Project 4 / Scene Recognition with Bag of Words
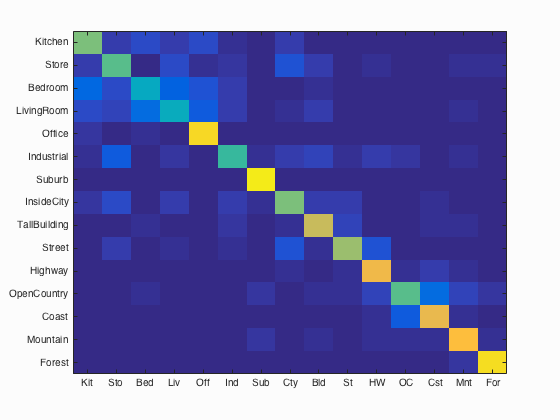
Confusion Matrix for SVM classifying Bag of Words
This project implements a Bag of Words Scene Recognition pipeline. First a feature is extracted, either by shrinking the image, or using SIFT features. Then the scene is classified using either nearest neighbor matching, or SVMs.
Tiny Images
Tiny images are constructed by shrinking the input image to a 16x16 image. This image is then reshaped into a 16*16 = 256 element vector which is used to clasify the image, using a nearest neighbor approach. This simple pipeline yields an accuracy rate of 20.1%. The confusion matrix is shown below.
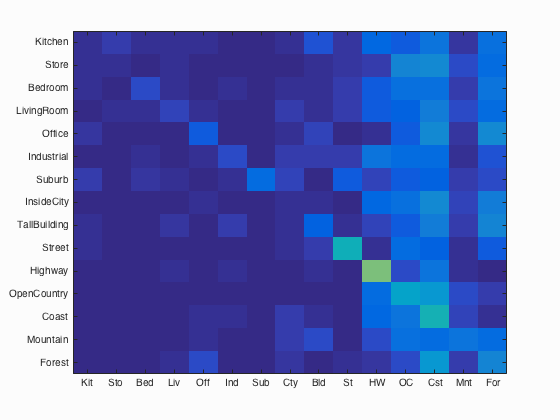
Bag of Words
To improve accuracy we turn to SIFT features and a Bag of Words approach. We start by creating a vocabulary of 200 words by sampling from the training images at 20 pixel increments. A larger stride is advantageous here, because we're trying to get a representative sample of possible features that can occur, not every possible feature. Using this vocabulary, we sample every 5 pixels over the test data, to get as many features as possible, and construct a histogram of words for the image. To speed up the execution, the submitted code uses a step size of 10 pixels, and fast SIFT features. We then use this feature vector as the input to the nearest neighbor classifier. By implementing this improvement, accuracy increases to 51.4%, nearly double the accuracy of the tiny images features. The new confusion matrix is shown below:
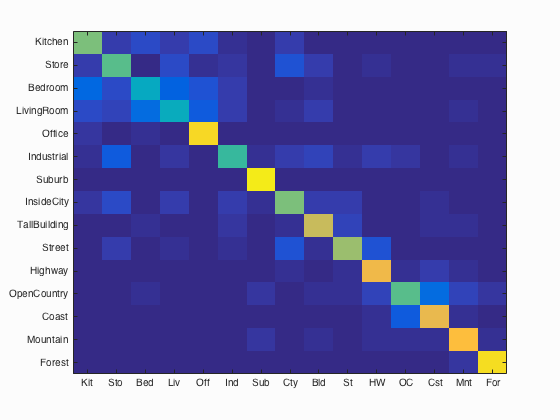
1 vs. All Linear SVM
The final improvement is to use a set of SVMs to classify the Bag of Words features, instead of a nearest-neighbor approach. Since SVMs are designed for binary classification problems, we use one SVM for each category we are trying to recongnize, and assign each example a positive label if it is part of this category, and a negative label if it is part of any other category. Whichever SVM returns the most positive result determines the category of the test image. The important free parameter in an SVM classification problem is the lambda, or the scaling factor of the feature space. By empirically adjusting lambda, the maximum accuracy was reached with a value of 0.000001. This accuracy was 68.3%. The final confusion matrix, and category breakdown are shown below:
Accuracy (mean of diagonal of confusion matrix) is 0.683
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
|---|---|---|---|---|---|---|---|---|---|
| Kitchen | 0.600 |  |
 |
 |
 |
 LivingRoom |
 InsideCity |
 LivingRoom |
 InsideCity |
| Store | 0.560 |  |
 |
 |
 |
 LivingRoom |
 Industrial |
 InsideCity |
 LivingRoom |
| Bedroom | 0.400 |  |
 |
 |
 |
 LivingRoom |
 LivingRoom |
 Office |
 Industrial |
| LivingRoom | 0.410 |  |
 |
 |
 |
 InsideCity |
 TallBuilding |
 Suburb |
 TallBuilding |
| Office | 0.920 |  |
 |
 |
 |
 Kitchen |
 LivingRoom |
 Kitchen |
 Bedroom |
| Industrial | 0.510 |  |
 |
 |
 |
 Kitchen |
 Highway |
Office |
 TallBuilding |
| Suburb | 0.960 |  |
 |
 |
 |
 Highway |
 Mountain |
 InsideCity |
 TallBuilding |
| InsideCity | 0.600 |  |
 |
 |
 |
 Store |
 Street |
 Industrial |
 TallBuilding |
| TallBuilding | 0.730 |  |
 |
 |
 |
 Store |
 Industrial |
 Coast |
 Forest |
| Street | 0.650 |  |
 |
 |
 |
 InsideCity |
 Industrial |
 LivingRoom |
 TallBuilding |
| Highway | 0.810 |  |
 |
 |
 |
 Industrial |
 Street |
 Coast |
 Coast |
| OpenCountry | 0.550 |  |
 |
 |
 |
 Industrial |
 Highway |
 Highway |
 Coast |
| Coast | 0.790 |  |
 |
 |
 |
 OpenCountry |
 OpenCountry |
 InsideCity |
 OpenCountry |
| Mountain | 0.830 |  |
 |
 |
 |
 LivingRoom |
 TallBuilding |
 Forest |
 Highway |
| Forest | 0.930 |  |
 |
 |
 |
 Store |
 Mountain |
 Mountain |
 Mountain |
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
Examining the confusion matrix above in more detail yields some interesting insights. The lighter areas of the confusion matrix in the upper left corner show there is significant confusion between Kitchens, Stores, Bedrooms and Living Rooms. This makes sense because all of these scenes appear similar, even to an experienced human. Office performs significantly better, and experiences little confusion because the images are panoramas, and it is likely that the SIFT features are detecting the barrel distortion and seams in the image stitching.
Other areas of confusion are between OpenCountry and Coast, as well as InsideCity, TallBuilding and Street, all for similar reasons as those mentioned above