Project 5 / Face Detection with a Sliding Window
In this project we will detect faces by using a sliding window on HoG cells.
Step 1. Load positive training crops and random negative examples
First we extract HoG features from 36x36 templates of positive and negative training examples. I have increased the number of negative examples to 20000 (previously 10000). I also tried to produce more positive training data by flipping the images but it didn't seem to work well.
The code is very simple. The main action is a call to vl_hog() to compute the HoG features for each training image.
Step 2. Train Classifier
In this step we use vl_svmtrain to train a linear classifier on the data we collected above. The function returns a weight vector w and an offset b that we can use to evaluate the testing images.
Free parameter: lambda = 0.0001 (the smaller the better)
Step 3. Run our detector on test set
We resize the image to different scales (here I use scale factors from 0.05 to 1.5 with step of 0.05). For each scale, we convert the image to HoG feature space using vl_hog(). We then have a sliding window over the HoG cells, with the window's size equal to the learn template's, and classify them based on our trained model. If the confidence is above some threshold, we apply non-maximum suppression on the detections to prevent the problem of having duplicate detections.
Free parameter: scale_factor = 0.05 : 0.05 : 1.5, confidence_threshold = 0.60 (This threshold is set quite low to get higher recall rate)
Results
HoG cell size = 6
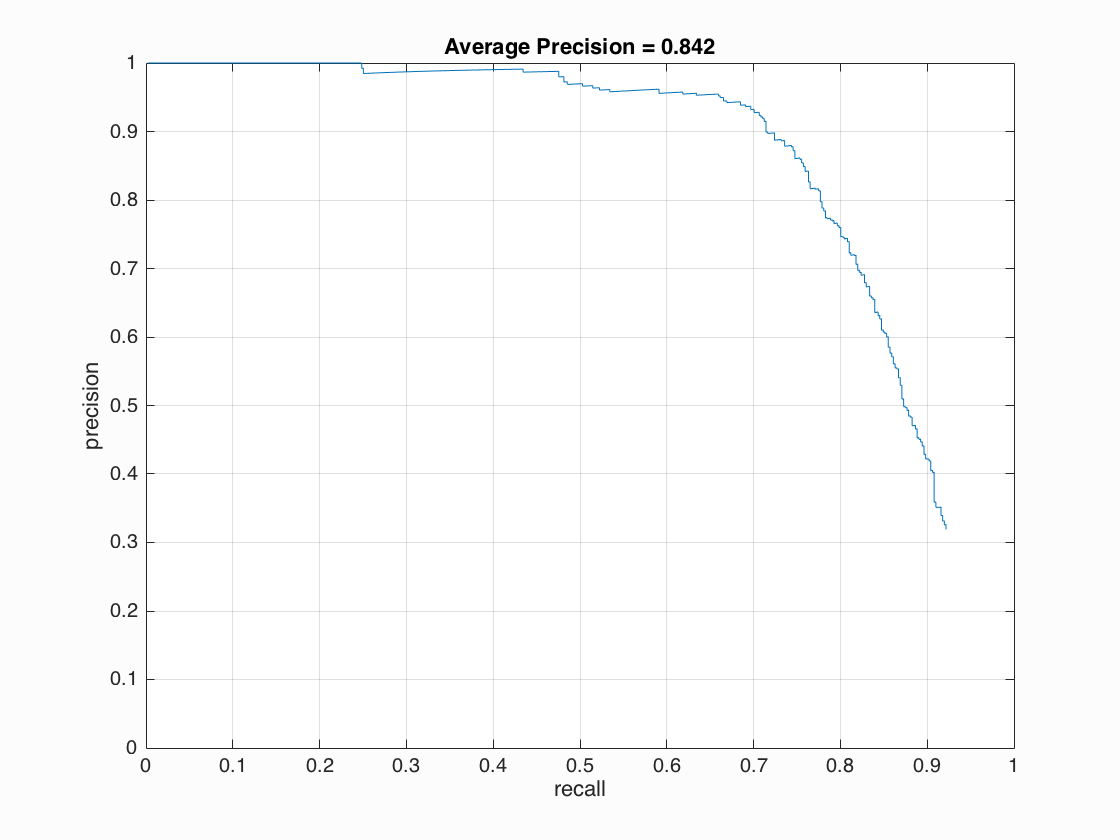
| Face template HoG visualization | Average precision |
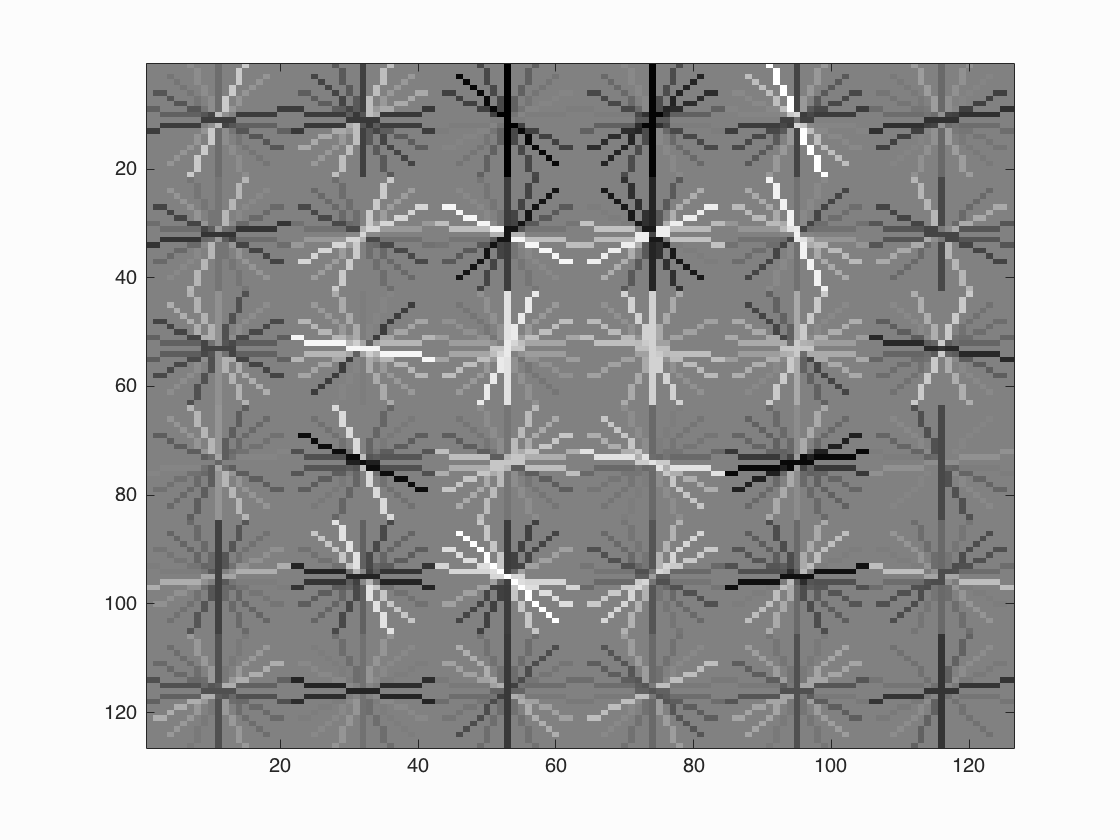 (looks like a face with black/dark hair and light skin tone, and the contour suggests an oval shape) |
 |
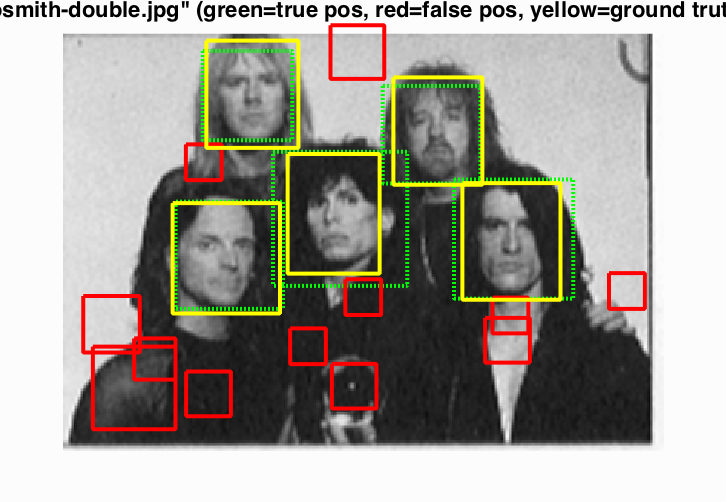 |
It generally detects most faces, but also can include many false ones. |
 |
