Project 4 / Scene Recognition with Bag of Words
Introduction
Our task for this project was to use the bag of visual words model to classify images of scenes. I are given 15 categories, ranging from outdoor scenes to office spaces, and used a variety of methods to attempt to classify images of those locations. I used two different feature models and two different classifiers in order to solve the problem. The first feature model, tiny images, simply uses small images as the features for the classifier. The other model, bag of visual words using SIFT, is more complicated but can achieve much more accurate results. To classify our images, I first used a simple nearest-neighbor classifier and then used a linear SVM model to improve accuracy further.

Example of a tiny image of a 'bedroom' image, magnified.
Tiny Images Feature
The tiny image feature is extremely straightforward. Each image is resized so that its smaller edge is of length 16, then the image is cropped to a uniform 16x16 square. Finally, each thumbnail is normalized and stored as a 256 length vector. An example tiny image is shown to the right.
Nearest Neighbor Classifier
For this classifier, I simply compare the features from our training images with those from the test images. For each test image, I calculate the "distance" to every single test image feature, which is simply the L2 distance. To classify this image, I assign the label corresponding to the closest training image. This method is fairly fast and straightforward, but is not always accurate. This is especially due to the fact that one outlier test image can significantly affect the labeling results.
Bag of Visual Words Feature
In order to improve classification results I moved to a more sophisticated image feature representation. Using the SIFT feature descriptor, I extracted an arbitrary number of features from each of the training images. I built a vocabulary for the training data by clustering all of these features into a specified number of "visual words". This vocabulary size, which I will refer to as k, is an important parameter that has a signficant effect on classification accuracy. Later in the project I experimented with different values for this parameter.
Once I have built our vocabulary, I build histograms of these visual words for each image. First I extract the SIFT features for a given input image. I then build a histogram of the occurence for each word in our visual vocabulary using the closest vocab word for each SIFT feature. Although it is likely that I do not actually find an exact match for a visual vocab word, because I are using minimum distances I should end up with a histogram of size 200 where summing the number of occurences will equal the original number of SIFT features I extracted from the image. Finally, I normalize the histogram to account for the fact that some images may return a larger number of SIFT features. I can now use this histogram feature of size k in our classifiers.
Support Vector Machine Classifier
The final component of this project was the creation of a Support Vector Machine classifier. Unlike the nearest neighbor classifier, this approach can only perform binary classification. Therefore it is necessary to create separate SVMs for each scene category and train each as a true vs false classifer for that individual category. For the category kitchen, for example, the SVM simply categorized kitchen vs non-kitchen. For each image, I found a confidence score from each of the fifteen SVMs. I then chose the highest value (or most confident) as the label for that given image. The primary parameter here was the lambda parameter, which essentially specifies the degree to which the SVM should force correct classifications. Later in the project I experimented with different values for lambda and found an ideal value to be 0.001.
Results
Tiny Images and Nearest Neighbors
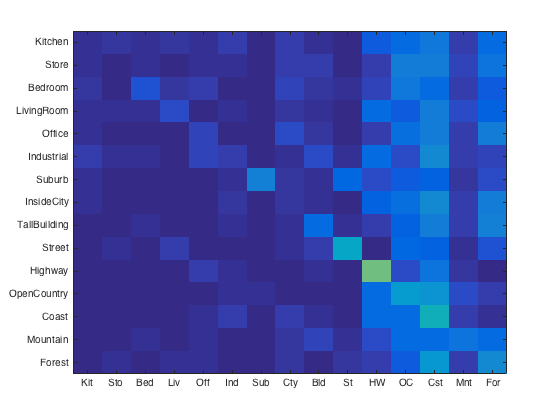
Using tiny images and the nearest neighbor classifier, I was able to achieve an accuracy of 19.8%. This pipeline seems to classify most of the images as outdoor scenes. The resized images lose a lot of detail that would be characteristic of indoor rooms and other more complicated manmade scenes. It appears that highways were most often classified correctly, which may be due to the fact that the edges of roads are distinctly visible in the tiny images. The results are shown in the confusion matrix below.
