Project 4 / Scene Recognition with Bag of Words
In this project, we explore the capabilities of scene recognition using Tiny Images and Bag of Words with KNN and SVM classifiers.
Tiny Images with K-Nearest Neighbors
Tiny Images features are obtained by converting the image to a zero-mean, normalized 16x16 image. With those features, we perform a K-Nearest Neighbors classification by finding the k nearest training features via Euclidean distance select the most highly voted label from them.
The highest accuracy was 0.203 using 1-Nearest Neighbors. K = 1 will fit the model to the data very closely. The accuracy seemed to get lower as we increased K. This is likely because the Tiny Image features most of the time only very slightly differ from each other, which means more neighbors would increase the chances of an incorrect classification.
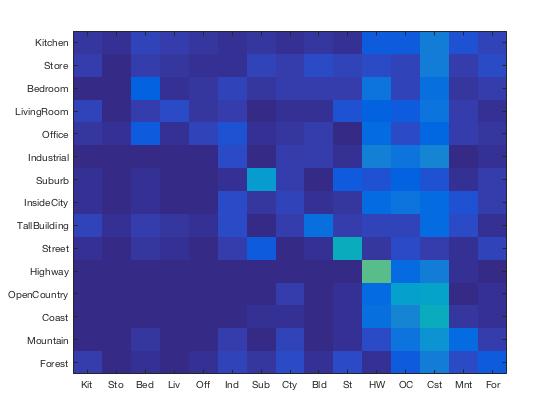
In the resulting classification matrix, we find that Tiny Images with 1-Nearest Neighbors performs the best on Highway images and worst on Stores. This makes sense because Highways tend to look the same even when downscaled whereas the details in Stores when downscaled will resemble other images. We find that the classifier tended to return false positives on Coast, which suggests that because Coast is mostly just sky, land, and water, when downsampled and normalized, everything starts to resemble a Coast.
Bag of SIFT with K-Nearest Neighbors
The Bag of SIFT features was constructed by finding the nearest "word" centroid via Euclidean distance for every SIFT feature found in the image and creating a normalized histogram of the number of features associated with each centroid.
The highest accuracy with Bag of SIFT in conjunction with KNN is 0.527 using a step size of 5 and 4-nearest neighbors. Changing K decreased and increased accuracy, but the highest was 4-nearest and second highest was 1-nearest. The first most similar histogram is reliable but a better model can be obtained reaching a sweetspot value of K.
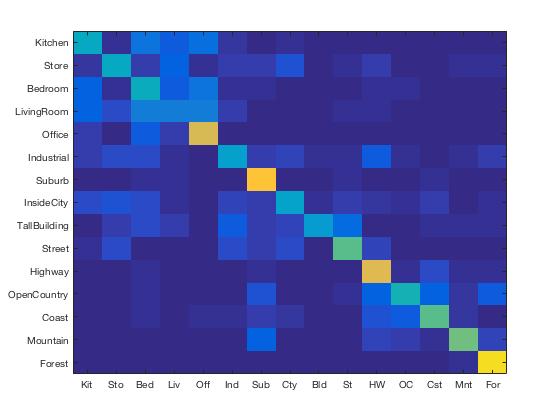
Bag of SIFT with KNN performed the best on Forests, Highways, Suburbs and Offices. Similar to Tiny Images, the good performance on Highways can be attributed to its lack of detailed features across images. The success on Forests is likely due to forest features being distinctly different from features of other images. We see, though, that most of the difficulty lies in distinguishing between Kitchen, Store, Bedroom, and Livingroom which share similar features with one another.
Bag of SIFT with Linear SVM
The Linear SVM binary classifies by splitting data with a hyperplane. For this implementation, we created 15 1-vs-all binary classifiers, one for each of our classes. Each SVM classifier finds the optimal S and B in the hyperplane represented by S*X + B. We then apply the S and B on the test features to get confidence values.
The highest accuracy with Bag of SIFT using Linear SVMs was 0.639 using a step size of 5 and a lambda value of 0.0001. As we decrease lambda, the accuracy increases.
Scene classification results visualization
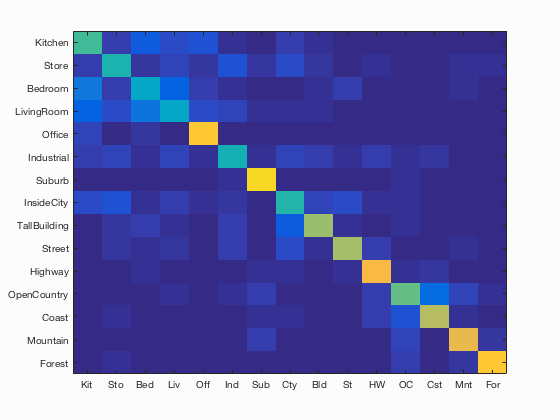
Accuracy (mean of diagonal of confusion matrix) is 0.634
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
|---|---|---|---|---|---|---|---|---|---|
| Kitchen | 0.520 |  |
 |
 |
 |
 Office |
 LivingRoom |
 Bedroom |
 LivingRoom |
| Store | 0.460 |  |
 |
 |
 |
 LivingRoom |
 Coast |
 Forest |
 LivingRoom |
| Bedroom | 0.390 |  |
 |
 |
 |
Kitchen |
 LivingRoom |
 LivingRoom |
 Industrial |
| LivingRoom | 0.380 |  |
 |
 |
 |
 Store |
 Store |
 Mountain |
 TallBuilding |
| Office | 0.870 |  |
 |
 |
 |
 Kitchen |
 LivingRoom |
 Bedroom |
 Bedroom |
| Industrial | 0.450 |  |
 |
 |
 |
 TallBuilding |
 Store |
 Kitchen |
 InsideCity |
| Suburb | 0.910 |  |
 |
 |
 |
 Forest |
 Coast |
 Store |
 Industrial |
| InsideCity | 0.480 |  |
 |
 |
 |
 Highway |
 TallBuilding |
 Industrial |
 OpenCountry |
| TallBuilding | 0.650 |  |
 |
 |
 |
 Street |
 Industrial |
 InsideCity |
 InsideCity |
| Street | 0.660 |  |
 |
 |
 |
 InsideCity |
 InsideCity |
 TallBuilding |
 Highway |
| Highway | 0.820 |  |
 |
 |
 |
 OpenCountry |
 InsideCity |
 Coast |
 OpenCountry |
| OpenCountry | 0.570 |  |
 |
 |
 |
 Suburb |
 Highway |
 Industrial |
 Mountain |
| Coast | 0.700 |  |
 |
 |
 |
 OpenCountry |
 Bedroom |
 OpenCountry |
 InsideCity |
| Mountain | 0.790 |  |
 |
 |
 |
OpenCountry |
 Forest |
 Forest |
 Forest |
| Forest | 0.860 |  |
 |
 |
 |
 Store |
Store |
 Mountain |
 Mountain |
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||