Project 5 / Face Detection with a Sliding Window
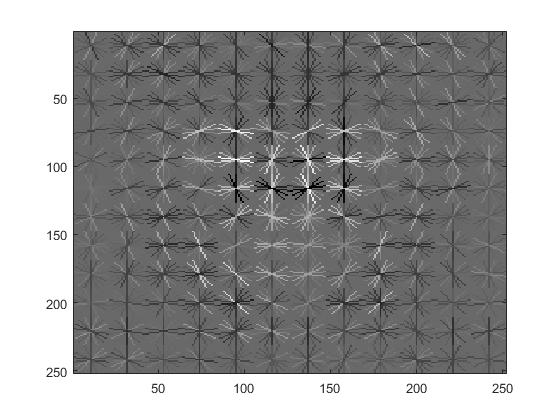
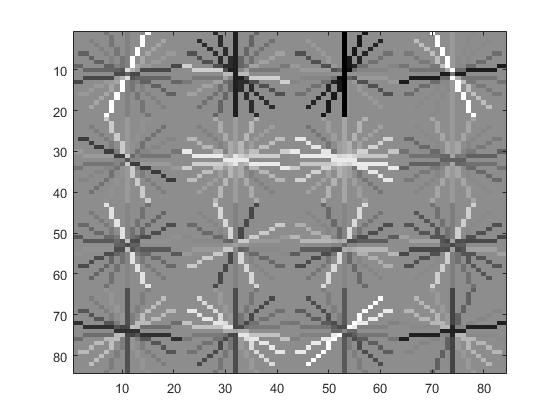
These are the Histogram of Oriented Gradients for cell sizes 3 and 9, respectively.
- Introduction
- Methods
- Results
.
1. Introduction
Here, the project asks for an implementation of the Sliding Window Detector to detect faces. To do so, one classifies patches of boundaries as being a face or not a face.
This project involves getting the training features through a histogram of oriented gradients. Next I train a SVM in order to detec faces from non faces. I run the face detector on the images. For some parts of these pieces, many adjustments and levers such as lambda, scale, and confidence thresholds can be modified to figure out a useful model parameter.
.
2. Methods
For this project, I had to train features for faces and for non faces. For positive features, I had the Caltech Web Face Project with 6713 36x36 faces as features. The images are simply read in and applied the VLFeat hog function.
For negative features, I needed non face data. I used from Wu et. al. and the SUN Scene Database. I had set the number of negative features to 20000.
For the testing data, I had the CMU+MIT test Set with 130 images with 511 faces.
SVM classification was done in proj5.m. Specifically in the following lines implmeenting the VL svm train:
lambda = 0.0001;
X = [features_pos;features_neg]';
Y_positive = ones(size(features_pos,1),1);
Y_negative = ones(size(features_neg,1),1);
Y = [Y_positive;Y_negative*-1]';
[w b] = vl_svmtrain(X, Y, lambda);
Here, I process the images and simpyl call the function, setting the lambda up as I please. The lambda is to be adjusted to see its effect on the SVM classifier.
In run_detector, I set up confidence thresholds and an acceleration variable. The acceleration is specifically the scale step.
3. Results
After various amounts of experimentation, I found that a small cell size, a near 1 scale step, a low confidence threshold, and a low lambda to be useful settings for a model. As such, during experimentation, I set a basic setup to be cell size=3, acceleration=.9, confidence threshold=.1, and lambda = .0001. I did not choose the absolute best values for average precision, given time take goes asymptomatically to forever.
