Project 4 / Scene Recognition with Bag of Words
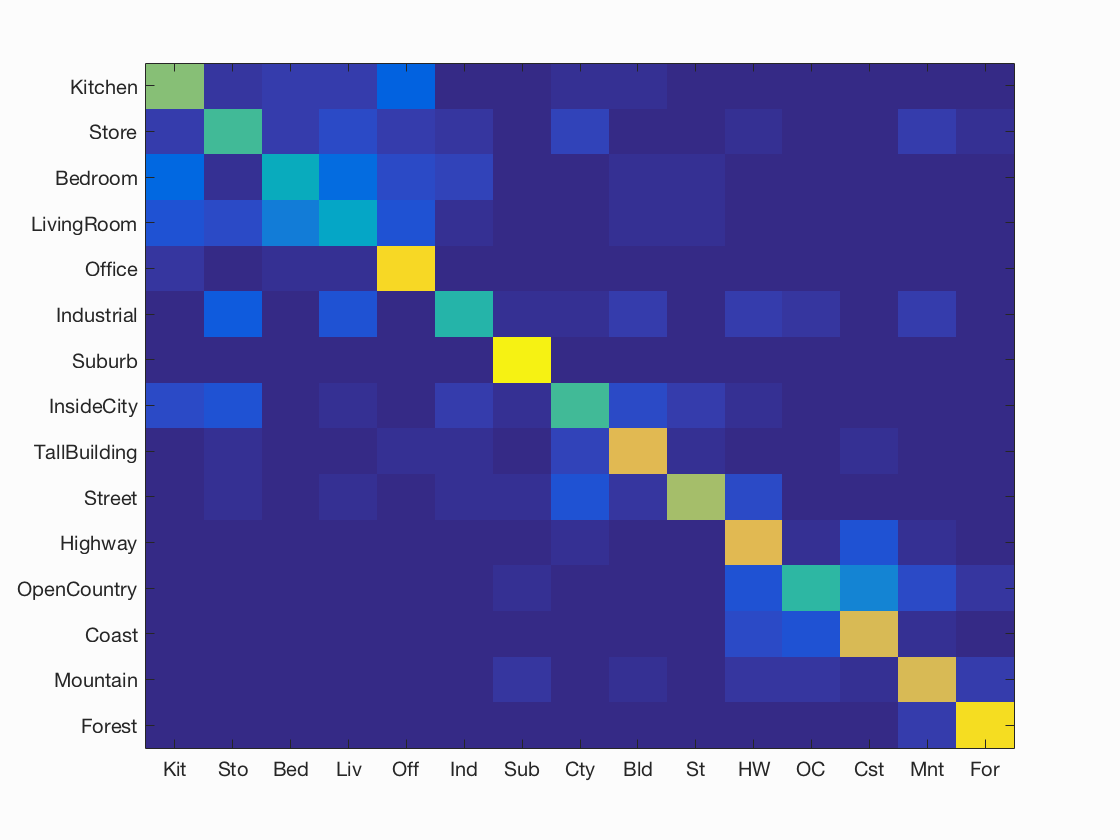
Example of a Confusion Matrix.
Overview
This project uses Matlab to perform variations of scene recognition. Using different combinations of Timy Image and Bag of Sift features with Nearest Neighbor and All-vs-one Linear SVM classifiers, we observe different recognition accuracies. The feature methods are used in conjunction with the classifier methods to attempt recognition.
Algorithms
Each recognition algorithm uses a combination of a feature and a classifier method. The logic behind those methods are defined below.
Tiny Images Feature
The tiny images algorithm works by compressing the images to much smaller, 16x16 representations. The details are:
- For each image, resize to 16x16
- Reshape the resized image to be a vector of 256 (16*16) entries
- Make the vectors zero-meaned and normalized
- Comprise a matrix of image features from these vectors
Build Vocabulary
The Build Vocabulary function constructs sift features from a given vocabulary. This vocabulary is then cached for later use. SIFT feature detection is used to build the feature vocab. In detecting vocab features, the step size (I used 4) is variable and effects for ever 'step' pixels we try to extract descriptors. K-means ise then used to cluster the features into the visual word vocabulary. The details are summarized below:
- For each image, use vl_dsift with a 'step' of 4 to extract descriptors
- Use k-means on the descriptors to build a visual word vocab.