Bag of Visual Words and Nearest Neighbors
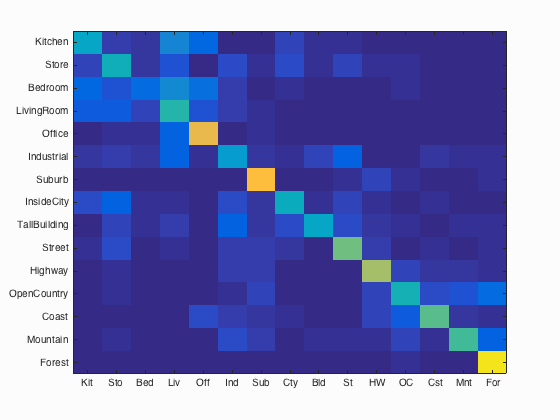
Using the Bag of Visual Words approach with the nearest neighbor classifier, I can obtain an accuracy of 52.7%. This is an improvement over the tiny images representation, because this feature stores much more detailed information about the training and test images. The categories 'office', 'suburb', and 'forest' appear to have the highest accuracies. It can be argued that 'forest' is one of the more distinct categories due to the unique shape of trees and leaves, and the 'suburb' category is likely defined by the houses that often dominate those images. It is likely that 'office' receives a high accuracy because the classifier can detect the edges of the panorama images. The confusion matrix is shown below.
Bag of Visual Words and SVM
Using the Bag of Visual Words approach with the SVM classifier, I was able to achieve an accuracy of 68.7%, which is higher than any other method used. This accuracy was achieved after hours of tuning the various parameters for this project, including vocabulary size, number of features extracted from each image (related to step size and feature size), lambda, and the number of training and testing images. For the below results, I used a vocabulary size of 1000, lambda value of 0.001, and randomly sampled 1000 SIFT features from each image. The pipeline appears to have a hard time distinguishing between the indoor house categories, namely 'bedroom', 'kitchen', and 'living room'. The results of this method are shown below.
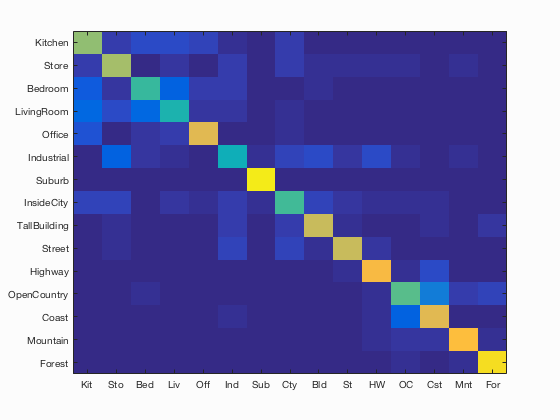
Accuracy (mean of diagonal of confusion matrix) is 0.687
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
|---|---|---|---|---|---|---|---|---|---|
| Kitchen | 0.640 |  |
 |
 |
 |
 LivingRoom |
 LivingRoom |
 Bedroom |
 Office |
| Store | 0.660 |  |
 |
 |
 |
 InsideCity |
 Industrial |
 Street |
 InsideCity |
| Bedroom | 0.510 |  |
 |
 |
 |
 Kitchen |
 LivingRoom |
 LivingRoom |
 LivingRoom |
| LivingRoom | 0.460 |  |
 |
 |
 |
 Bedroom |
 Store |
 Office |
 Bedroom |
| Office | 0.770 |  |
 |
 |
 |
 InsideCity |
 Bedroom |
 Bedroom |
 LivingRoom |
| Industrial | 0.430 |  |
 |
 |
 |
 TallBuilding |
 Bedroom |
 Highway |
 Suburb |
| Suburb | 0.960 |  |
 |
 |
 |
 InsideCity |
 Coast |
 Industrial |
 Coast |
| InsideCity | 0.520 |  |
 |
 |
 |
 Kitchen |
 Street |
 Store |
 OpenCountry |
| TallBuilding | 0.720 |  |
 |
 |
 |
 Industrial |
 Industrial |
 Forest |
 Coast |
| Street | 0.730 |  |
 |
 |
 |
 TallBuilding |
Store |
 Industrial |
 InsideCity |
| Highway | 0.820 |  |
 |
 |
 |
 Industrial |
 Coast |
 Coast |
 Street |
| OpenCountry | 0.550 |  |
 |
 |
 |
 Coast |
 Industrial |
 Coast |
 Coast |
| Coast | 0.770 |  |
 |
 |
 |
 TallBuilding |
 Kitchen |
OpenCountry |
Highway |
| Mountain | 0.840 |  |
 |
 |
 |
 OpenCountry |
 Forest |
 Forest |
 Coast |
| Forest | 0.930 |  |
 |
 |
 |
 TallBuilding |
 OpenCountry |
 Store |
 Mountain |
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
Tuning Parameters
This project involved a large number of parameters that had significant impacts on the results of the classifier. I spent most of my time focusing on three parameters: lambda, number of sift features, and vocabulary size.