Scale Step and Confidence
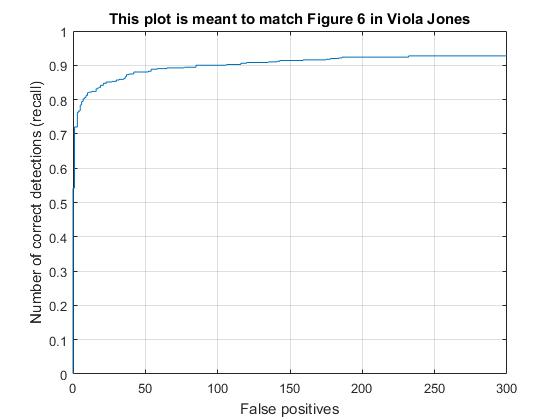
Here, I tested out the scale step adjustments. Results indicate higher average precision at higher, neat 1 values, but also lead to a particularly longer run time. A step of 1 doesn't even terminate, naturally, as it would be stuck in a loop. On the other hand, lowering the scale step dramatically decreased the time it took for the program to run and complete the task. However, speed increases peaked around .8 or .9, and lower steps led to diminishing increases in time efficiency, while average precision fell steadily.
Scale at .9. Note a particularly slow training, as well as high average precision.
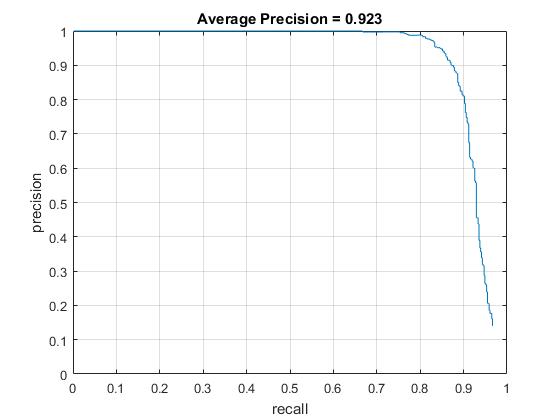
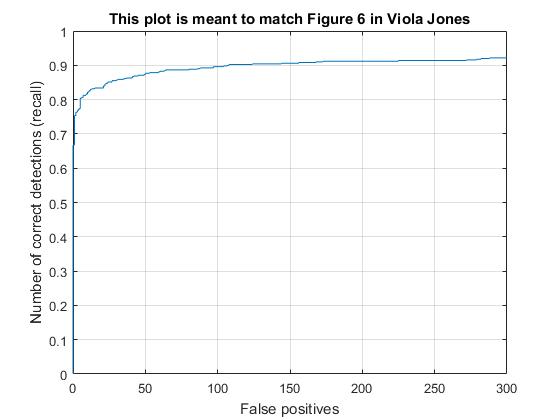
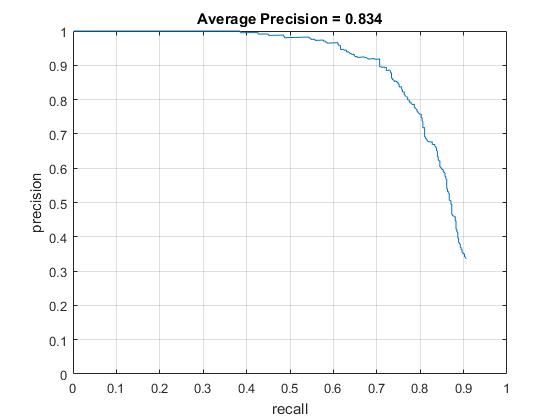
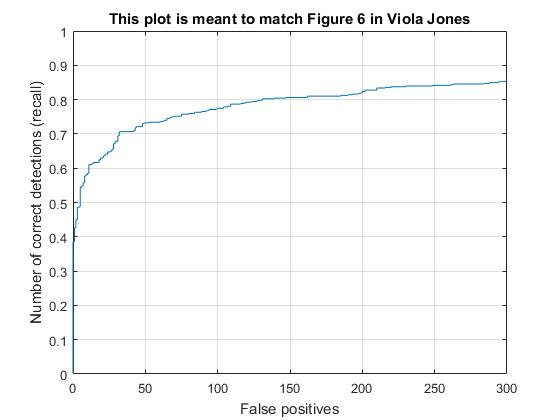
Scale at .8. Faster training. Similar Precision.
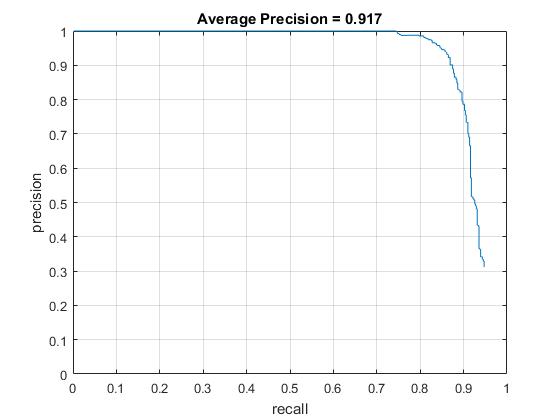
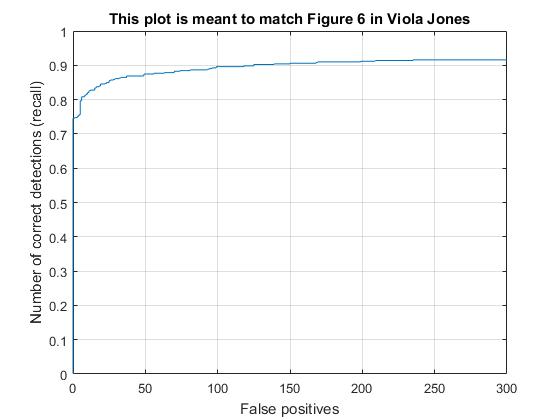
Scale at .5. Markedly lower precision.
Confidence values did not adjust the average precision much, but had a small effect. Confidence seemed best values near 0.
Cell Size
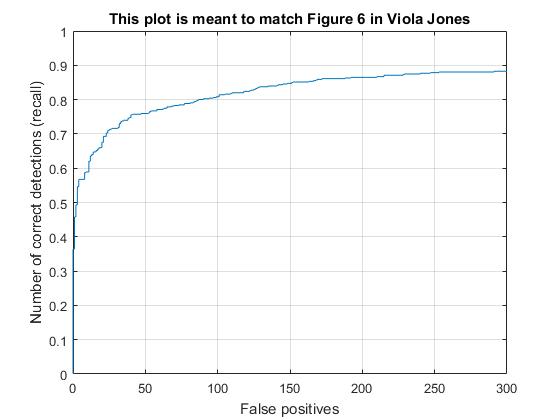
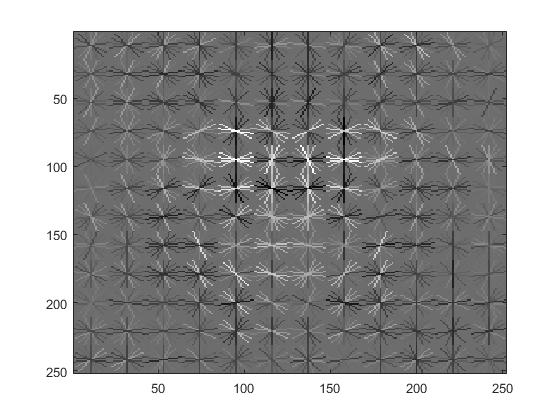
Cell size had a direct and obvious effect on the average precision. Here are the HOGs and VJ comparisons for the cell sizes of 3, 6, and 9.