Usually works well on portraits |
 |
and even on pictures of soccer teams. |
 |
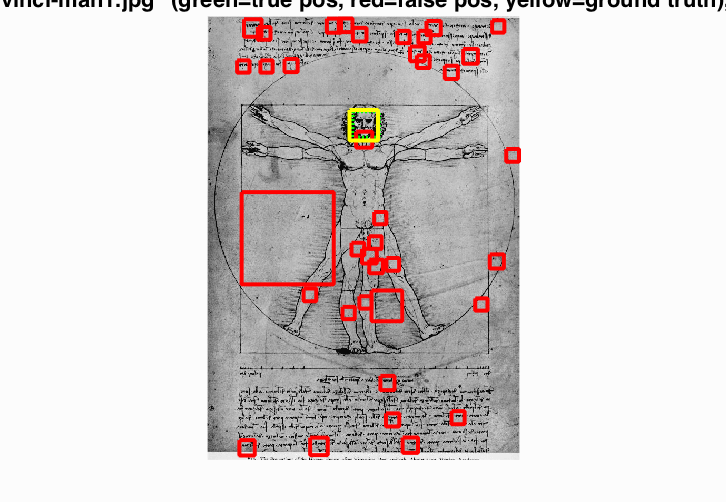
It fails very badly here. The stars just happen to align. |
 |
The black-white colors seem to throw it off a bit. |
 |
At least it found a real face! |
 |
Works also quite well even if the image is noisy. |
HoG cell size = 3
We will revisit the images that we did very poorly with hog cell size = 6
| Face template HoG visualization | Average precision |
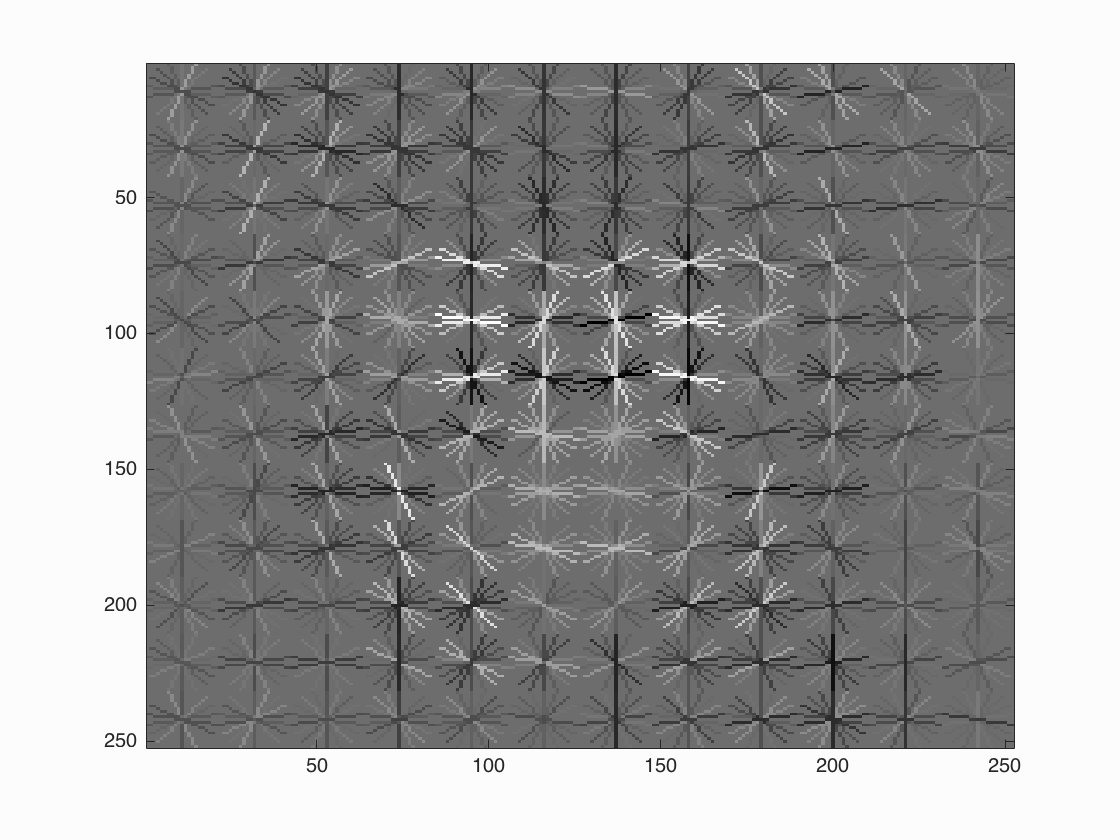 (much more resembles a face) |
 |
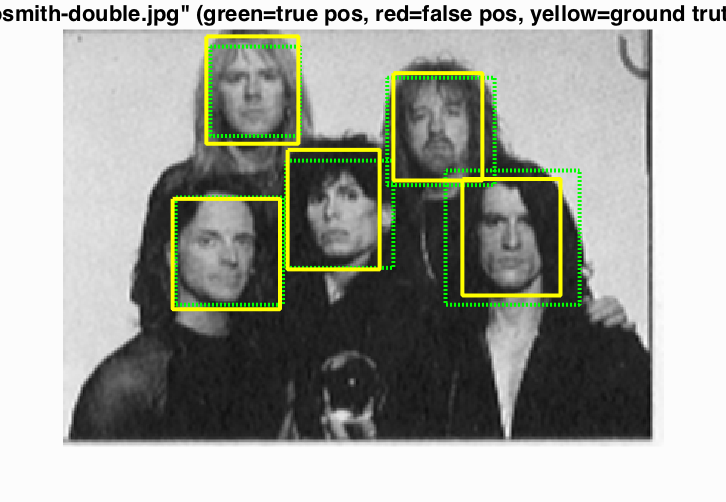 |
Perfect detection! |
 |
Not even one false detection. |
 |
Much better. |
 |
The box is positioned correctly now. |
 |
Can't believe it. All the false positives are gone. |
Summary/Analysis
Smaller pixel cell sizes increase the average precision (AP) very nicely as they describe faces in more detail, but they also increase the computation time exponentially.
