Project 4 / Scene Recognition with Bag of Words
The goal of this project is to perform scene recognition. Tiny Images and Bags of Sift features were the two image representations used. They were used along with classification techniques (i) nearest neighbor (ii) svm
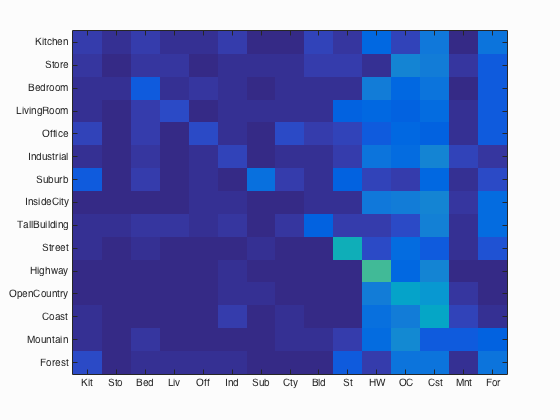
- Tiny image representation and nearest neighbour classifier
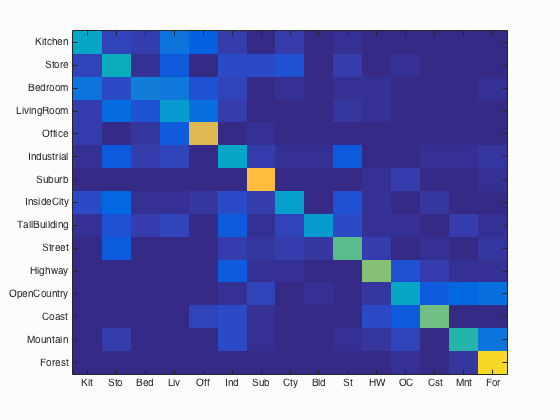
- Bag of SIFT representation and nearest neighbor classifier
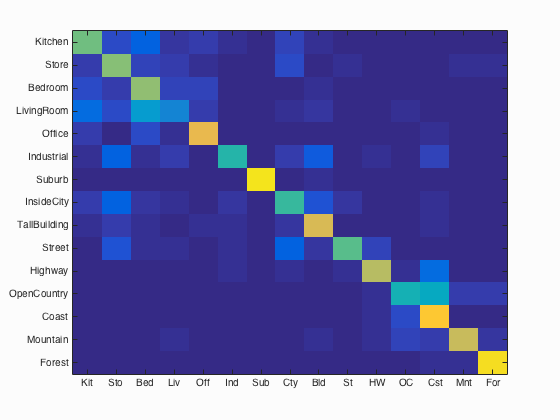
- Bag of SIFT reprentation and linear SVM classifier
Image representations
Classification techniques
Accuracy of the following combinations