Bag of Sift Feature
The Bag of Sift feature uses the vocabulary built to detect image features. In detecting features, the step size (I used 4) is variable and effects for ever 'step' pixels we try to extract descriptors. Vl_kdtreequery was used instead of vl_alldist2 due to observed speed increase in testing. The details are summarized below:
- For each image, use vl_dsift with a 'step' of 4 to extract descriptors
- Use vl_kdtreequery with the vocab and features to find the min indexes
- Create histograms of the min indexes for the vocab
- Noramlize the histograms
- Create a matrix of image features from these histograms
Nearest Neighbor Classifier
The nearest neighbor classifer is used to predict a category for a set of features. The classifier uses 1-nearest-neighbor to find the closest match by distance. vl_alldist2 is used for the distance calculation. The details are summarized below:
- Calculate the distances between the test image features and the train image features
- Find the min indexes
- Return the category labels that match the min indexes (closest matches)
All-vs-one Linear SVM Classifier
All-vs-one linear SVM is used to optimize the best possible decision boundary for classifiers. In this case, there is a separate decision boundary for each category and they are combined to make the best decision. A parameter, lambda, was tuned to find the best possible regularization (affecting fitting) value. The details are summarized below:
- For each category, create a vector for all labels
- Initialize the values of the vector to -1 (no match)
- Assign 1 to labels that are relevant baseed on comparing the category to training label strings
- Use vl_svmtrain with the training image features, label classifiers, and lambda
- Use W*X + B = confidence to determine confidences
- Calculate the most confident idnexes and return the categories that match those confidences
Testing Accuracies
Below is a list of the observed accuracies when testing with different combinations of feature and classifier methods. In terms of time spent, most time was spent in the latter two test cases determining sift features.
| Feature | Classifier | Accuracy | Run Time (quad-core 2015 i7) |
| Tiny Image | Nearest Neighbor | 24% (0.247) | ~15 seconds |
| Bag of Sift | Nearest Neighbor | 52% (0.522) | ~7 minutes |
| Bag of Sift | Linear SVM | 66% (0.666) | ~7 minutes |
Bag of Words and Linear SVM
Best Results Scene Classification
To achieve the best possible results, bag of words and linear SVM were used. The following parameters were tuned:
| Paramater | Value |
| Vocab Images | All |
| Building Vocab SIFT step | 16 |
| Bag of Sifts step | 4 |
| Sift Distance Measurement | KD Tree |
| SVM Lambda | 0.0001 |
I noticed the biggest differences around the adjustment of the SIFT step values. A 'step' is value used in the context of extracting a SIFT descriptor every 'step' pixels. While values of 2 and 4 produced an equivalent result for the bag of sifts step, using 2 took much longer. Similarly, more than 4 produced a less accurate result. When building vocab, using less or more than 16 steps produced in a loss of accuracy as well. Using a KD Tree rather than using vl_alldist2 resulted in a significantly faster result. The lambda value, which affects the regularization (fitting adjustment) was chosen by experimenting in factors of 10.
Accuracy (mean of diagonal of confusion matrix) is 0.666
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
|---|---|---|---|---|---|---|---|---|---|
| Kitchen | 0.620 |  |
 |
 |
 |
 InsideCity |
 Bedroom |
 LivingRoom |
 LivingRoom |
| Store | 0.530 |  |
 |
 |
 |
 LivingRoom |
 Industrial |
 Suburb |
 Kitchen |
| Bedroom | 0.420 |  |
 |
 |
 |
 Store |
 LivingRoom |
 LivingRoom |
 Office |
| LivingRoom | 0.380 |  |
 |
 |
 |
 Store |
 Bedroom |
 Street |
Store |
| Office | 0.910 |  |
 |
 |
 |
 Bedroom |
 LivingRoom |
 Bedroom |
 LivingRoom |
| Industrial | 0.480 |  |
 |
 |
 |
 Store |
 Kitchen |
 LivingRoom |
 Coast |
| Suburb | 0.980 |  |
 |
 |
 |
 Street |
Store |
 OpenCountry |
 InsideCity |
| InsideCity | 0.520 |  |
 |
 |
 |
 TallBuilding |
 Street |
 LivingRoom |
 Coast |
| TallBuilding | 0.780 |  |
 |
 |
 |
 Industrial |
 InsideCity |
 Mountain |
 Bedroom |
| Street | 0.660 |  |
 |
 |
 |
LivingRoom |
 InsideCity |
 Mountain |
 InsideCity |
| Highway | 0.780 |  |
 |
 |
 |
 Mountain |
 OpenCountry |
 Coast |
 Coast |
| OpenCountry | 0.490 |  |
 |
 |
 |
 Mountain |
 Highway |
 Coast |
 Coast |
| Coast | 0.750 |  |
 |
 |
 |
 OpenCountry |
 OpenCountry |
 Mountain |
 Highway |
| Mountain | 0.760 |  |
 |
 |
 |
 Industrial |
 Store |
 Bedroom |
 Coast |
| Forest | 0.930 |  |
 |
 |
 |
 OpenCountry |
 InsideCity |
 Mountain |
 Mountain |
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||