Lambda
Lambda is a parameter of the support vector machines used in the classifying stage of the pipeline. Lambda specifies the degree to which the SVM can allow incorrect classifications. A very high value for lambda means the SVM will attempt to set a hard threshold between the two classes, preventing any points from falling on the wrong side of the classification. However, in many situations a valid solution cannot be found unless the SVM is relaxed enough to allow these potential incorrect classifications.
For this project, I created a plot of various lambda values while keeping all other parameters constant. I used a vocabulary size of 200, testing and training size of 10, and used 1000 SIFT features per image. The x-axis is logarithmic, so the "negative" values to the left of the 0 axis are fractional values.
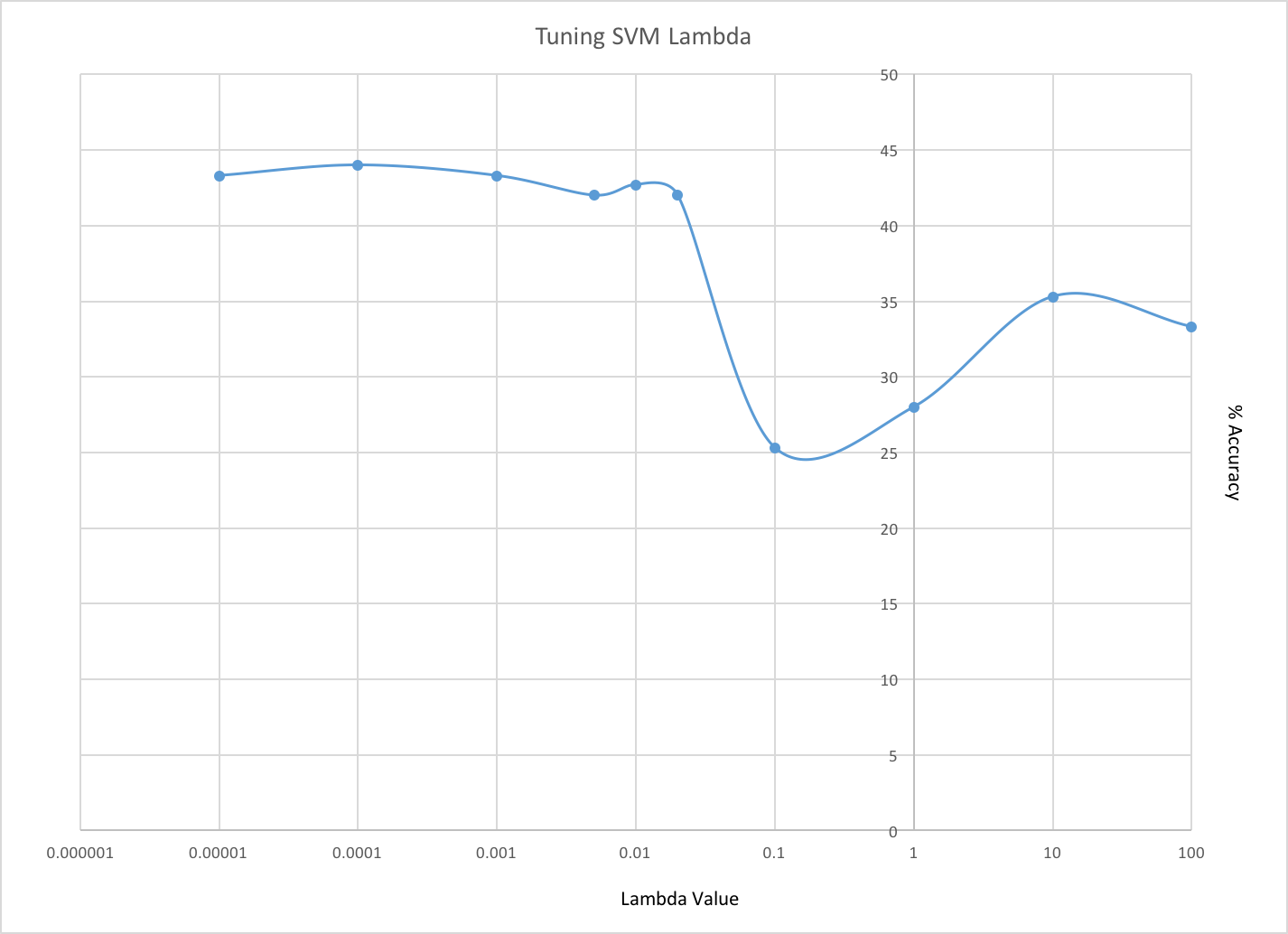
I used this process to find that the ideal value for lambda was around 0.01. A lambda value of 0.001 also gave me good results.
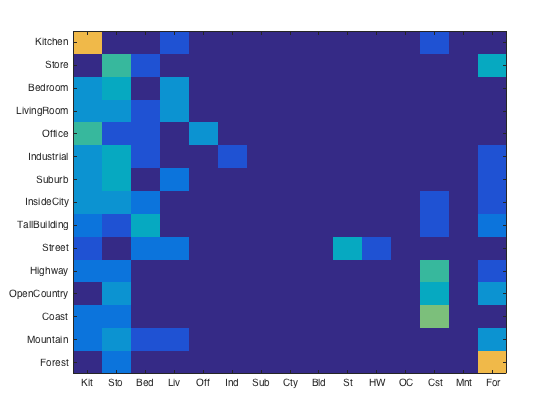
