Project 5 / Face Detection with a Sliding Window
Explanation of code
In get_positive_features I iterated over the training face images and created a hog feature for each image. I then reshaped the hog into a one-dimensional vector and added it to the positive feature array for the SVM.
In get_random_negative_features, I iterated over all of the images and randomly sampled portions of each image to get the total number of samples needed. I then created a hog feature for each sampled potion and reshaped it to be a one-dimensional vector. I then added this vector to the negative features for use by the SVM.
For the next part of the project I wrote the training data classifier. I concatenated the positive and negative features into a single feature array and then created a corresponding label array of ones and negative ones. I created the label array by creating an array initialized to ones the size of the positive training features and concatenated it with an array initialized to ones the size of the negative training features multiplied by negative one to create a negative ones array. I used the features and labels to train the vl_svmtrain with a lambda of 0.0001 (as suggested by the comments) which returned the w and b values needed to run the detector.
For each test scene in run detector, I created a sliding window that looked at a portion of the image at a time. I created a hog feature representation for every portion of the image and reshaped it into a one- directional hog vector. I used this vector and the w and b values from the svm to create a confidence level that showed how likely the portion of the image was a face (w'*hog_vector' + b). If the confidence was greater than my threshold (i varied between -1.5 and -.25 with best results at -.5) I would add the bounding box of the current sliding window to an array of bounding boxes. At the same index I added the corresponding confidence to the confidences array and the image id to the image id array. I then made sure that had detections and preformed non-max suppression on the detections. This allowed me to find the maximum detections. I added these detections to the bounding box, confidence, and image id arrays as my final detections for each image. I bounded this entire process with a loop that iterated over several scales of the given image. This allowed different sized faces to be detected with the same hog features obtained from the training images. I used scales 1, .8, (.8)^2, (.8)^3, (.8)^4, (.8)^5, .6, (.6)^2, (.6)^2, (.6)^3, (.6)^4, and (.6)^5. I determined these scales because they gave me a wide range of sizes to run the detections on and produced the best results. Prior to multiscaling I was obtaining results closer at 30.2% accuracy./p>
Results from best run
Face template HoG visualization.
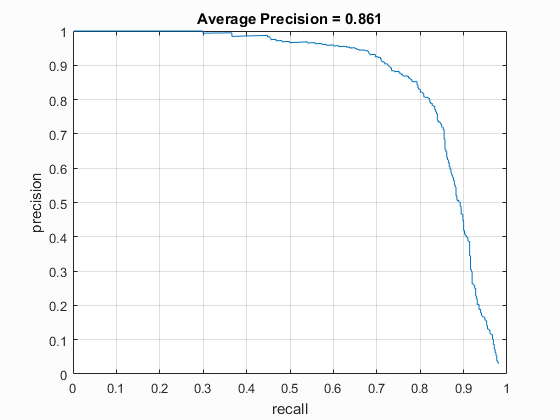
Precision Recall curve.
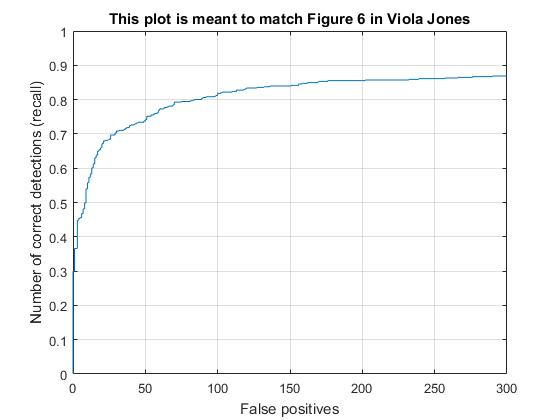
Viola Jones curve.
Example of detection on the test set.


Class Face Detection

Extra credit: up to 10 pts: Find and utilize alternative positive training data. You can either augment or replace the provided training data.
For the extra credit I augmented the dataset by mirroring all of the images and adding them back into the dataset. This doubled the number of faces I had because a face mirrored is still a face, though, due to asymmetries, will not look exactly like the original face. I then increased the number of negative training samples to match the new number of positive training samples in effort to create a threshold bound between the two that was closer to 0. I believed that this would add enough training data to create a better training model and therefore a higher accuracy. However, this did not cause my accuracies to increase at all, going from 86.1% to 84.3%. I ran the data again multiple times with different thresholds and was not able to regain my original 86.1%. I concluded that the hog feature must not be high affected by the mirrored images and that the original image and the mirrored image may not be different enough to create a significantly better model. I then found the “Collection of Facial Images: Faces 94” from Dr. Libor Spacek at the University of Essex (http://cswww.essex.ac.uk/mv/allfaces/faces94.html) this dataset had neutral, front facing images that were cropped to the side of the person’s head. I scaled these images down to the 36x36 size of the images we were using and I greyscaled the image. Since I learned before that similar faces do not enhance the dataset, I only grabbed one image from each person in the dataset. This left me with a total of 152 new images. In keeping with my mirrored images from before I mirrored all of these images to create a total additional input of 304 images. I ran the new total dataset a variety of threshold parameters and again, could not improve my original accuracy of 86.1 (scores ranging between 84% and 85%). This gives me the impression that to create a better model I need to increase the dataset by a few thousand unique faces. Similar faces and adding only a few hundred more faces does not improve the svm.
Examples of Images from the New Dataset
Origional Mirrored




New Image and Mirrored



