Project 4 / Scene Recognition with Bag of Words
The objective of this project was to implement multiple techniques to enable image recognition based on given sets of training images. The task was to place given test images in one of the 15 categories of scenes, which consists of: office, kitchen, living room, bedroom, store, industrial, tall building, inside city, street, highway, coast, open country, mountain, forest, and suburb. Two techniques for feature recognition and two for classifiers were used for scene recognition. The pairs for recognition used for this project is listed below:
- Tiny image representation and nearest neighbor classifier.
- Bag of SIFT representation and nearest neighbor classifier.
- Bag of SIFT representation and linear SVM classifier.
The graduate credits attempted for this project were (a) experimenting features with multiple scales via using the Gaussian Pyramid and (b) adding gist descriptors proposed by A. Oliva for the classifier to consider both gist and SIFT.
Part I. Tiny image representation and nearest neighbor classifier
Tiny images of the test and the train data were achieved by first using the imresize function to resize the image to 16x16 pixel tiny image. Then, for better performance, the mean of the resized image was subtracted and then was normalized by implementing the lines:
% A is the image matrix
A = double(A) - ones(16) .* mean(A(:));
A = A./max(abs(A(:)));
Then, the converted test data were classified by one-nearest neighbor classifier by comparing the distance of the test data to each of the train data. The distance from the test to each of the train data were taken by the vl_alldist2 function, and the index of the minimum distance was stored, and the label of the train data corresponding to the index was given to that particular test data. The result of using tiny image and nn-classifier is shown below.
Tiny image + nearest neighbor visualization
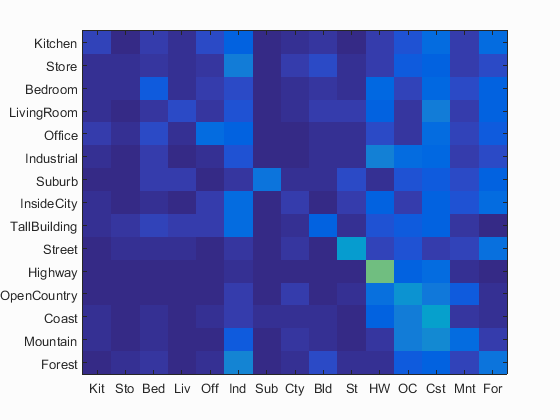
Accuracy (mean of diagonal of confusion matrix) is 0.193
The accuracy of the result agree with the expected ~20% accuracy with the 1-NN classifier instead of K-NN classifier.
Part II. Bag of SIFT representation and nearest neighbor classifier
Instead of using direct image comparision, a bag of words technique was used by extracting tens of thousands of features using SIFT from the training images to form an image index. The features were then clustered by K-mean clustering with the vl_kmeans(X,K) function, where X is the sampled SIFT features and K is the number of cluster (or the size of the vocabulary pool = 200). Then the features from the test images were extracted and compared with the bag of features generated from the training image. Finally, the counts of the indices taken from the closest matching features were taken to form a histogram, which would be later classified by the 1-NN classifier in this case. The result of using SIFT and nn-classifier is shown below.
Bag of SIFT + nearest neighbor visualization
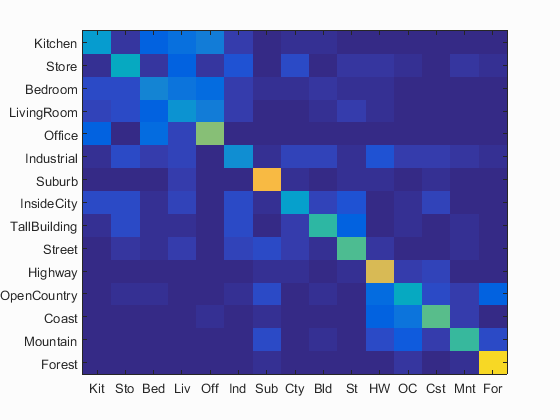
Accuracy (mean of diagonal of confusion matrix) is 0.503
The accuracy of the result agree with the expected ~50% accuracy for SIFT plus 1-NN classifier instead of K-NN classifier.
Part III. Bag of SIFT representation and linear SVM classifier
Using the same method for extracting features of the train and test images, a different classifier, the SVM classifier, was used to label data points. To formulate the SVM classifier, there was a need to train the computer by feeding training images with the corresponding labels, which was accomplished by the [W B] = vl_svmtrain(features, labels, LAMBDA) where labels is the binary label of matching images, lambda is the regularization parameter of the classifier. This function generates parameters, W and B, of the hyperplane that shows the linear decision boundary between clusters. W and B were generated for each scene, then, for each label, the 1-vs-all scoring was implemented for the test images by implementing the line, sc(i,j) = dot(W,test_image_feats(j,:)) + B. Then, the most positive score and the corresponding indices were taken for each test case and was given the corresponding label. The result of using SIFT and SVM classifier is shown below.
Bag of SIFT + SVM classifier visualization
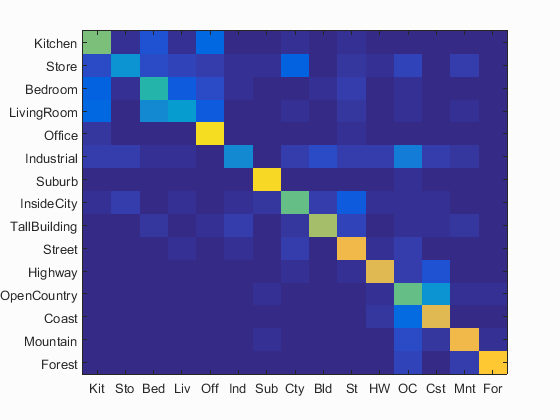
Accuracy (mean of diagonal of confusion matrix) is 0.643
The accuracy of the result agree with the expected > 60% accuracy for SIFT plus SVM classifier.
Graduate Credit: Introducing Features with multiple scales
To evaluate the performance of the SIFT + SVM scene recognition, features with multiple scales was introduced as the test images to see how sufficient the training images are to incorporate scaling into effect. In the get_bags_of_sifts function, the image acquired from the input was reduced in scale by the impyramid function, where each line of the impyramid reduces the image scale by a level in the Gaussian pyramid. The effects of reducing the image level by 1~3 levels were evaluated, and the results can be seen below.
Bag of SIFT + SVM classifier visualization with reduced scale by 1 level
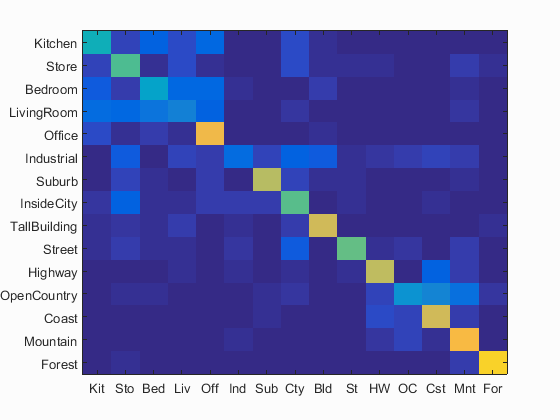
Accuracy (mean of diagonal of confusion matrix) is 0.572
Bag of SIFT + SVM classifier visualization with reduced scale by 2 levels
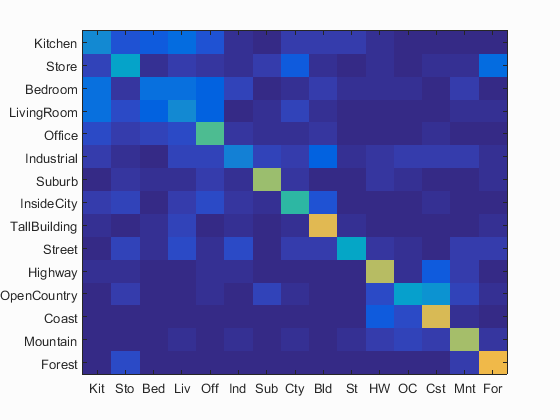
Accuracy (mean of diagonal of confusion matrix) is 0.497
Bag of SIFT + SVM classifier visualization with reduced scale by 3 levels
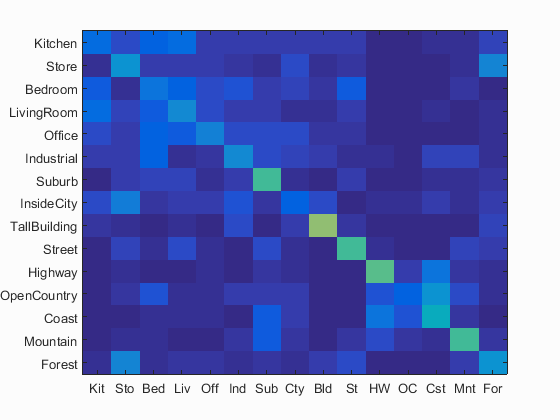
Accuracy (mean of diagonal of confusion matrix) is 0.345
For the each of the scale reduction cases, it can be seen that reduction of 1 level results in 11% reduction in accuracy, 22.7% reduction for 2 levels, and 46.3% reduction for 3 levels. A feature scaling by 1 level would perform equivalent to using SIFT with the nearest-neighbor classifier, and feature scaling by 2 level would perform just barely better than using tiny image comparson with the nearest-neighbor classifier. In order for the recognition to be more robust to scaling, there is a need to provide a bigger pool of training images with multiple scaling factors.
Graduate Credit: Adding gist descriptors to the data for the classifier
In addition to the SIFT descriptors, the gist descriptors as suggested by A. Oliva was taken into account to see if the classifier performed better with additional information. For building the index of vocabulary, the LMgist function provided by A. Oliva, 2001 was used to extract the gist descriptors for each of the training images. Then, for generating the bag of words, the gist descriptor was extracted from each test image, distance from the features from the training image was obtained, and the index for the minimum distance was found. This itself would be a 1-nearest neighbor classifier, but this classification was added to the histogram of indices with SIFT with a 50% weight to the same corresponding index in the histogram: N(ind2) = (N(ind2)+1)/2 where N is the histogram count value (max of 1) and 1 would be given to that corresponding index, which would be averaged to give a new weighted value. The result of using gist and SIFT is shown below.
Bag of sift & gist features + svm classifier visualization
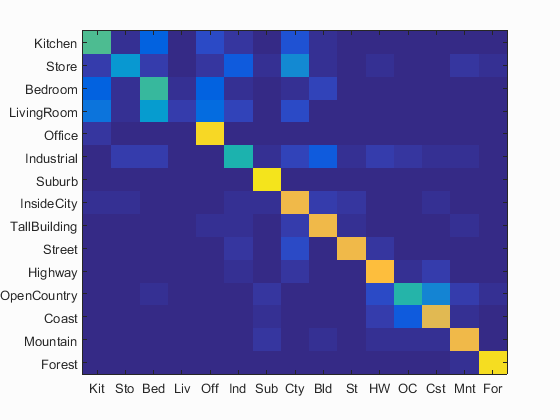
Accuracy (mean of diagonal of confusion matrix) is 0.666
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
|---|---|---|---|---|---|---|---|---|---|
| Kitchen | 0.540 |  |
 |
 |
 |
 LivingRoom |
 LivingRoom |
 Office |
 Industrial |
| Store | 0.320 |  |
 |
 |
 |
 Suburb |
 Kitchen |
 Industrial |
 Kitchen |
| Bedroom | 0.510 |  |
 |
 |
 |
 LivingRoom |
 LivingRoom |
 Office |
 Coast |
| LivingRoom | 0.060 |  |
 |
 |
 |
 Bedroom |
 Kitchen |
 Kitchen |
 Bedroom |
| Office | 0.920 |  |
 |
 |
 |
 Kitchen |
 Bedroom |
 Kitchen |
 Kitchen |
| Industrial | 0.460 |  |
 |
 |
 |
 LivingRoom |
 LivingRoom |
 Suburb |
 Highway |
| Suburb | 0.950 |  |
 |
 |
 |
 Kitchen |
 InsideCity |
Store |
 InsideCity |
| InsideCity | 0.800 |  |
 |
 |
 |
 Store |
 Store |
 Store |
 Store |
| TallBuilding | 0.810 |  |
 |
 |
 |
 InsideCity |
 Industrial |
 OpenCountry |
 Office |
| Street | 0.800 |  |
 |
 |
 |
 InsideCity |
 Industrial |
 Industrial |
 InsideCity |
| Highway | 0.840 |  |
 |
 |
 |
 Coast |
 OpenCountry |
 InsideCity |
 Coast |
| OpenCountry | 0.480 |  |
 |
 |
 |
 Coast |
 Highway |
 Suburb |
 Coast |
| Coast | 0.770 |  |
 |
 |
 |
 Highway |
 OpenCountry |
 OpenCountry |
 Highway |
| Mountain | 0.800 |  |
 |
 |
 |
 Kitchen |
 TallBuilding |
 OpenCountry |
 Suburb |
| Forest | 0.930 |  |
 |
 |
 |
 OpenCountry |
 Store |
 TallBuilding |
 Mountain |
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
The resulting 66.6% accuracy was the best value that was able to be achieved from all the methods of scene recognition (improvement of 2.3% accuracy), which while it is not a significant improvement, it does prove a point that gist descriptors contribute to better performance of scene recognition.