Project 4 / Scene Recognition with Bag of Words
The goal of this project is to become familiar with image recognition. For this purpose, we will work on scene recognition using three different methods:
- Tiny images representation and nearest neighbor classifier
- Bag of SIFT representation and nearest neighbor classifier
- Bag of SIFT representation and linear SVM classifier
Let's discuss the parameters and results obtained with each of them.
1. Tiny images representation and nearest neighbor classifier
In this first part of the project, the image representation is quite simple. We will just take any input image and resize it to a fixed and small resolution. We decided this resolution to be 16x16 as recommended in the project website. Once the output image is created, we will use a knn classifier to assign labels to each image. This parameter k seemed more interesting to play with. Here are some of the experiments run and accuracies obtained:

Figure 1. Accuracy for different values of k using tiny images representation.

Table 1. Accuracy for different values of k using tiny images representation.
As we can see from both the graph and the table, the best accuracy is reached when k = 11, accuracy = 23.4%. If our k is too small, we might be biasing our model by just taking into account too few neighbors, while on the contrary, if k is too high then we might be considering too much irrelevant information.
2. Bag of SIFT representation and nearest neighbor classifier
For the second part of the project, we applied SIFT representation instead of tiny images. We used vl_dsift function from vl_feat package to obtain these SIFT descriptors.
The results obtained were much higher than the ones from the previous section. We were able to obtain an accuracy of 52.3%, with the following configuration:
- Vocabulary size = 200, step size = 8
- Bag of sifts, step size = 4
- k = 5
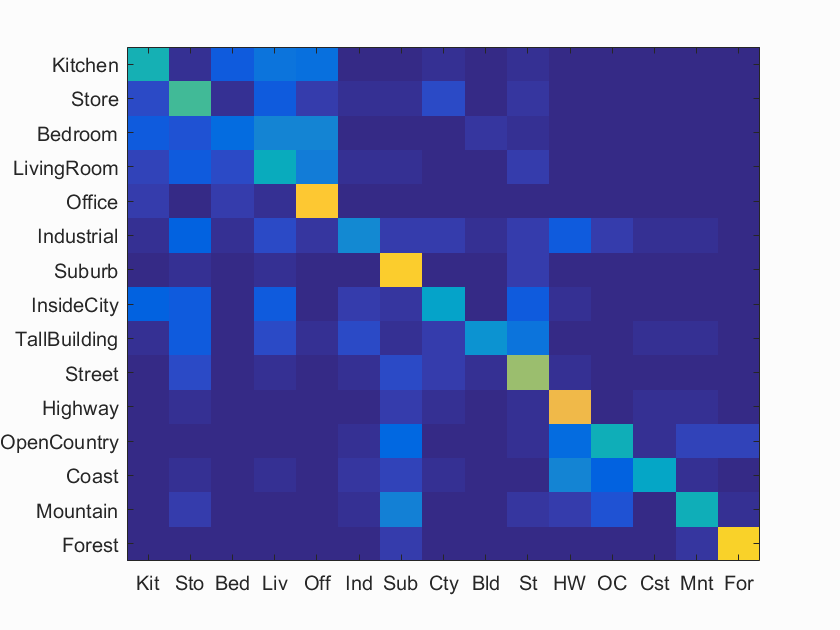
Figure 2. Confusion matrix, bag of SIFTs with knn (k=5).
Some other values of k we experimented with are the following ones:

Table 2. Accuracy for different values of k using bag of sifts representation.
As well as in section 1, we can see how accuracy can be improved by increasing k from k = 1 to a certain point (k= ~20), where accuracy will start to drop. As the number of nearest neighbors increases, the model will consider a higher number of samples, which increases the risk of taking into account samples that are too far and irrelevant to our test input.
3. Bag of SIFT representation and linear SVM classifier
For this section we used the same parameters as above(vocabulary size = 200, step = 8, bag of sifts step size = 4), and experimented with the different values of lambda. The results obtained are as follows:
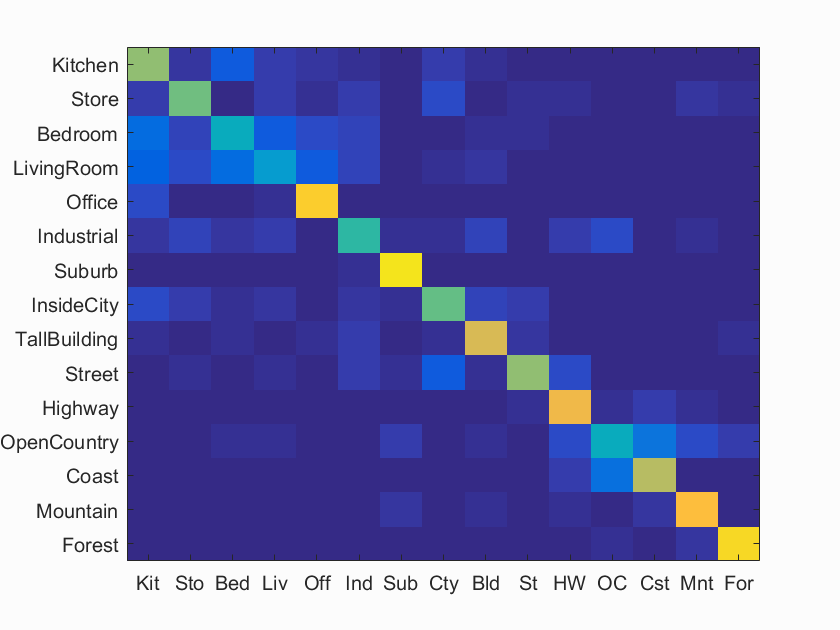
Figure 3. Confusion matrix, bag of SIFTs with SVM (lambda = 0.000001).

Table 3. Accuracy for different values of lambda using bag of sifts representation.
As we can see, the best result is obtained with lambda = 0.000001, with an accuracy of 67.1%. In this way, by using SVM instead nearest neighbors classifier we were able to increase our accuracy in more than 15%.
4. Extra credit
In this last section, we will be showing some other experiments and improvements implemented during this project.
a. Experimenting with different vocabulary sizes
First, we start experimenting with different sizes of vocabulary to see the impact that this could have on performance. In this way, we maintained fixed all the parameters from the previous section (vocab_size= 200, step_size = 8; bag of sifts - step_size = 4, lambda = 0.000001), except for vocabulary size. The results were as follows:

Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.
The table includes accuracies obtained for each value of vocabulary size, as well as the time (in seconds) required to (1) build the model, and (2) create the bag of sifts and run SVM. As we can observe, increasing the vocabulary size increases performance to a point, when the vocabulary becomes too extensive. Specifically this happens for us when vocab_size = 1000, at this point accuracy starts to drop. Regarding running times, we can observe how as the vocabulary size increases running time increases as well.
For the next experiments I decided to change the configuration to one that would run in less time, in order to facilitate running multiple experiments. The parameters are as follows:
- Vocabulary size = 100, step size = 10
- Bag of sifts, step size = 8
Accuracies without any extra credit implementation were:

Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.
b. Gist descriptor
The first improvement we implemented was to include gist to our features descriptors. For that purpose we used the code provided by Aude Oliva and Antonio Torralba.
As our first approach, we just appended 512 gist features to our original features descriptors (histograms), obtaining as a result a vector of size 612 = 100 (vocabulary size) + 512 (gist). This simple step increased our performance notably, from 58.9% to 70%.

Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.
This approach seemed to be giving much more weight to gist features since they represent more than 80% of the features vector (512/612). In order to balance the importance of each descriptor, we decided to multiply histograms by a scale. In particular, we decided this scale to be 10. With this change we were able to reach 71.5%. The results in detail were:

Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.
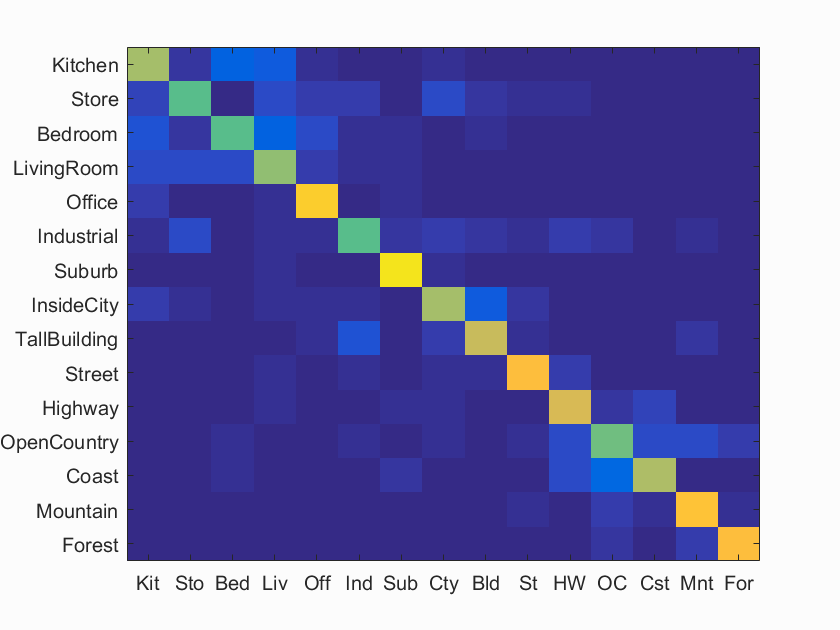
Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.
c. Spatial pyramid
Next, we decided to work with the spatial pyramid representation. We implemented the multiscale pyramid in two different ways, which returns us different performance values.
First, we decided to compute sift descriptors only once, and then create levels 1 and 2 of the pyramid by assigning each descriptor to their corresponding region of the image using their center locations. However the results obtained had barely no impact on the results. For lambda = 0.0001 we were able to increase accuracy by 4%, but for other values of sigma, accuracy actually dropped:
Using level 0 and level 1 of the pyramid:

Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.
Using level 0 to level 2 of the pyramid:

Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.
Since this approach did not improve performance, we decided to create the spatial pyramid by computing sift descriptor for each region of the image (instead of running sift descriptors only one time and assigning them to each region). By doing this, we were able to increase by almost 5% our accuracy from our base model, using two layers, level 0 and level 1. Surprisingly even though adding a third layer improved performance comparing it to the base case, the improvement was 2% less than using only two layers. Here are the results:

Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.

Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.
d. Features at multiple scales
Another feature representation that we implemented was a representation that will include histograms for differente scales of the image, in such a way that the final representation will be composed by the histograms of the original image followed by the histograms of the scaled images. We experimented with different number of scales, with a downsampling factor of 0.9.
4 scales (orginal + 3 scaled images)

Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.
As can be seen from the table, this representation increased our performance 3% up to 61.9%. Nevertheless, we thought that performance could be increased by adding more levels of scaled images, since with this initial approach our smallest image was still of size 0.73*size original image.
7 scales (orginal + 6 scaled images)

Table 4. Accuracy for different values of vocabulary size using bag of sifts representation.
By increasing the number of scaled images up to 7, we reached an accuracy of 64.3%. An improvement of 2.4% with regard to using only 4 scaled images.
e. Cross validation
Finally, we used cross-validation to measure performance. To do so, we extracted paths and labels from both train and test folders, put them together and randomly rearrange their order. Next, we split them again into train (first 100) and test(last 100) sets, and used the new sets of samples to train and test our model. We did this 5 times, and measured perfomances in terms of the average of the 5 accuracies obtained, and its standard deviation.
Results obtained with our base case model were: 0.5860, 0.5887, 0.5800, 0.5873, 0.5987, being the standard deviation: 0.0068 and mean: 0.5881. As we can see, values were consistent with the different train and test sets.
5. Best model
Our best model was reached with:
- Vocabulary size = 200, step size = 10
- Bag of sifts, step size = 4
- Lambda = 0.0001
- Gist = true, gist mult factor = 10
Scene classification results visualization
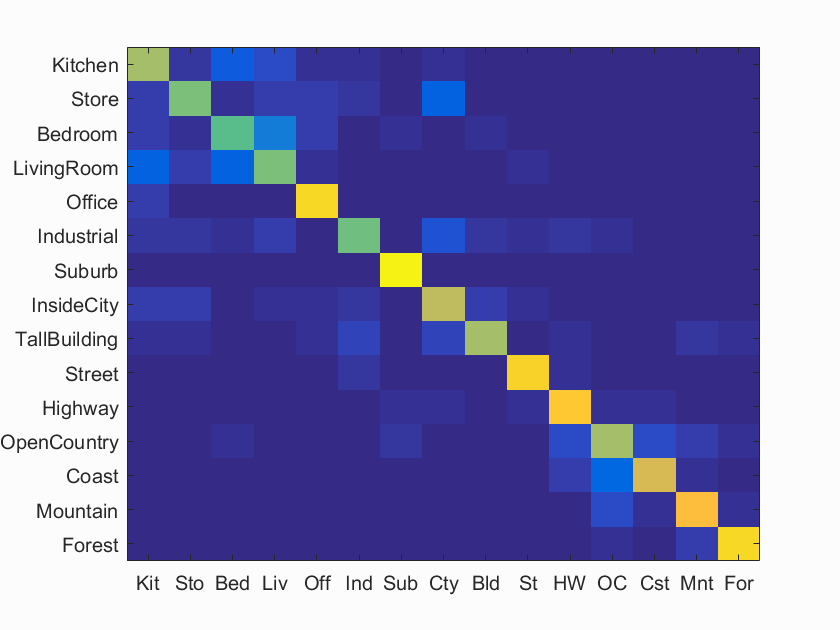
Accuracy (mean of diagonal of confusion matrix) is 0.745
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
|---|---|---|---|---|---|---|---|---|---|
| Kitchen | 0.660 |  |
 |
 |
 |
 LivingRoom |
 InsideCity |
 Bedroom |
 Bedroom |
| Store | 0.600 |  |
 |
 |
 |
 InsideCity |
 TallBuilding |
 InsideCity |
 Mountain |
| Bedroom | 0.550 |  |
 |
 |
 |
 Kitchen |
 Kitchen |
 LivingRoom |
 LivingRoom |
| LivingRoom | 0.600 |  |
 |
 |
 |
 Bedroom |
 Kitchen |
 Office |
 Kitchen |
| Office | 0.920 |  |
 |
 |
 |
 InsideCity |
 InsideCity |
 InsideCity |
 Kitchen |
| Industrial | 0.590 |  |
 |
 |
 |
 Kitchen |
 TallBuilding |
 Kitchen |
 Highway |
| Suburb | 0.970 |  |
 |
 |
 |
 Industrial |
 Kitchen |
 InsideCity |
 LivingRoom |
| InsideCity | 0.710 |  |
 |
 |
 |
 Street |
 Highway |
 Kitchen |
 Kitchen |
| TallBuilding | 0.660 |  |
 |
 |
 |
 Bedroom |
 InsideCity |
 Forest |
 Industrial |
| Street | 0.900 |  |
 |
 |
 |
 InsideCity |
 Industrial |
 Highway |
 Suburb |
| Highway | 0.860 |  |
 |
 |
 |
 TallBuilding |
 OpenCountry |
 Bedroom |
 OpenCountry |
| OpenCountry | 0.660 |  |
 |
 |
 |
 Mountain |
 Coast |
 Highway |
 Highway |
| Coast | 0.750 |  |
 |
 |
 |
 Mountain |
 OpenCountry |
 Highway |
 Highway |
| Mountain | 0.830 |  |
 |
 |
 |
 OpenCountry |
 TallBuilding |
 OpenCountry |
 OpenCountry |
| Forest | 0.920 |  |
 |
 |
 |
TallBuilding |
 OpenCountry |
 Mountain |
 OpenCountry |
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
Submission code
Parameters:
- Vocabulary size = 100, step size = 10
- Bag of sifts, step size = 8
- tiny images, dim = 16x16
- k = 5
- lambda = 0.00001
Accuracies - Runtimes:
- Tiny images + nearest neighbor classifier: 0.223 - 24.55 seconds
- Bag of SIFTS + nearest neighbor classifier: 0.495 - 214.16 seconds
- Bag of SIFTS + linear SVM: 0.5881 - 219.97 seconds.