Project 4 / Scene Recognition with Bag of Words
In this project, I implemented multiple image features and classification methods using those features. The first "feature" was the "tiny image" representation, involving scaling each image down to a 10x10 square and vectorizing the image. This feature was only paired with the nearest neighbor classifier in this project, the nearest neighbor classifier simply storing each input training feature as a point with its associated identifier and then assigning test points the identifier of the closest stored point. Using the Euclidean distance metric, nearest-neighbor classification using the tiny image feature showed an accuracy of 20.9%.
Second, I implemented a bag of SIFT feature to be used for image classification. First, the system extracts dense SIFT-like features from each image in the training set, scanning through each image and producing a SIFT feature every set number of pixels. Though true SIFT features require preliminary smoothing of an image before feature extraction, I found that the system produced the best results when smoothing was skipped entirely. Once these SIFT features were extracted from the training set, they were clustered and the resulting centroid of each cluster was added to the "vocabulary" to be used for characterizing each image. With this vocabulary of averaged SIFT features created, the system can produce a histogram feature to characterize any image by collecting dense SIFT features from it, and assigning each of those extracted features to a bin of a histogram corresponding to one of the SIFT vocabulary "words" based on the distance from the extracted feature to the word; normalizing the resulting histogram provides a feature which describes the source image. Using the chi-squared distance metric with the nearest-neighbor classification method as well as a spatial bin breadth of 8 pixels for SIFT feature extraction and a word count of 200 for vocabulary generation, image classification accuracy using the bag of SIFT features reached 51.9%.
Finally, I implemented an SVM classifier to be used with the bag of SIFT features. For each category of image in the training data, the system creates a linear SVM and a new set of labels for all features in the training set marking each feature as being either of the category currently being considered or any other category. The new SVM is then trained on these classifiers, configured to identify members of one specific category. Once each of the linear SVMs are created, features from the test set are evaluated on each SVM. The test feature is then assigned a category corresponding to the SVM which returned the highest value when the test point was evaluated on it. With a training lambda of 0.00001, accuracy using bag of SIFT features and linear SVM classifiers reached 63.1% before the system's runtime began to grow unwieldy. Below are the confusion matrix and detailed results generated by the system using these parameter settings.
