Project 4: Scene recognition with bag of words
In this project, I need to implement the three major steps of scene recognition.
- Tiny images representation and nearest neighbor classifier
- Bag of SIFT representation and nearest neighbor classifier
- Bag of SIFT representation and linear SVM classifier
Tiny images representation and nearest neighbor classifier
I start by implementing the tiny image representation and the nearest neighbor classifier. For tiny image representation, I just need to resize each image to 16x16 resolution and reshape the tiny image to a vector having zero mean and unit length. For nearest neighbor classifier, I need to classifying a test feature into a particular category. The test feature finds the "nearest" training example and assigns the test case the label of that nearest training example.
In tiny images representation and nearest neighbor classifier, I got a 23.5% accuracy to recognition.
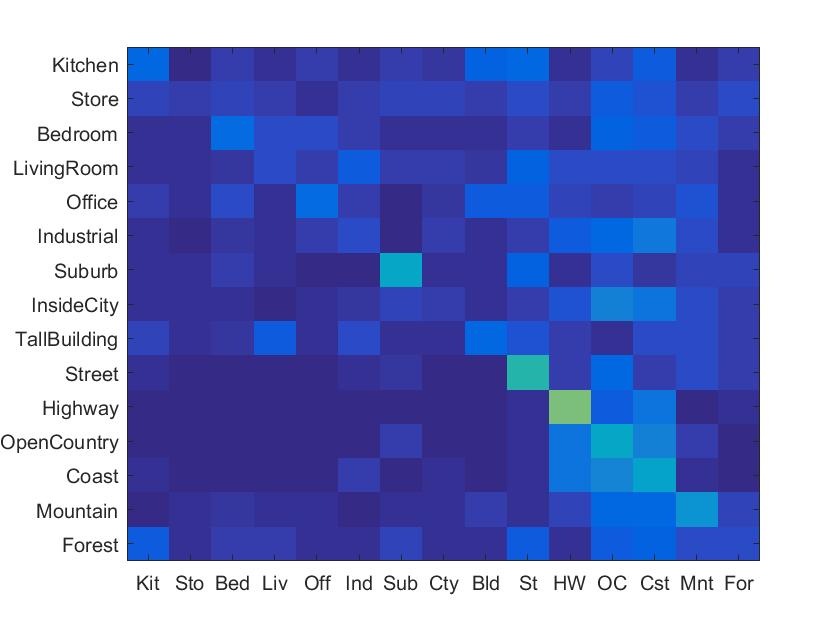

Bag of SIFT representation and nearest neighbor classifier
At first, I need to establish a vocabulary of visual words. To form this vocabulary by sampling many local features from my training set and then clustering them with kmeans. And in the second, I densely sample many SIFT descriptors. I simply count how many SIFT descriptors fall into each cluster in my visual word vocabulary by finding the nearest neighbor kmeans centroid for every SIFT feature. And then, bag of SIFT representation form a histogram with vocabulary size dimensions and features size counts. In the end, normalize the histogram. To reach the requirement of running time, I use 'fast' parameter for vl_dsift() which means it use a piecewise-flat, rather than Gaussian, windowing function that 20 times faster to compute.
In bag of SIFT representation and nearest neighbor classifier, I got a 49.0% accuracy to recognition.


