Project 4 / Scene Recognition with Bag of Words

Example of a right floating element.
The purpopse of this project is to get us familiar with various techniques that can be used for scene or image recognition. I utilized a few different methods in order to get the image recognition working, starting with the simple method of using tiny images and nearest neighbor classification and moving towards more complex, yet more effective methods, such as a "bag of words", or in this case, a "bag of sift" features with an svm linear classifier. Among the scenes that are being tested against are offices, kitchens, mountains, cities, and highways. The different parts of the project that I had to implement were:
- get_tiny_images.m
- nearest_neighbor_classify.m
- build_vocabulary.m
- get_bag_of_sifts.m
- svm_classify.m
get_tiny_images.m
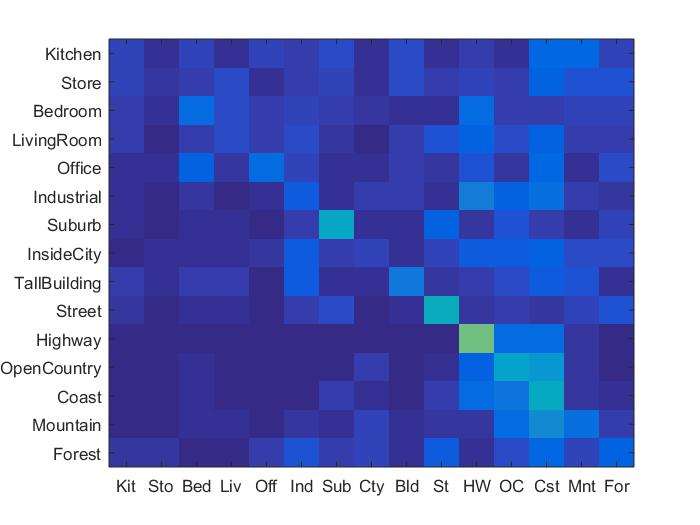
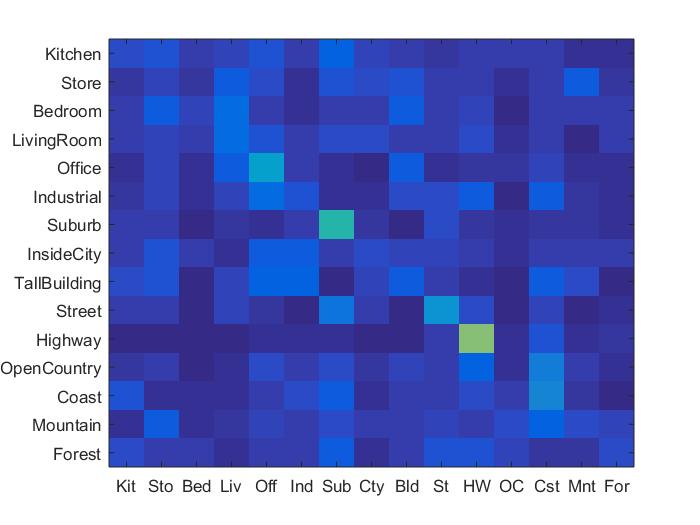
The first task that I completed was writing the function get_tiny_images.m for the simple feature representation of the image classification. Though this implementation is fairly fast, it is not very accurate, as a lot high frequency information in the images is lost when the image is shrunk down to a 16x16 image. The best performance I was able to achieve was about 22.5%, surprisingly with the nearest neighbor classifier, whereas my svm implementation only yielded a maximum accuracy of 19.1%.
nearest_neighbor_classify.m
The nearest neighbor classifier function was written in order to take in training images and use some measure of distance, in this case, the vl_alldist2 function, to compute the category that each test image is likely in. Although I could have implemented some function of weighting beween k nearest neighbors, however, in the case of this function, I simply use the closest neighbor in order to make a judgement on the classification of each image. This can lead to a high variance in the classification, as slight skews in distances between categories can lead to drastic differences in classification.
build_vocabulary.m
This function builds vocabulary clusters sampled SIFT features from the training images provided and returns the cluster centers to use to judge distance from all the feature spaces from the feature set. This vocabulary is used in the bag of sifts function.
