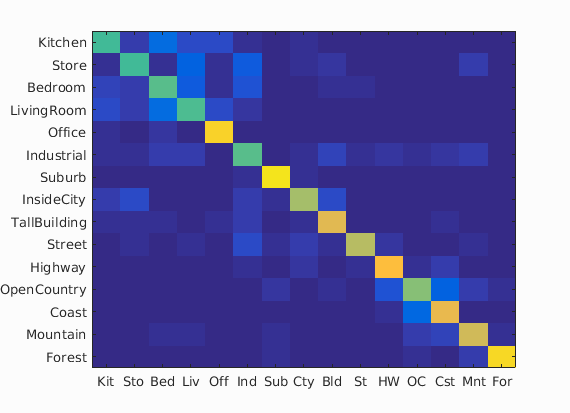
Accuracy (mean of diagonal of confusion matrix) is 0.706
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
|---|---|---|---|---|---|---|---|---|---|
| Kitchen | 0.520 |  |
 |
 |
 |
 InsideCity |
 LivingRoom |
 Office |
 LivingRoom |
| Store | 0.530 |  |
 |
 |
 |
 Bedroom |
 InsideCity |
 InsideCity |
 TallBuilding |
| Bedroom | 0.550 |  |
 |
 |
 |
 Industrial |
 LivingRoom |
 LivingRoom |
 Office |
| LivingRoom | 0.540 |  |
 |
 |
 |
 Office |
 Store |
 Kitchen |
 Kitchen |
| Office | 0.900 |  |
 |
 |
 |
 Kitchen |
 LivingRoom |
 Suburb |
 Kitchen |
| Industrial | 0.560 |  |
 |
 |
 |
 Store |
 Store |
 Store |
 Highway |
| Suburb | 0.940 |  |
 |
 |
 |
 OpenCountry |
 OpenCountry |
 Industrial |
 InsideCity |
| InsideCity | 0.670 |  |
 |
 |
 |
 Street |
 Store |
 Store |
 Kitchen |
| TallBuilding | 0.780 |  |
 |
 |
 |
 Bedroom |
 InsideCity |
 Store |
 Bedroom |
| Street | 0.700 |  |
 |
 |
 |
 Bedroom |
 InsideCity |
 Suburb |
 Industrial |
| Highway | 0.840 |  |
 |
 |
 |
 OpenCountry |
 LivingRoom |
 Coast |
 Street |
| OpenCountry | 0.620 |  |
 |
 |
 |
 Coast |
 Coast |
 Coast |
 Forest |
| Coast | 0.790 |  |
 |
 |
 |
 Suburb |
 Industrial |
 OpenCountry |
 OpenCountry |
| Mountain | 0.740 |  |
 |
 |
 |
 Store |
 Street |
 Coast |
 Office |
| Forest | 0.910 |  |
 |
 |
 |
 OpenCountry |
OpenCountry |
 Suburb |
 Suburb |
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||