- multiscale, 6 pixel cell size and detector step ~ 0.842 AP
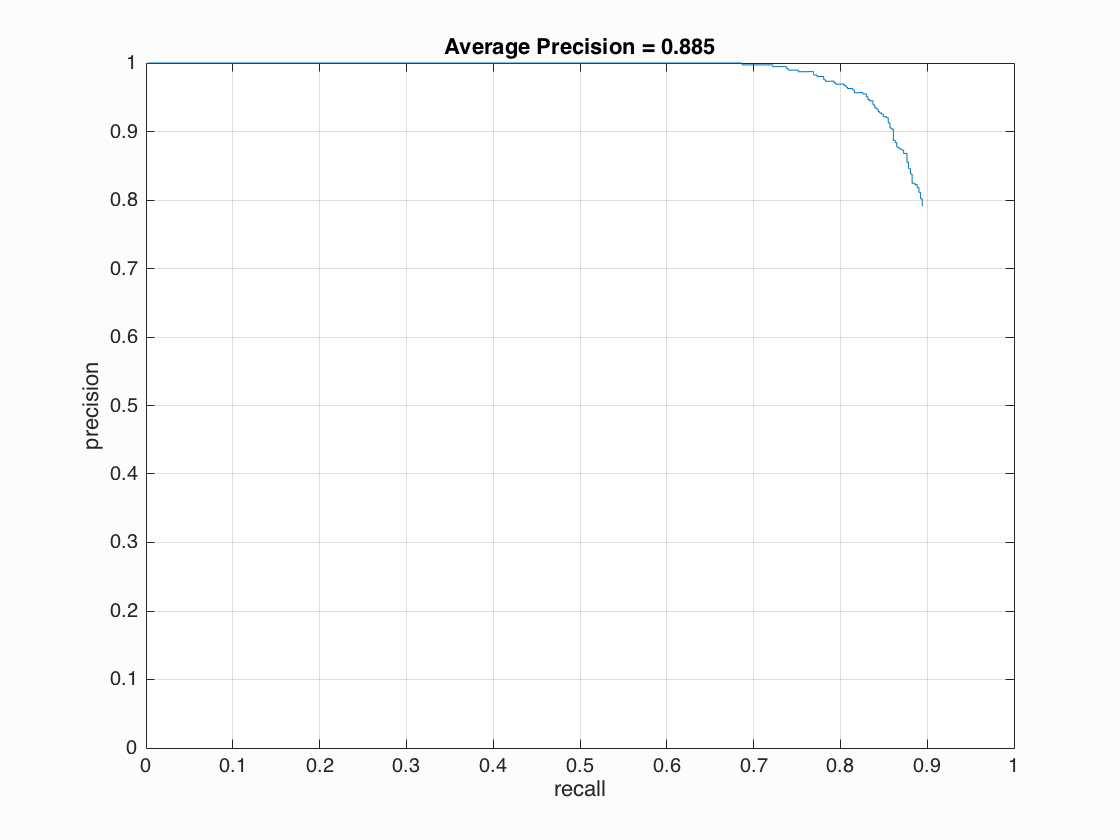
- multiscale, 3 pixel cell size and detector step ~ 0.885 AP
Overall the algorithm works very well. The precision is generally high, but drops down quickly when we try to go beyond 0.7 recall.
Extra scenes


