Project 5 / Face Detection with a Sliding Window
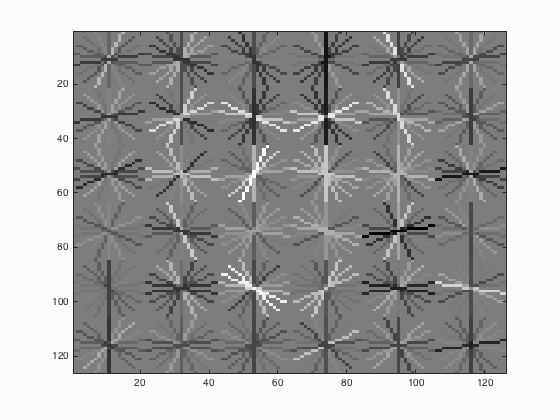
The learned HoG Descriptor
The face detector implemented in this project operates in three steps:
- Learn HoG Descriptors for Faces and Non-Faces
- Train SVM on Descriptors
- Use a Sliding Window to Detect Faces
Learning HoG Descriptors
The entire pipeline depends on a consistent HoG cell size, which was 6, in this implementation. Learning positive examples of faces doesn't require any more paramters than this. A descriptor for each face is computed, and then used as an example for SVM training in the next step. Learning negative examples is more compilicated, because it requires sampling randomly from images that are known to not contain faces. For this implementation, 10000 images of the same dimensionality as the positive face examples were sampled from the images, at a random scale between 0.5 and 1. This multi-scale sampling allows the SVM to have more examples of non-face textures at different scales.
Training SVM
The main parameter in SVM training is the lambda, or scaling value. For this implementation, the best value was found to be 0.0001. After training the SVM, the following model for a HoG template was learned. It clearly resembles a face, which is indicative that the SVM has discovered the salient features in the space.
Sliding Window Detector
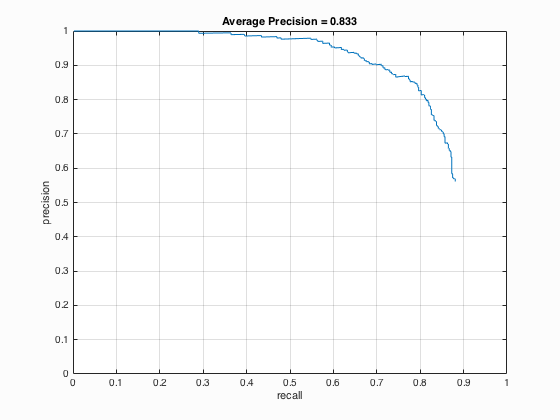
The principal free parameter in the sliding window is the threshold at which detections are rejected. Empirically, the best threshold was found to be 0.75. While a SVM score of 0.75 is clearly indicative of a strong match, the recall was only mildly impacted by this choice. The precision vs recall curve, indicating 83% accuracy, is shown below. Since the classifier doesn't detect all the faces, the curve stops at just under 90% recall.
Results
An example of a good detection is shown below. Only the player's knee is mis-detected, but this is because it bears a passing resemblance to a real face.

Another example of detections in a classroom is also shown below. While there are a few false positives, the majority of the detections are good, and it successfully identifies most faces:
