Project 4 / Scene Recognition with Bag of Words
The goal of this project is to perform scene recognition with several simple methods, then moving on to more advanced methods. We begin with the simplest implmenetation of using tiny images as a representation and nearest neighbor classifier.
Tiny images representation and nearest neighbor classifier
For the tiny images representation I took the center square of each image and resized it to 16x16. I used a nearest neighbor classifier with K=10. The mean diagonal of the confusion matrix was 0.191.
Bag of Sift representation and nearest neighbor classifier
Next I created the Bag of Sift representation to use with the nearest neighbor classifier. To build the vocabulary for the bag of SIFT method, I used the 'fast' method along with 1000 randomly selected features from each image, and a step size of 10. I used a vocabulary size of 50. When creating the bag of sifts for each image I again used a stepsize of 5 and the 'fast' method, along with 2000 randomly selected features. Other parameters were the same as the previous section. Run time (excluding building the vocabulary) was about 2min and the mean diagonal of the confusion matrix was 0.51.
Bag of Sift representation and linear SVM
Using the same parameters for the Bag of Sift representation, I changed the nearest neighbor classifier to a linear SVM. I used the vl_svmtrain() package. I found good performance with a Lambda value of 1.0e-6. Other parameters were the same as the previous section. The mean diagonal of the confusion matrix was 0.583.
EXTRA: Bag of Sift and kernel SVM
Next I used a kernel SVM instead of the linear SVM. I used MATLAB's svmtrain package for this. I found that a polynomial kernel with polynomial order of the vocabulary size worked well. Other parameters were the same as the previous section. The mean diagonal of the confusion matrix was 0.632.
EXTRA: "Soft assignment" of Bag of Sift and kernel SVM
I next implemented the "soft assignment" method for Bag of SIFT found in Kernel codebooks for scene categorization by Gemert et al, ECCV 2008. They outline 4 different kernel-based assignment methods, the best one being "codeword uncertainty" weights, which are defined as taking the gaussian kernel of the distances between the features and the codewords, and normalizing them to sum to 1. Each feature then contributes to every codeword a weighted contribution. I used a sigma value for the gaussian kernel of 3.0e4. Other parameters were the same as the previous section. The mean diagonal of the confusion matrix was 0.635.
EXTRA: Comparison of Vocabulary Sizes
Using the same pipeline with the same parameters found in the previous section, I tested the performance on different vocabulary sizes. The mean diagonal of the confusion matrices are shown in the table below. I did however change the polynomial order for the kernel SVM because it would overfit with high polynomial orders on low vocabulary sizes. I used the same polynomial order as the vocabulary size, except for 400 and 1000, where I used a polynomial kernel of order 200.
| Vocab Size | Score |
| 10 | .445 |
| 20 | .553 |
| 50 | .625 |
| 100 | .669 |
| 200 | .689 |
| 400 | .701 |
| 1000 | .689 |
Final Result
The full details of the best result I was able to achieve is shown below. I used all the same parameters as the previous section, with a vocabulary size of 400.
Scene classification results visualization
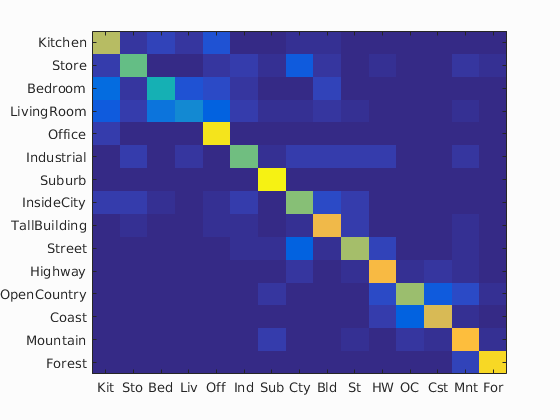
Accuracy (mean of diagonal of confusion matrix) is 0.702
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
|---|---|---|---|---|---|---|---|---|---|
| Kitchen | 0.690 |  |
 |
 |
 |
 LivingRoom |
 Bedroom |
 Store |
 Office |
| Store | 0.570 |  |
 |
 |
 LivingRoom |
 LivingRoom |
 Kitchen |
 Highway |
|
| Bedroom | 0.450 |  |
 |
 |
 |
 InsideCity |
 LivingRoom |
 TallBuilding |
 Store |
| LivingRoom | 0.280 |  |
 |
 |
 |
 Bedroom |
 Bedroom |
 Office |
 Bedroom |
| Office | 0.940 |  |
 |
 |
 |
 TallBuilding |
 LivingRoom |
 Kitchen |
 Kitchen |
| Industrial | 0.580 |  |
 |
 |
 |
 TallBuilding |
 Street |
 Street |
 InsideCity |
| Suburb | 0.970 |  |
 |
 |
 |
 Industrial |
 OpenCountry |
 Store |
 Street |
| InsideCity | 0.610 |  |
 |
 |
 |
 Store |
 Street |
 TallBuilding |
 TallBuilding |
| TallBuilding | 0.810 |  |
 |
 |
 |
 LivingRoom |
 InsideCity |
 Street |
 Store |
| Street | 0.670 |  |
 |
 |
 |
 Coast |
 TallBuilding |
 Highway |
 InsideCity |
| Highway | 0.820 |  |
 |
 |
 |
 Industrial |
 Street |
 Coast |
 InsideCity |
| OpenCountry | 0.650 |  |
 |
 |
 |
 Highway |
 Highway |
 Mountain |
 Coast |
| Coast | 0.750 |  |
 |
 |
 |
Highway |
 OpenCountry |
 OpenCountry |
 OpenCountry |
| Mountain | 0.830 |  |
 |
 |
 |
 Forest |
 Store |
 Coast |
 Suburb |
| Forest | 0.910 |  |
 |
 |
 |
 Mountain |
 TallBuilding |
 OpenCountry |
 Street |
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||