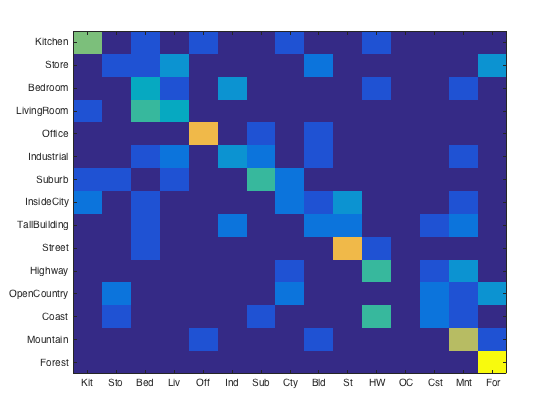
Confusion Matrices for lambda of 0.1 (left) and lambda of 0.001 (right)
Extracted Features per Image
Another parameter I experimented with was the number of SIFT features sampled from each image. I controlled this parameter by adjusting the feature size for vl_dsift, the step size, and then by randomly sampling a subset of those features. When I refer to the number of features, I am referring to the final number that was sampled from all features for a given image. As the number of features increases, the accuracy of classifications increases. However, computation time increases significantly. Because the distances between all features and the vocabulary must be calculated, doubling the number of features can quadruple this calculation which has a significant effect on total running time. I therefore had to find a good balance between high accuracy return and computation time. Several confusion matrices for different feature sizes are shown below.
