Project 5 / Face Detection with a Sliding Window
The goal of this project is to detect faces in images using the Dalal-Triggs Algorithm.
Algorithm
get positive features
To get a histogram of gradients for face images.
- Get all images in the directory provided. All images contained here are faces.
- For each image, convert it to grayscale and get the HoG features via
vl_hog. This gets us a histogram of gradients for the image. - Reshape each hog feature into a row and input it into the list of positive features. This gets us a HoG list of features so that we know what the histogram for a face looks like.
get random negative features
To get a histogram of gradients for non-face images.
- Iterate through each image in the directory provided. All images contained here are non-faces.
- For each scale provided, convert it to grayscale and scale the image. So we can learn what non-faces look like at multiple scales.
- Get a list of random indices for the scaled image provided. This will help us get random (template_size x template_size) samples from this image.
- Get the histogram of gradients for each sample with
vl_hog. This will make it comparable to the positive HoG features. - Reshape the HoG into a row for input into the list of non-face HoG features. This allows us to compare with the list of positive features later.
classifier training
To get a linear classifier to define faces from non-faces based on a histogram of gradients.
- Combine positive and negative histograms of features into a matrix.
- Create a vector of type
doublethat corresponds to the order of histograms of images defined above. +1 if the feature was from a face, and -1 from a non-face. - Use
