Project 5 / Face Detection with a Sliding Window
This project uses sliding window to independently classify image patches as either being a face or not a face. The project is broken down into the following 4 parts:
- Get HOG features from images of faces
- Get random HOG features from other images
- Train SVM classifier using obtained features
- Run classify on each test image
- Results
Positive features
get_postive_features function takes images containing only faces and convert each of them into HOG features. HOG features of the orginal image are returned in the following code and the effects of using that of modified images are examined later.
image_files = dir( fullfile( train_path_pos, '*.jpg') ); %Caltech Faces stored as .jpg
num_images = length(image_files);
features_pos = zeros(num_images, (feature_params.template_size / feature_params.hog_cell_size)^2 * 31);
for n=1:num_images
img = im2single(imread(strcat(train_path_pos, '/', image_files(n).name)));
f = vl_hog(img, feature_params.hog_cell_size);
features_pos(n, :) = f(:);
end
Negative features
get_random_negative_features function randoms a starting x and starting y and crops out an image patch. The cropped out patches are then converted into HOG features.
image_files = dir( fullfile( non_face_scn_path, '*.jpg' ));
num_images = length(image_files);
features_neg = zeros(num_images, (feature_params.template_size / feature_params.hog_cell_size)^2 * 31);
per = ceil(num_samples / num_images);
t = feature_params.template_size;
i = 1;
for n=1:num_images
img = im2single(rgb2gray(imread(strcat(non_face_scn_path, '/', image_files(n).name))));
[h, w] = size(img);
for p=1:per
x = ceil(rand() * (w - t));
y = ceil(rand() * (h - t));
cropped = img(y:y+t-1, x:x+t-1);
f = vl_hog(cropped, feature_params.hog_cell_size);
features_neg(i,:) = f(:);
i = i+1;
end
end
SVM Classifier
The resulting positive and negative HOG features are used to build a SVM as shown below. Lambda is chosen to be 1e-4.
lambda = 1e-4;
X = [features_pos', features_neg'];
Y = [ones(length(features_pos(:, 1)),1); -1 .* ones(length(features_neg(:, 1)), 1)];
[w, b] = vl_svmtrain(X, Y, lambda);
Test Image Classification
For each test image, multiple scales are applied to resize such image to examine whether the hog cells resemble a face. For simplicity, scales of 1, 0.9, 0.8, ... to 0.1 are used. For each scale, the image is first resized using that scale. Using the resized image, the number of HOG cells are calculated. For each of the hOG cells, a patch is cropped out and converted into HOG features. The obtained feature is then classified using the w and b obtained from SVM. THe code is shown below:
for s=1:length(scales)
s_img = imresize(img, scales(s));
hog = vl_hog(s_img, feature_params.hog_cell_size);
num_w = floor(length(s_img(1, :)) / feature_params.hog_cell_size);
num_h = floor(length(s_img(:, 1)) / feature_params.hog_cell_size);
side = feature_params.template_size / feature_params.hog_cell_size;
patches = zeros((num_w - side + 1) * (num_h - side + 1), side^2 * 31);
n = 1;
for width=1:(num_w - side + 1)
for h=1:(num_h - side + 1)
patch = hog(h:(h + side - 1), width:(width + side - 1), :);
patches(n, :) = patch(:);
n = n + 1;
end
end
result = (patches * w + b);
indices = find(result > threshold);
confidence = result(indices);
cur_confidences = [cur_confidences; confidence];
x = floor(indices ./ (num_h - side + 1)) * feature_params.hog_cell_size;
y = (mod(indices, (num_h - side + 1)) - 1) * feature_params.hog_cell_size;
curscale_bboxes = [x, y, feature_params.template_size + x - 1, ...
feature_params.template_size + y - 1] ./ scales(s);
cur_bboxes = [cur_bboxes; curscale_bboxes];
curscale_image_ids = repmat({test_scenes(i).name}, size(indices, 1), 1);
cur_image_ids = [cur_image_ids; curscale_image_ids];
end
Results


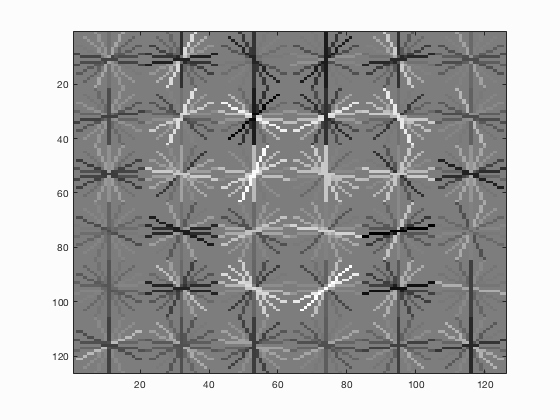
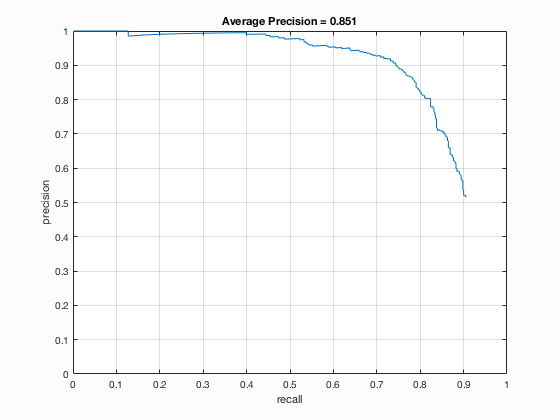
Face template HoG visualization and precision/recall graph for step size 6.
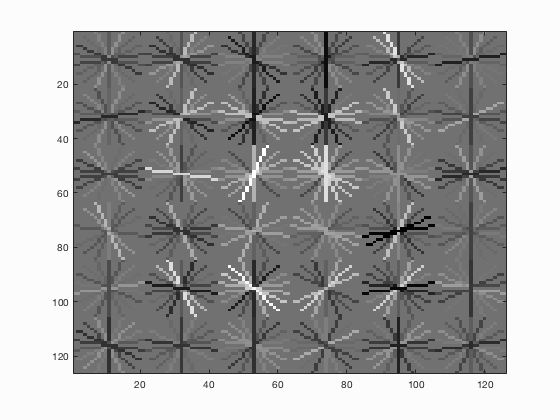
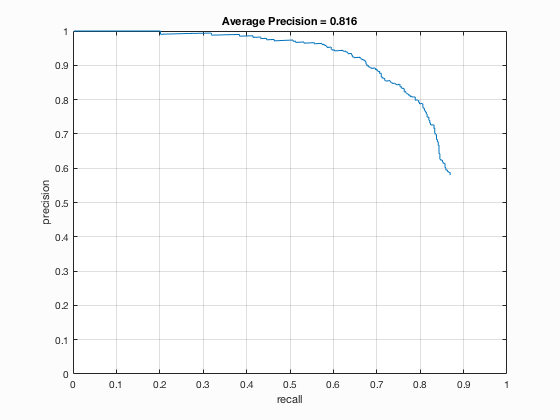
Additional positive features are added by mirroring each of the test images. This improves the average precision a bit to 85.1%. Other images transformations are also examined but none of which or combinations of them gives a better precision than 85.1%. Step size 3 is tested and an average precision of 92% is achieved.