Project 4: Scene Recognition with Bag of Words
Scene Recognition Pipeline
Given a set of training and testing images, the recognition pipeline:
- Encodes all of the images using the specified representation.
- Labels the testing images using the specified scene classifier.
- Scores the accuracy of the recognition system.
Image Representations
Tiny Image (TI)
Each image is resized to a small, square resolution of size s × s (the original aspect ratio is ignored). The resulting image matrix is reshaped into a feature vector of length s 2 and normalized to unit magnitude. This simple representation allows for fast encoding and comparison of images.Bag of Sift (BoS)
Each image is represented as a histogram of "visual words". The visual words are precomputed by densely sampling many SIFT descriptors from the training images (vl_dsift) and using k-means clustering (vl_kmeans) to quantize the SIFT descriptor space. Therefore with a vocabulary of 50 visual words and 100 SIFT descriptors detected in the input image, the BoS representation would be a histogram of 50 bins counting the number of times each SIFT descriptor was assigned to each visual word (i.e. cluster center). "Soft assignment" can be used to assign each descriptor to the p-closest visual words with contributions weighted by distance from the cluster centers. Afterwards, the histogram is normalized so that the image size does not affect the feature magnitude.
Fisher Vector (FV)
Similarly to Bag of Sift, each image is encoded by assigning local SIFT descriptors to words in a visual vocabulary. In the case of Fisher Vectors (vl_fisher), the visual vocabulary is obtained with a Gaussian Mixture Model (vl_gmm) constructed from densely sampled SIFT descriptors.
Image Classifiers
k-Nearest Neighbors (kNN)
At test time, each test image is assigned the majority class of the k-nearest training examples in the feature space (using L2 distance). The parameter k controls how many of the nearest neighbors vote for the output class.Support Vector Machine (SVM)
The training set is used to learn a binary, 1-vs-all SVM for each of the 15 scene categories. When training the SVMs, the parameter lambda controls how strongly regularized the model is. At test time, each test image is assigned to the class of the most confidently positive SVM.Results
The recognition pipeline was trained and tested on the 15 scene database from Lazebnik et al. 2006.
Testing accuracy is reported for the following pipeline combinations:
- Tiny Images + k-Nearest Neighbors
- Bag of Sift + k-Nearest Neighbors
- Bag of Sift + SVM
- Fisher Vector + SVM
Tiny Images + k-Nearest Neighbors
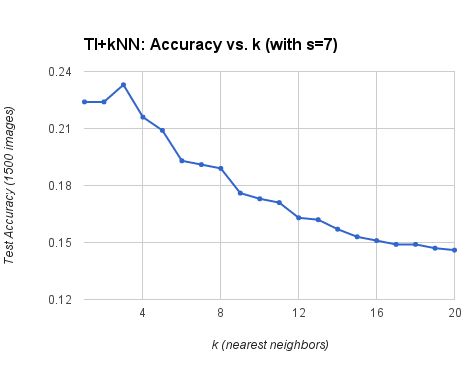