Cell size 3
Cell size 6
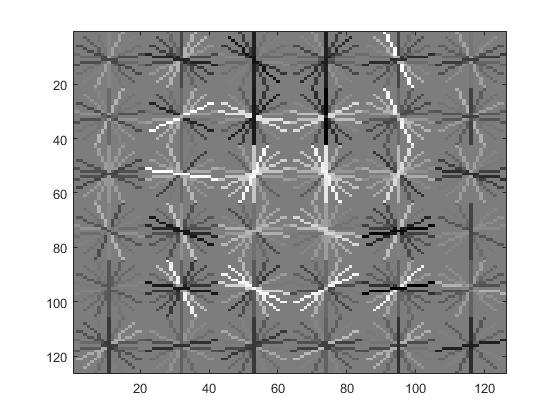
Cell size 9
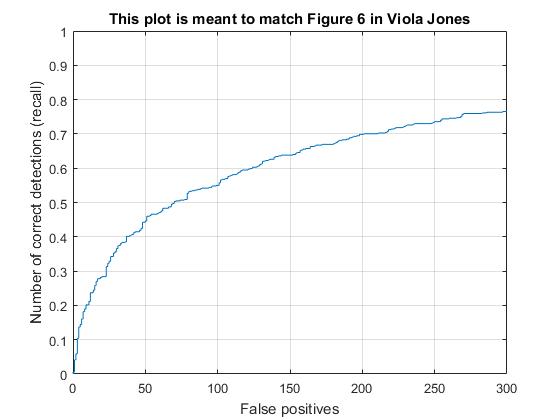
Lambda and Negative Example Number
Lambda had an effect on the accuracy of the classifier. There are small differences, most notably seen when you set lambda a couple mangitudes different. Funny enough, .0001 lambda had 100% accuracy over .00001 lambda.
.1 lambda
Initial classifier performance on train data:
accuracy: 0.997
true positive rate: 0.249
false positive rate: 0.000
true negative rate: 0.748
false negative rate: 0.003
vl_hog: descriptor: [12 x 12 x 31]
vl_hog: glyph image: [252 x 252]
.00001 lambda
Initial classifier performance on train data:
accuracy: 0.999
true positive rate: 0.251
false positive rate: 0.000
true negative rate: 0.749
false negative rate: 0.000
vl_hog: descriptor: [12 x 12 x 31]
vl_hog: glyph image: [252 x 252]
.0001 lambda
Initial classifier performance on train data:
accuracy: 1.000
true positive rate: 0.251
false positive rate: 0.000
true negative rate: 0.749
false negative rate: 0.000
vl_hog: descriptor: [12 x 12 x 31]
vl_hog: glyph image: [252 x 252]
Word size had a small helpful impact. A lower word size trained faster, but a higher word size had better precision.
Here are example detection pictures. The model scale acceleration .9, confidence .1, number of negative examples 20000, cell size 3, and lambda .0001.
Average Precision
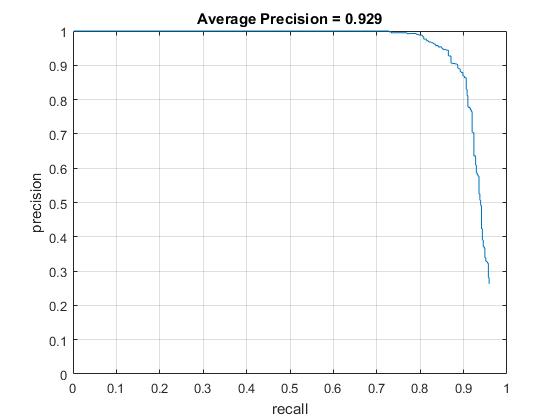
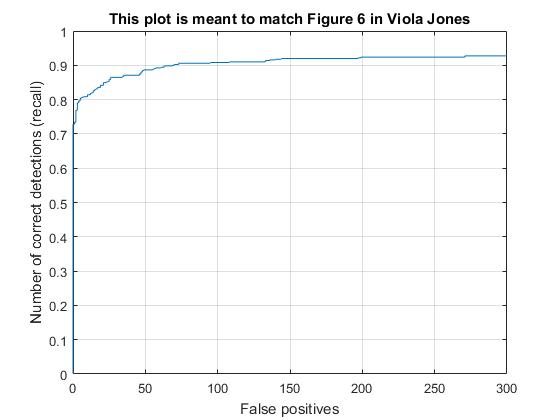


Here are the results for the extra scene, along with the visualization. The model scale acceleration .9, confidence .1, number of negative examples 20000, cell size 3, and lambda .0001.
HOG
Example Detections

