Project 5 / Face Detection with a Sliding Window
I got the positive training data from the Caltech Web Faces project, and the sample non-face scenes were provided from Wu et al. and the SUN scene database. I then trained the classifier with the positive training data and the negative training data utilizing a SVM. Finally I ran the detector on the testing data utilizing the output from the hyperplane generated from the SVM to classify the images. These images were tested at various scales at powers of 0.8 from the first power to the 7th power. I compared confidence of each scaled image with a threshold and only add it if it is above my threshold. Finally i perform Non-max Surpression
get_positive_features.m
In this method, i read in the directory of images and for each image, i retrieve the image, and call vl_hog on that image with the given hog_cell_size. I then reshape the image to be 1 by (feature_params.template_size / feature_params.hog_cell_size)^2 * 31, and insert it as an entry of the return array.
get_random_negative_features.m
In this method, I sampled images at random indices and convert it to a grayscale image. I then sample the images at random rows and columns and cut out a patch at that point. After that, I called vl_hog on that image patch, reshape it to be 1 by (feature_params.template_size / feature_params.hog_cell_size)^2 * 31 and insert it as an entry of my return array.
proj5.m - Train Classifier
For this section, I appended the negative features, and the positive features together, and created another array that was of the same size and was -1 for every negative feature and +1 for every positive feature in the original matrix. Finally i called vl_svmtrain on the transposed appended features matrix, the matrix of -1s and +1s, and a recommended lambda value of 0.0001
One thing that i'd like to note is that after the completion of the 3 previously said methods, these were the statistics on the training data
| Accuracy | 1.000 |
| True Positive Rate | 0.985 |
| False Positive Rate | 0 |