get_bag_of_sifts.m
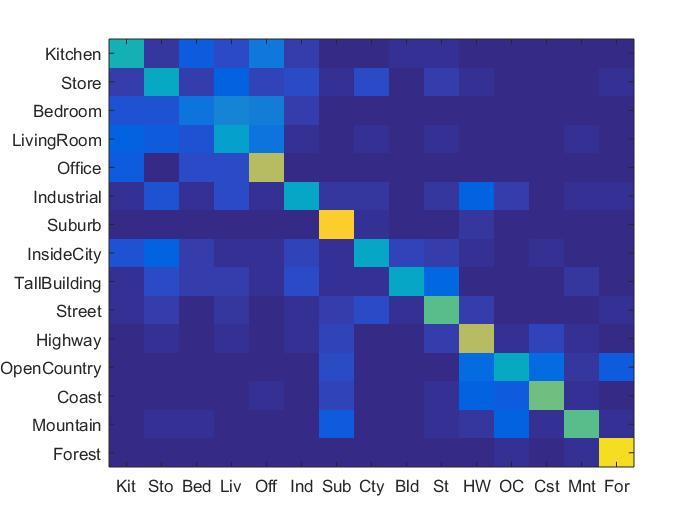
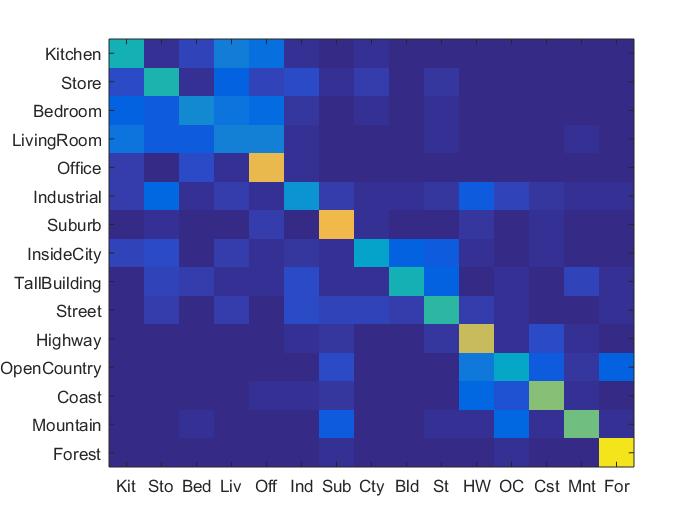
This is another method to gather features from images. Instead of just making the images smaller, which can lead to a loss of information, the bag of sifts function creates histograms of the frequency of certain SIFT descriptors that are drawn from each of these images. In order to do this, we need vocabulary words that comes from build_vocabulary. Bag of sifts performed much better overall than tiny images did, as the features were more robust and maintained more information than the tiny images did. However, the performance varied in terms of speed and accuracy depending on the step size. When a step size of 5 was used with svm, an accuracy of 68.1% was reached, however it took almost 25 minutes to run. I was able to get a much faster performance at around 8 minutes with little drop in accuracy, at about 65.8% accuracy with svm.
svm_classify.m
This function is used as another classificatoin technique instead of nearest neighbors. Where nearest neighbors had high variance, svm was more consistent in determining the best categorization of images. SVM by far had the best performance when used with either tiny images or bag of sifts, as, at least in my implementation, it did not take simply the closest computed cluster as truth, thus avoiding overfitting that nearest neighbors seems to fall victim to.
Results in a table
|
|
|
|
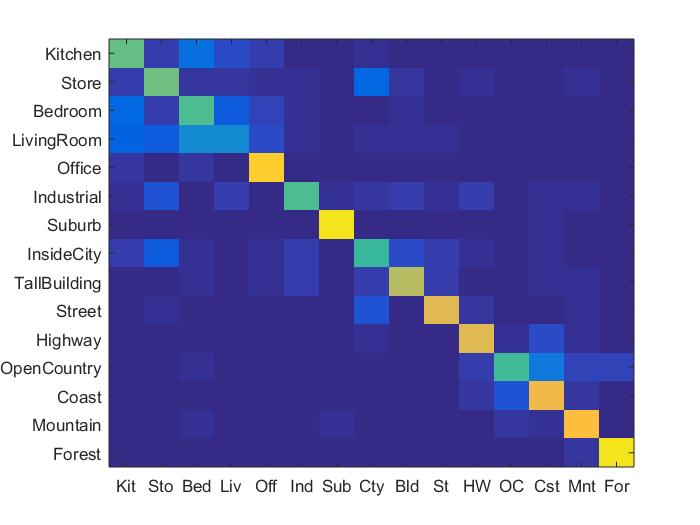
|
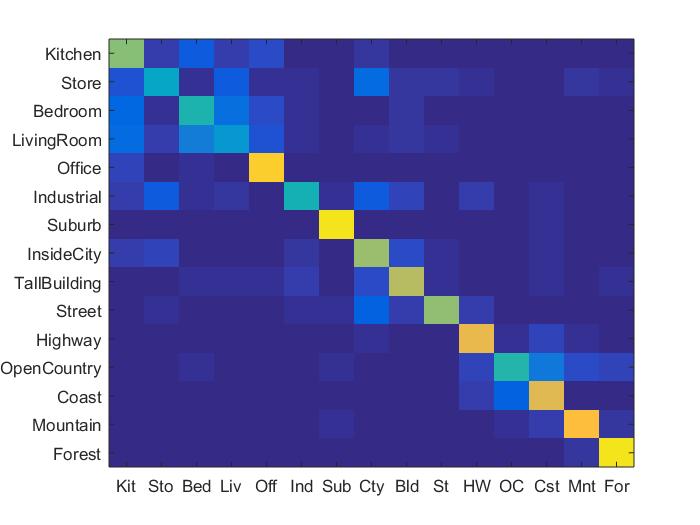
|
As can be seen above, the best performing combination of features and classifier were the bag of sifts feature with the svm classifier. The bag of sifts implementation performed much better than the tiny images implementation, likely because the tiny images implementation causes there to be a loss of high frequency information in each of the images. The SVM classifier has less variance, and far out performed the nearest neighbor implementation, though I could've made the nearest neighbor implementaiton more robust by adding in some weighted distance function between all of the potential neighbors. Though the bag of sift feaures with a step size of 5 performed the best in terms of accuracy, it was almost 3 times as slow as using a step size of 8, while only sacrificing around 3% of accuracy for an accuracy of about 65.8%. For this reason, I think that the bag of sifts plus svm feature-classification combination performed the best overall. The full results can be seen below.
Bag of sift with SVM