This pipeline achieves an accuracy of 23.3% when using k = 3 nearest neighbors and s = 7 for the tiny image size. The figures below show how the parameters k and s affect recognition accuracy at test time.
|
|
Recognition accuracy drops off after k > 3 nearest neighbors. |
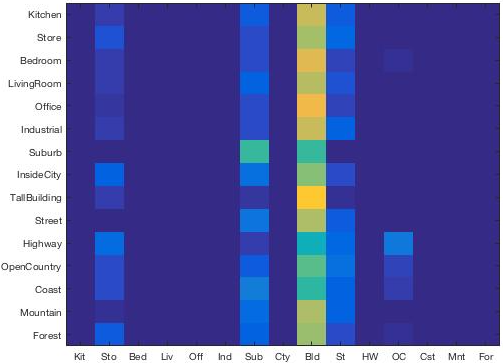
With s = 7 and k large (i.e. 50), majority vote is "Building" for most categories. |
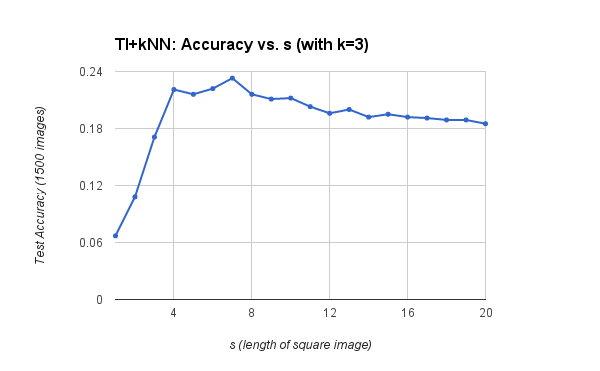
When s < 7, high frequencies are lost and the tiny images become indistinguishable.
As s grows > 7, the images become less likely to match pixel-for-pixel.
Bag of SIFT + k-Nearest Neighbors
This pipeline achieves an accuracy of 53.9% when using k = 1 nearest neighbors, a visual vocabulary of size 200, and p = 2 contributions for histogram "soft assignment". Visual vocabularies were built by densely sampling all 1500 training images with a step size of 10 (for a total of 965,525 SIFT samples). Test images were sampled using SIFT step 5 and the 'fast' parameter. The charts below show how the vocabulary size and the number of "soft assignments" affect the pipeline's recognition accuracy.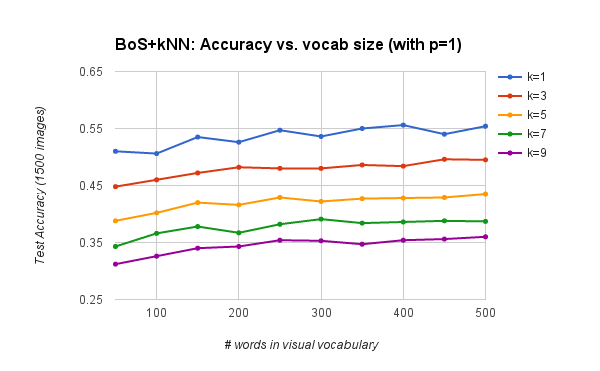
Increasing vocabulary size improves accuracy to a limit.
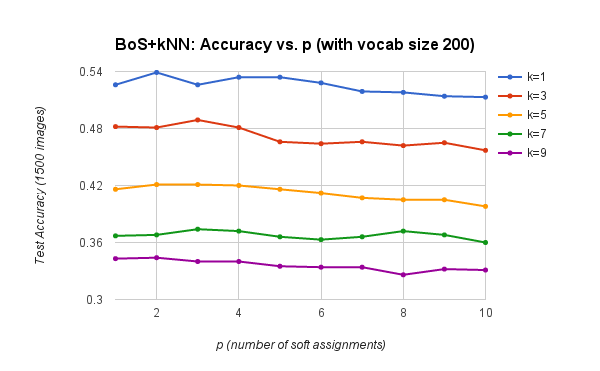
Peak accuracy is obtained with p between 2 and 4 .
Bag of SIFT + SVM
This pipeline achieves an accuracy of 68.7% when using p = 1 and lambda = 0.0001. The visual vocabulary was built using all 1500 training images and SIFT step 10. The size of the visual vocabulary was held constant at 200 words. Test images were sampled using SIFT step 5 and the 'fast' parameter. The charts below show how accuracy is affected by parameters lambda (SVM regularization parameter) and p (number of soft assignments for word histograms).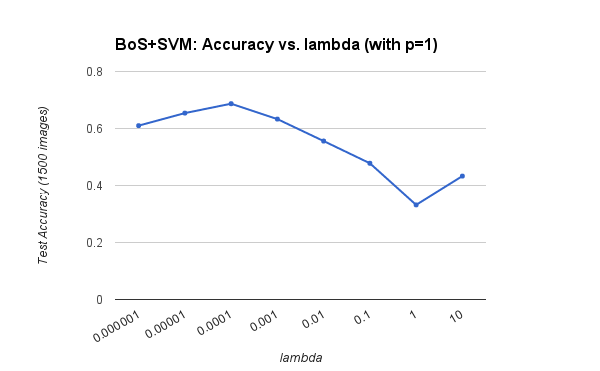
Peak accuracy (68.7%) obtained when lambda equal to 1e-4.
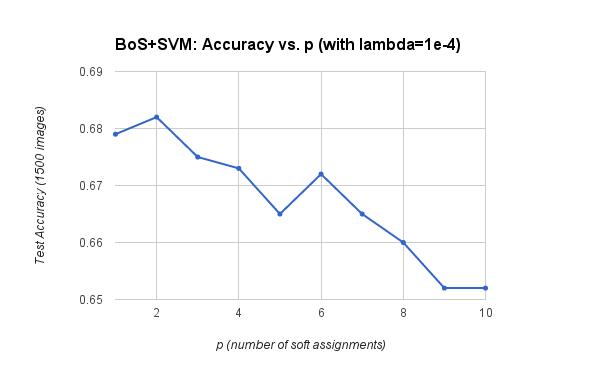
Improved accuracy with p = 2.
Accuracy declines as p grows > 2.
Fisher Vector + SVM
This pipeline achieves an accuracy of 77.9% when using 1000 visual words and lambda = 0.0001 for SVM regularization. The visual vocabulary (GMM) was built by sampling all training images with SIFT step 10. Test images were sampled using SIFT step 3 and the 'fast' parameter. The chart below show how the number of visual words and the regularization parameter lambda affect testing accuracy. The confusion matrix and table of classifier results generated by the starter code are also shown below.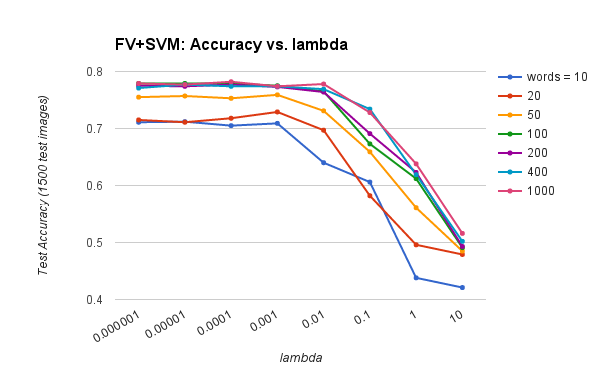
Increasing number of visual words improves accuracy to a limit around 78%.
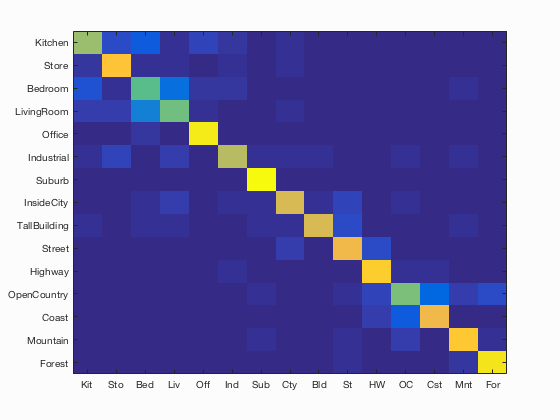
Accuracy (mean of diagonal of confusion matrix) is 0.779



















.jpg)
.jpg)




.jpg)



.jpg)














.jpg)










.jpg)



.jpg)




































.jpg)














.jpg)