Scene classification results visualization
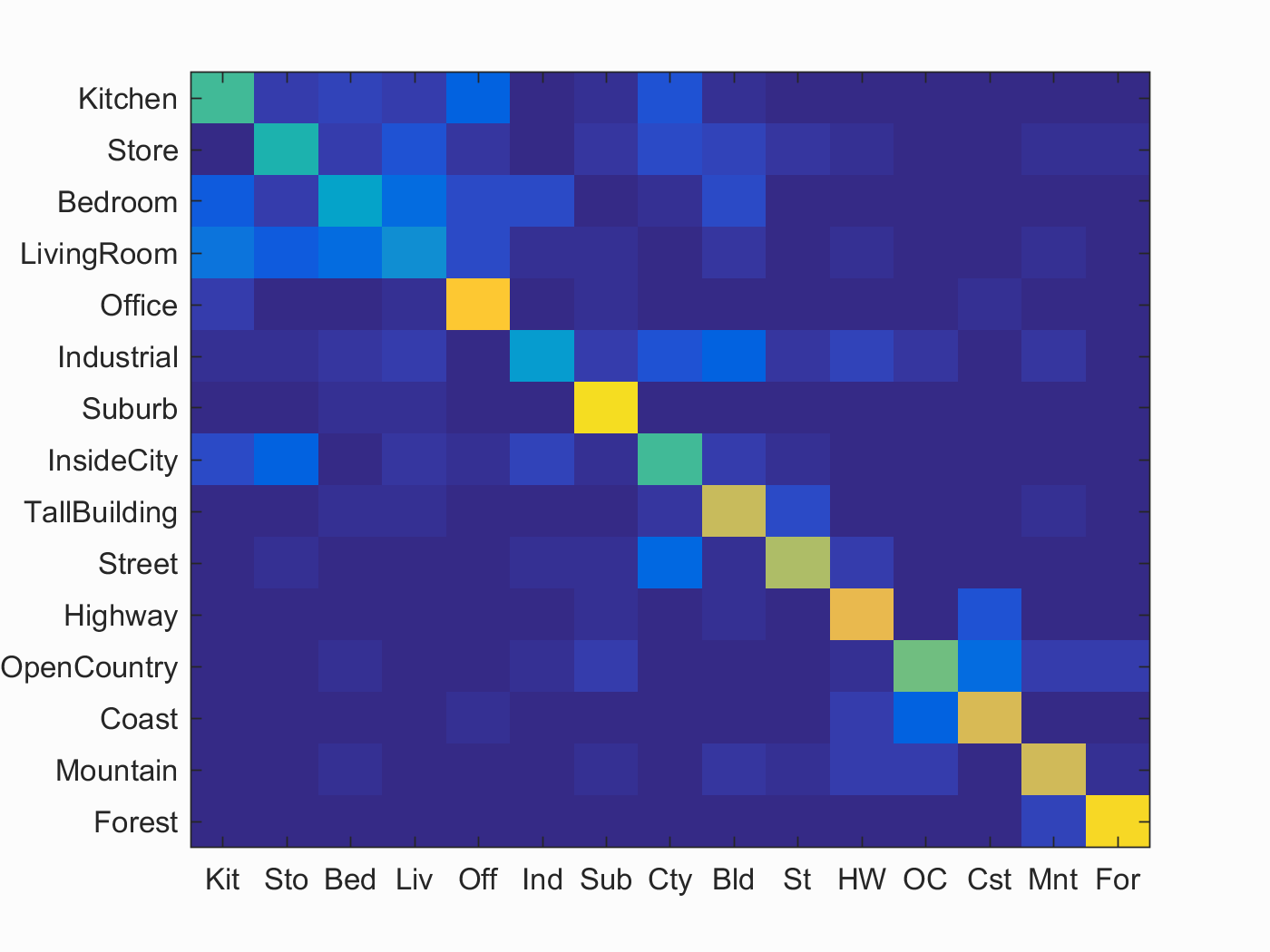
Accuracy (mean of diagonal of confusion matrix) is 0.631
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
|---|---|---|---|---|---|---|---|---|---|
| Kitchen | 0.530 |  |
 |
 |
 |
 InsideCity |
 LivingRoom |
 InsideCity |
 Store |
| Store | 0.460 |  |
 |
 |
 |
 InsideCity |
 LivingRoom |
 TallBuilding |
 Suburb |
| Bedroom | 0.370 |  |
 |
 |
 |
 LivingRoom |
 Kitchen |
 Kitchen |
 Kitchen |
| LivingRoom | 0.290 |  |
 |
 |
 |
 Bedroom |
 TallBuilding |
 Store |
 Kitchen |
| Office | 0.860 |  |
 |
 |
 |
 LivingRoom |
 LivingRoom |
 Kitchen |
 Kitchen |
| Industrial | 0.330 |  |
 |
 |
 |
 Bedroom |
 Bedroom |
 Store |
 Mountain |
| Suburb | 0.930 |  |
 |
 |
 |
 Office |
 Highway |
 InsideCity |
 LivingRoom |
| InsideCity | 0.520 |  |
 |
 |
 |
 Street |
 Street |
 Store |
 Store |
| TallBuilding | 0.720 |  |
 |
 |
 |
 Mountain |
 LivingRoom |
 Bedroom |
 InsideCity |
| Street | 0.680 |  |
 |
 |
 |
 Industrial |
 TallBuilding |
 Highway |
 Highway |
| Highway | 0.790 |  |
 |
 |
 |
 Coast |
 Mountain |
 Bedroom |
 Coast |
| OpenCountry | 0.590 |  |
 |
 |
 |
 TallBuilding |
 Coast |
 Industrial |
 Highway |
| Coast | 0.750 |  |
 |
 |
 |
 OpenCountry |
 OpenCountry |
 OpenCountry |
 Office |
| Mountain | 0.740 |  |
 |
 |
 |
 Store |
 Forest |
 TallBuilding |
 Street |
| Forest | 0.910 |  |
 |
 |
 |
 Store |
 OpenCountry |
 OpenCountry |
 Mountain |
| Category name | Accuracy | Sample training images | Sample true positives | False positives with true label | False negatives with wrong predicted label | ||||
Graduate Credit
In addition to the standard required parts of the project, I implemented soft feature assignment for histogram generation. Instead of finding the nearest SIFT feature vocabulary word to each extracted SIFT feature when constructing histograms, the histogram generation system finds a small set of the nearest neighbors to each extracted SIFT feature in the test image. Then, for each of these nearest neighbors, the corresponding histogram bin is increased by an amount proportional to the exponent of the square of the distance from the extracted feature to that centroid, as described in Philbin et al 2008. Though I spent hours tuning the number of nearest neighbors to consider and the tuning factor used in the histogram generation process, I was only able to get an improvement of a few percentage points out of the switch to soft assignment, reaching 65.5% accuracy at best.
Finally, I tested the baseline system of linear SVMs trained on bags of SIFT features with different codebook sizes. As I saw in initial parameter tuning, performance reaches the point of diminishing returns around a vocabulary size of 200. Before this point, performance improves steady with increased codebook size.