Bag of SIFT representation and linear SVM classifier
In linear SVM classifier, I used it to train every category. To decide which of 15 categories a test case belongs to, I train 15 binary, 1-vs-all SVMs. 1-vs-all means that each classifier will be trained to recognize object vs non-object. And then, each test features evaluated with all SVM and I use the highest confidences to predict label.
In bag of SIFT representation and linear SVM classifier, I got a 48.5% accuracy to recognition.
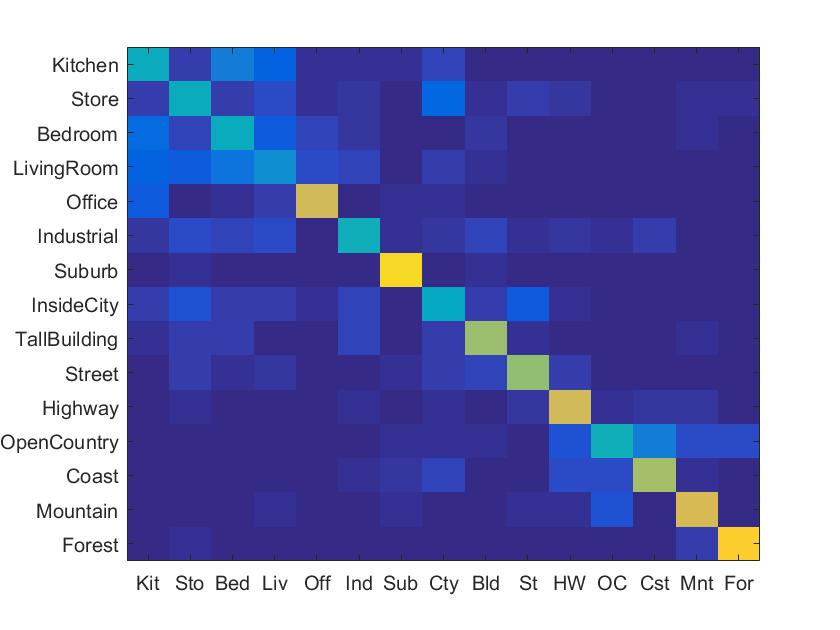

Extra credit
Gist descriptors
The procedure is based on a very low dimensional representation of the scene. It propose a set of perceptual dimensions (naturalness, openness, roughness, expansion, ruggedness) that represent the dominant spatial structure of a scene. Then, it show that these dimensions may be reliably estimated using spectral and coarsely localized information.
In gist descriptors, I got a 67.9% accuracy to recognition.
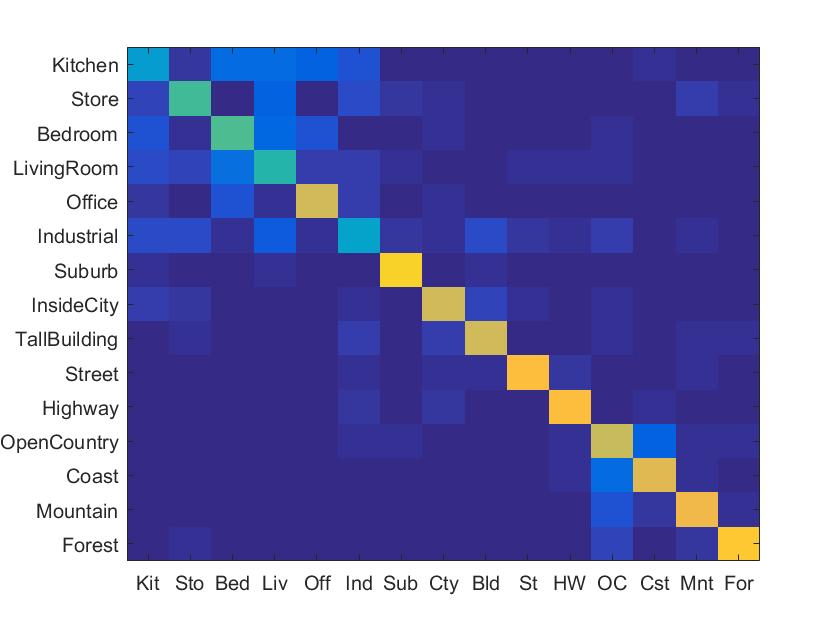

Experiment with different vocabulary sizes
To experiment with different vocabulary sizes, I used 10,20, 50, 100, 200 vocabulary sizes. I did not use 'fast' parameter for vl_dsift() to check the accuracy for recognition. I found that larger vocabulary sizes will increase the accuracy for recognition but it also increase rapidly the running time.