vl_svmtrainto getwandb. These values will be used to classify images in the next step.
run detector
- For each image in the test directory, scale it by different factors. To take into account differently sized faces.
- For each scaled image, get the HoG feature. So we can evaluate it against the trained classifier.
- For each cell around each pixel in the scaled image, reshape it into a vector.
- Calculate the confidence, which is w' * x + b. w and b came from the trained classifier in the classifier training step.
- If the confidence for the cell is greater than the threshold, save it. Add the bounding box, confidence, and image id to a running list for the current image.
- Perform non-maximal suppression on the bounding boxes per image. To get rid of unnecessary duplicates.
- Return bounding boxes, confidences, and image id's. This shows the areas the classifier believes there are faces at.
Parameters
get_random_negative_featuresimage scales: [1.0, 0.9, 0.8, 0.7].
Scaling the images didn't seem to change the average precision significantly though.run_detectorthreshold: 0.5
This lower threshold let more bounding boxes through and increased the overall recall, helping the accuracy.run_detectorscales: [1, 0.8, 0.64, 0.512, 0.4096, 0.32768]
Scaling the image at these values helped detect different sizes of faces best.classifier traininglambda: 0.0001
This value worked the best out of all the lambdas I tested.proj5.mcell_size: 6
This value was not changed.
Precision-Recall Graph and HoG Visualization
Average Precision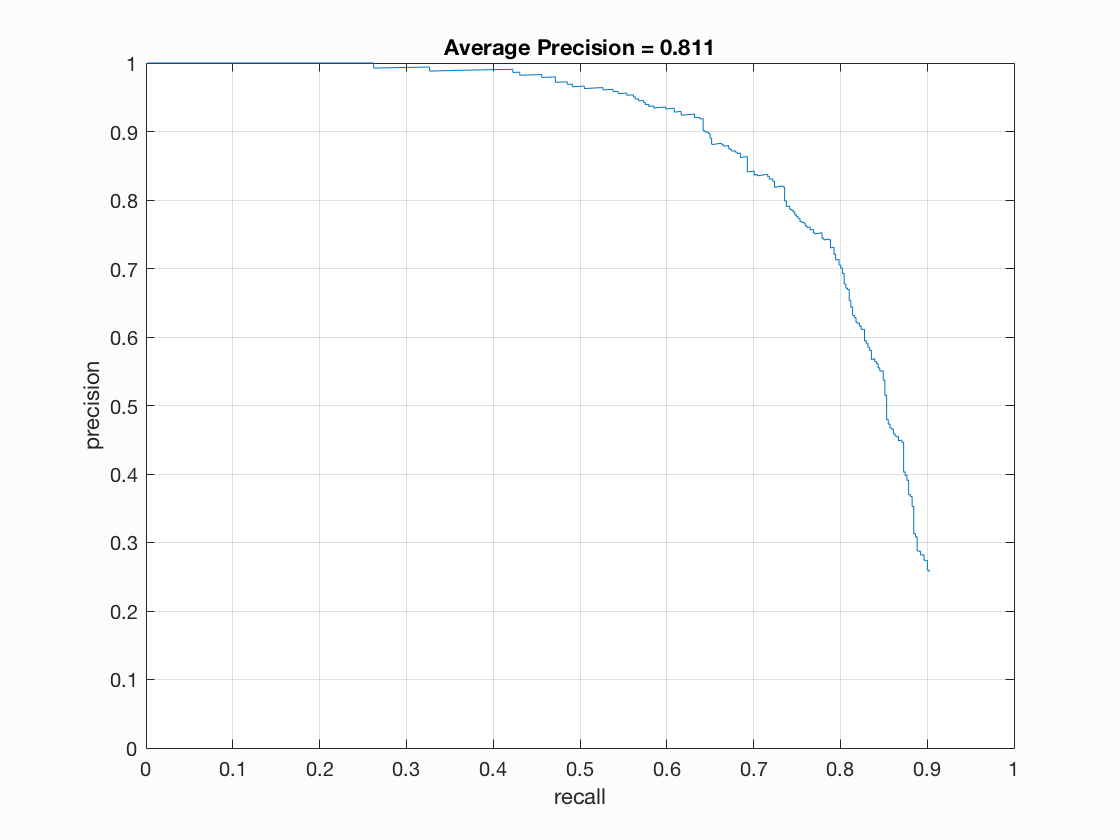
|
HoG Template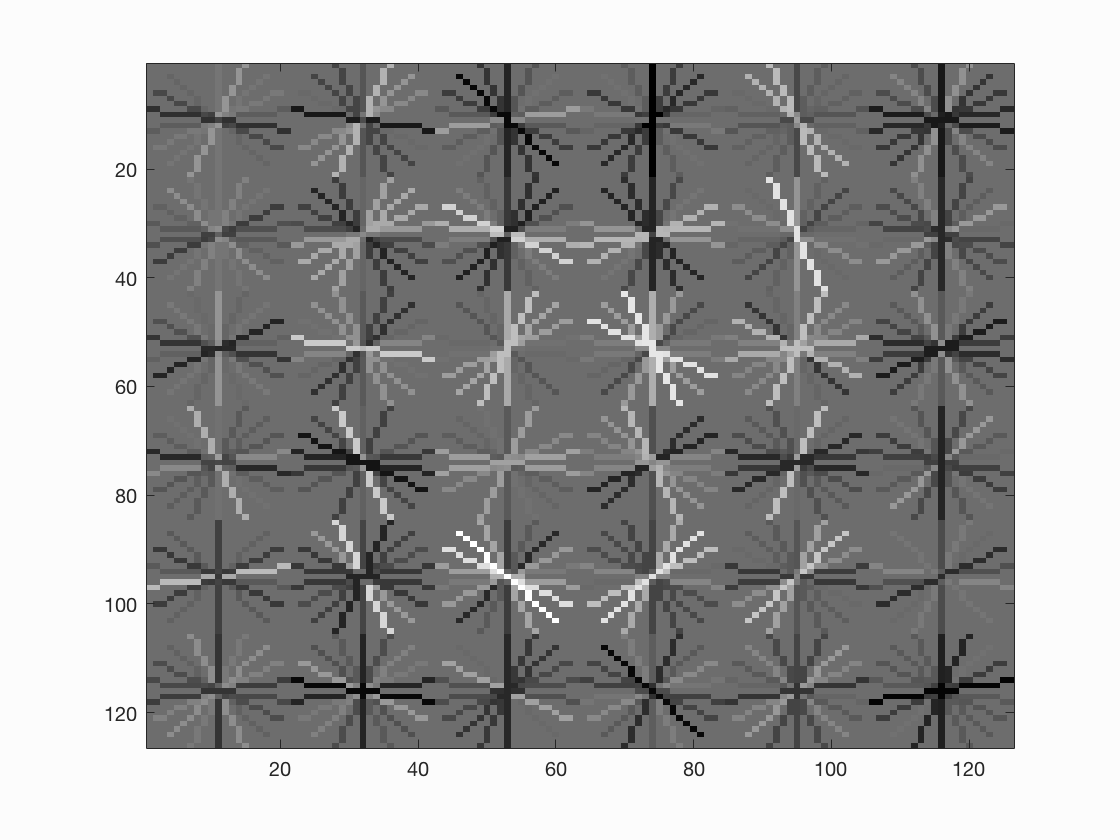
|
Class Picture
|