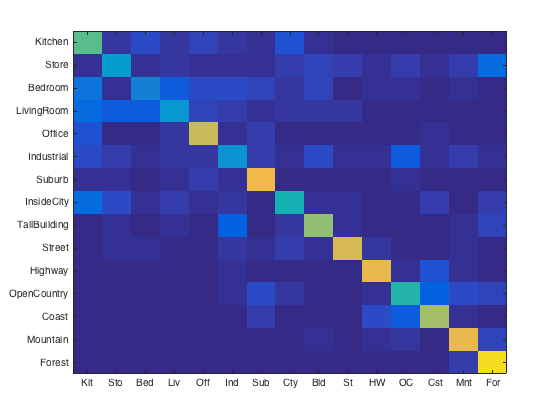
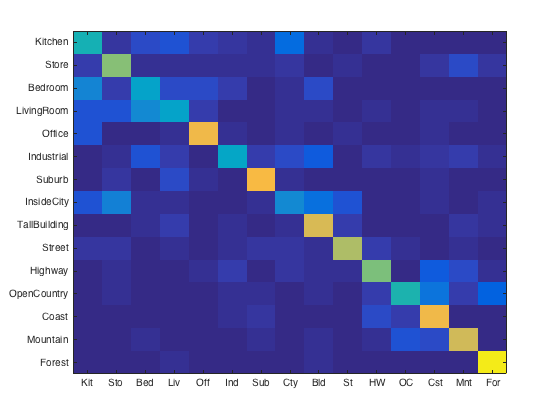
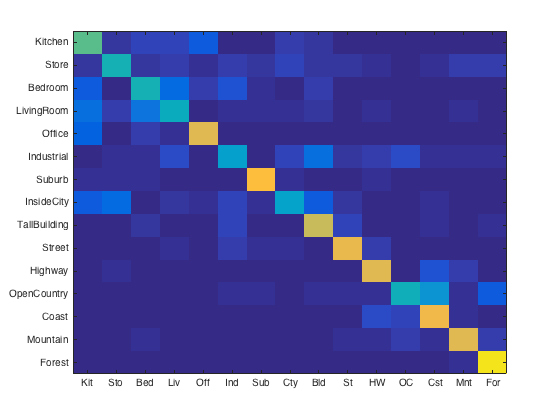
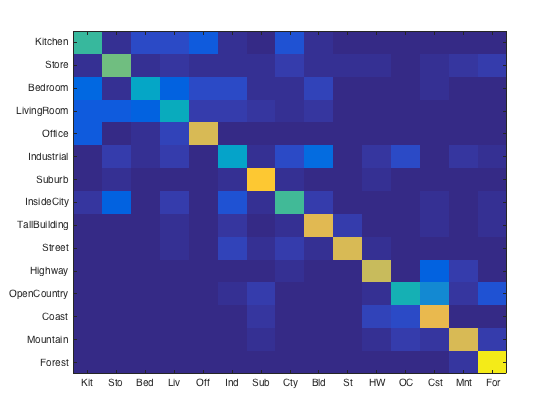
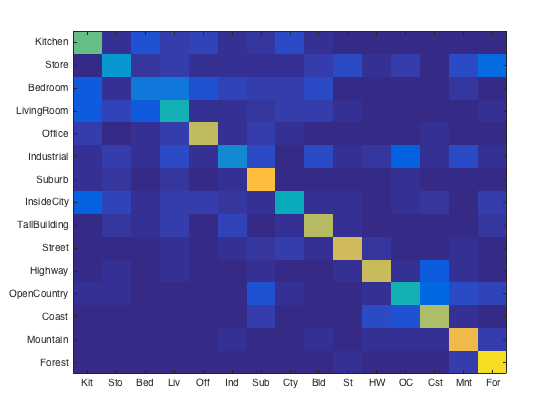
(left to right) Number of features per image: 1000, 1500, 2000, 3000, 5000
Vocabulary Size
The last parameter I tested thoroughly was the visual vocabulary size. This plays a significant role in the classification of images because it sets the size of all features in the pipeline. As expected, a larger vocabulary performed better than a smaller one, although increasing this parameter significantly increased computation time. The clustering in the k-means stage of the vocabulary building required a significant amount of time when the vocabulary was set above 200 words. During the testing of these sizes, I used a lambda value of 0.001, a training and testing size of 15, and 1000 features per image to speed testing. Although a vocabulary size of 500 was ideal, it was infeasible for testing and the slight benefit gained from the additional vocabulary did not offset the computation time. I decided to use a vocabulary of 200 for the remainder of the project.
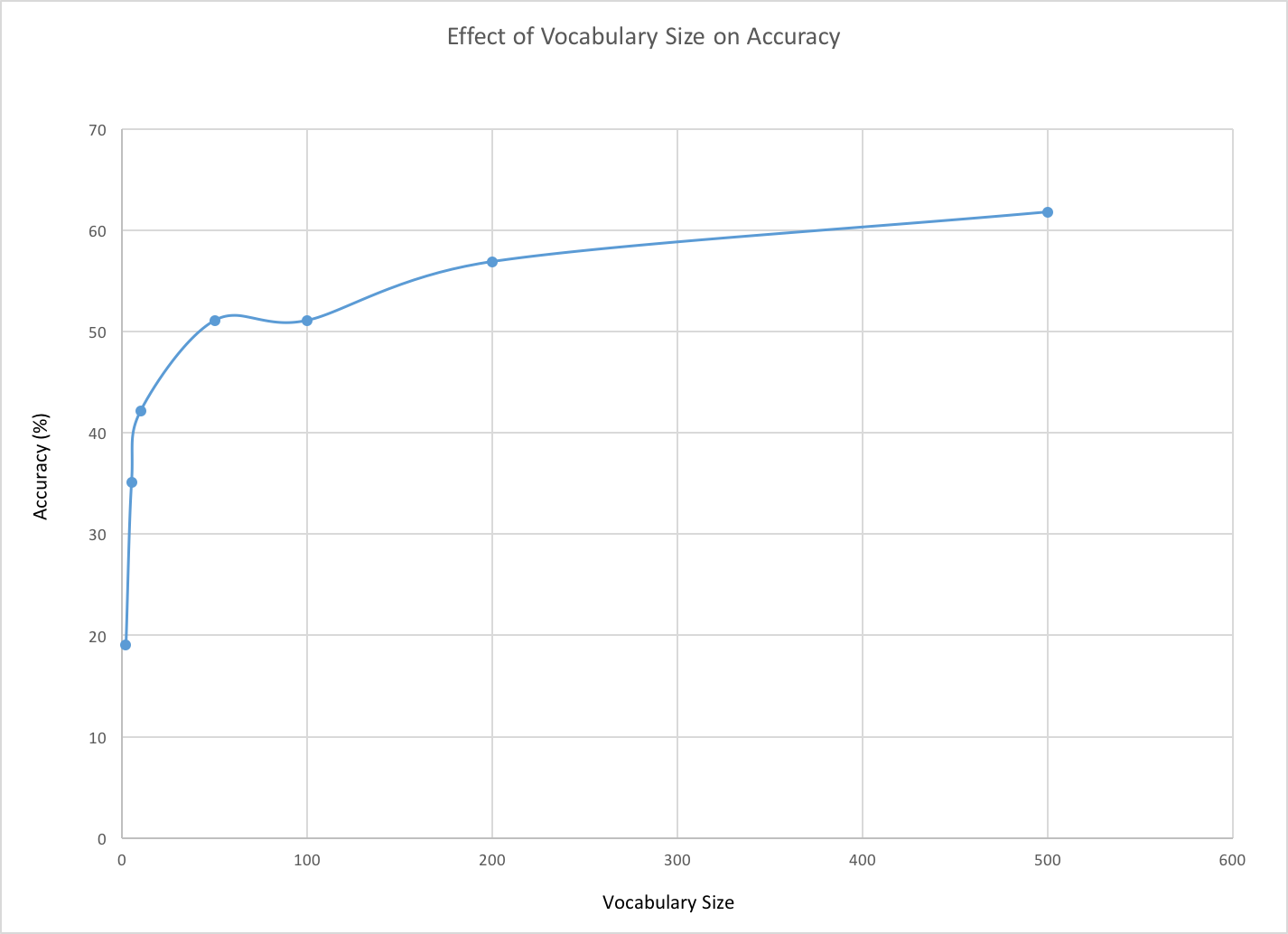
Extra Credit
The extra credit I performed is described in the above section, Tuning Parameters, where I tested numerous vocabulary sizes to find the effect that parameter had on my results.