| True Negative Rate | 0.015 |
| False Negative Rate | 0 |
run_detector.m - Train Classifier
For this method, I iterate over every image in the directory, convert it to grayscale, and then resize the image at a scaling factor of a power of 0.8 up until the 7th power. I then call vl_hog on that resized image, and evaluate patches of size 6 (because template_size (36) / hog_cell_size is (6)). I then reshape the cell into a 1xN matrix, where N is equal to the product of all of the dimensions combined. I did this because i would need to calculate the confidence afterwards, which was done so by conf = w' * x + b;, where w and b are values outputted by the trained SVM classifier. Generally we would want the boxes with the highest confidences, so we compare it with a threshold. Mine ended up being about 1 after testing with multiple thresholds. See below for the other outcomes.
If the confidence was higher than the threshold, then i would add the confidence to the overall list of confidences, the bounding box that achieved that confidence, and finally the image in which it was achieved. I do this for all images and for every scale mentioned before. Finally, I perform Non-max supression on the accepted bounding boxes, confidences and the given image
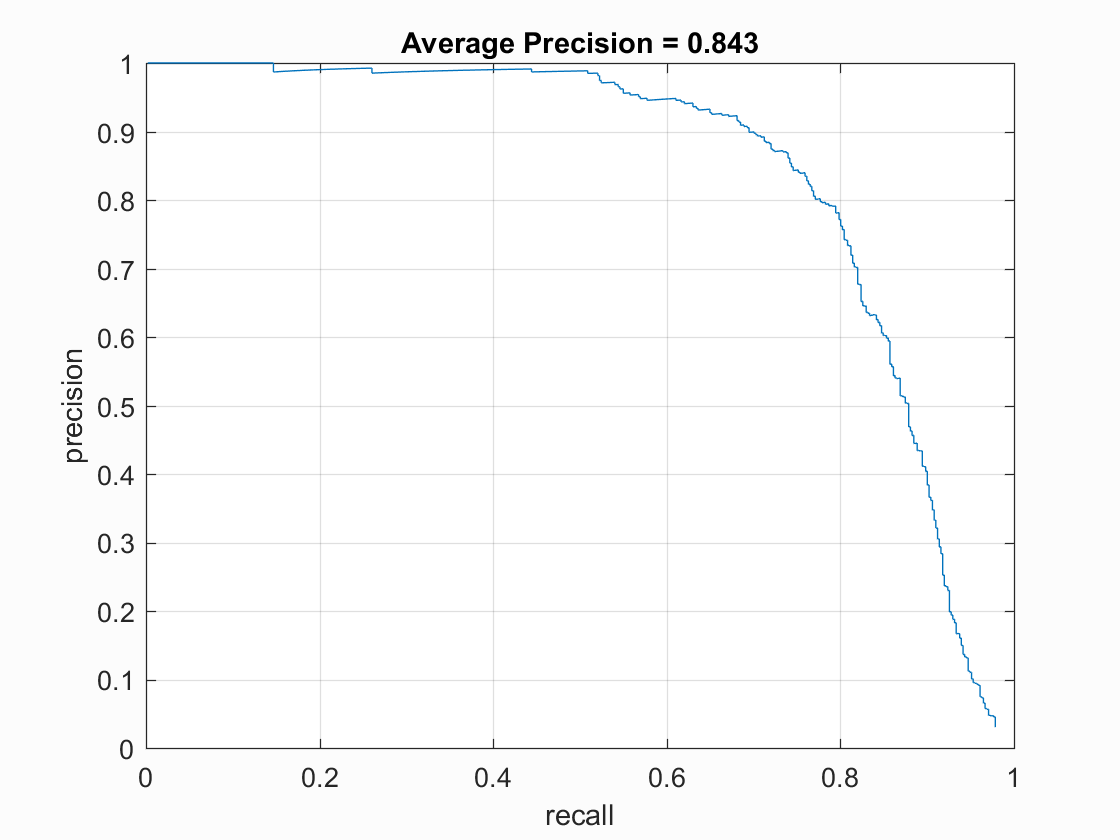
Comparison of Threshold vs AP
| Threshold | Average Precision |
|---|---|
| 0.9 | 84.3% |
| 1 | 82.3% |
| 1.1 | 81.9% |
| 1.15 | 80.2% |
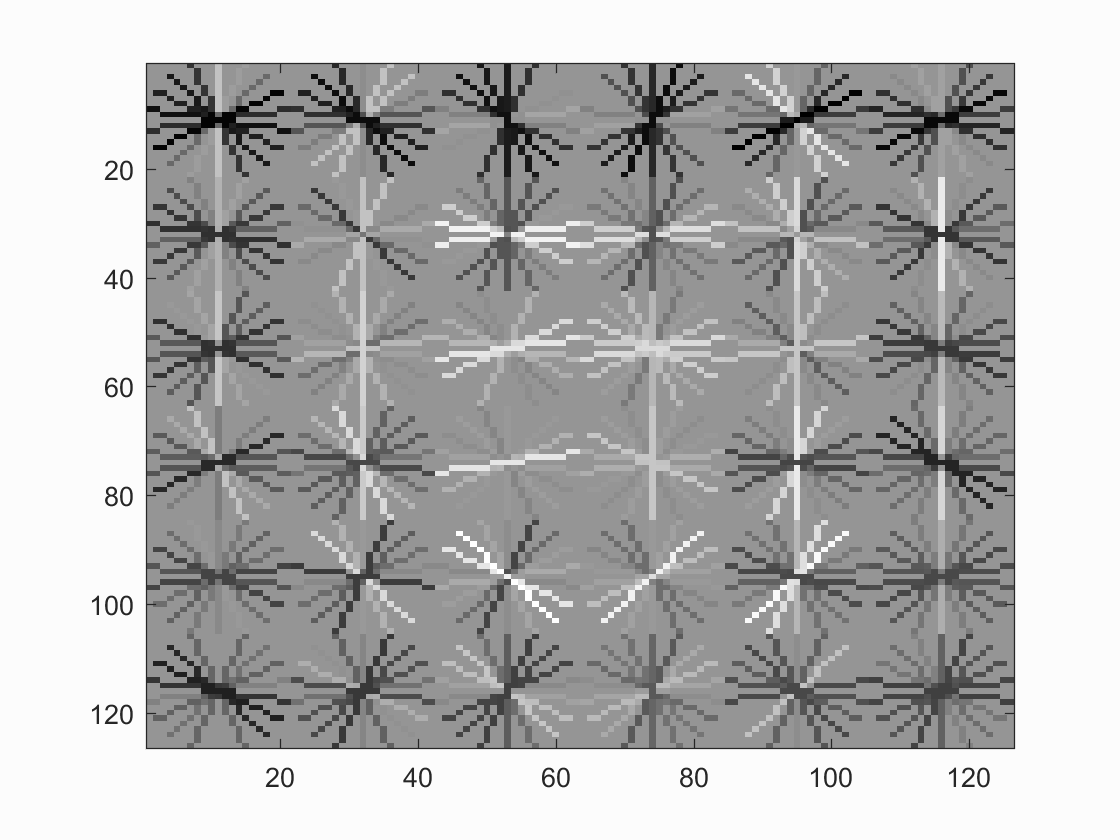
This is the face template HoG visualization, where it appears to take on the shape of a face.
Precision Recall curve for the starter code. The highest average precision achieved as 84.3%
Example of detection on the test set from the starter code.

As you can see, It was able to detect most of the faces in our group picture as well as some of the faces in the chart above! Although there were a lot of false positives especially around the legs of some people.

However, for this image, it was harder to detect the faces as a majority of them were either obscured or rotated.