Project 4 / Scene Recognition with Bag of Words
For this project, the goal was to recognize scenes in a group of images using two different image representations, tiny images and bag of words, using two different classifiers, Nearest Neighbors and linear SVM. The project examined scene recognition in three parts, each more complex (and more accurate) than the last.
- Tiny images and Nearest Neighbors
- Bag of Words and Nearest Neighbors
- Bag of Words and Linear SVM
Tiny Images and Nearest Neighbors
This first part started with resizing each image to a 16x16 image. This smaller image was then normalized to have zero mean and variance equal to one (unit length). To classify the images, this part applied the Nearest Neighbors algorithm to predict the categories of the images. I implemented a very simple version of Nearest Neighbors, taking only the closest neighbor.
Scene classification results using Tiny Images and Nearest Neighbors

Accuracy (mean of diagonal of confusion matrix) is 0.207
Bag of Words and Nearest Neighbors
The Bag of Words form of image representation begins with building a visual word vocabulary from the images. This vocabulary was built by pulling SIFT feature descriptors from the images, creating a larege matrix of features for all the images. The matrix of features was then broken up into clusters using K-Means, and each cluster center being a visual word for the Bag of Words representation. Once the vocabulary of visual words was built, the actual SIFT Bag had to be constructed. I ran vl_dsift over each image to get the local SIFT features, then used VL_alldist2 to find the index of the features closest to the visual words. I used a smaller step size for the bag of words to try and increase the accuracy. The feature representation was then built from the histogram of the indices of the nearest features to the vocab words.
Scene classification results Bag of Words and Nearest Neighbors
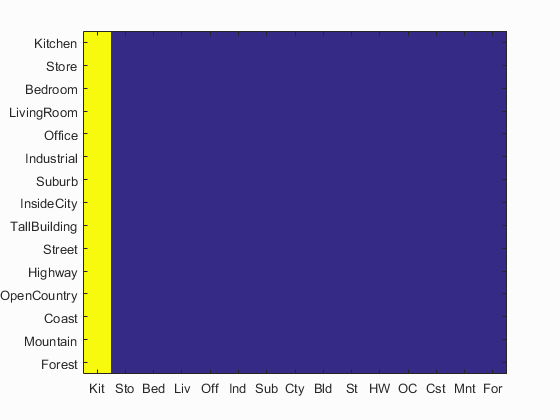
Accuracy (mean of diagonal of confusion matrix) is 0.067
Bag of Words and SVM Classifier
Since the SVM classifier used in the starter code is a binary classifier, the categories had to be individually classified in a One vs All style to categorize the images. Each category in the training labels were compared to the current training category. Matches were marked as +1, and all others as -1. Then the classifier was trained using vl_svmtrain with a Lambda value of .0001. The weight vector and the bias of each round of training was collected and then used to calculate the confidence level of each category against the test features. Only the highest confidence values were kept, and those were passed on as the visual words to find the Bag of SIFT features. Something is broken in my bag of words so my results are terrible for here on.
Scene classification results Bag of Words and SVM
