 ).
).
The purpose of this project was to implement a simplified sliding window face detection alogorithm using histogram of gradients (HOG) feature descriptors and linear SVM classification. The face detection pipeline is first described. Then, an implementation of HOG feature descriptor is detailed. Lastly, results of the pipeline are presented for various parameter tunings.
The sliding window face detection algorithm can be broken down into the following steps:
Positive HOG Features Positive HOG feature descriptors were generated by using vl_feat to perform HOG on approximately 6700 36×36 pixel face images. The default parameters were used, resulting in HOG cells of 36 pixels with feature length 31 resulting from the UoCTTI method.
Negative HOG Features Negative HOG feature descriptors were generated using the same procedure as the positive HOG features. 35000 36×36 image patches were randomly chosen from a set of approximately 250 images not containing faces.
Classifier Training Using the positive and negative flattened HOG feature descriptors, a linear SVM was trained to classifiy image patches as either containing faces or not. For all tests, λ = 0.00001 was used.
Face Detection Face detection was performed using the trained classifier to classify sliding window image patches as either containing faces or not at multiple scales. The HOG representation of each test image was generated with the same methods used in training, and a sliding window over the HOG representation of the scaled image was classified. Scaling of the image was performed by resizing the image to 0.9α for α = 0,1,...,30. For each descriptor, classifications were rejected outright for values less than 0. Non-maximal suppression was used on the remaining classified sliding window image patches to select the bounding box that best covered the faces.
A HOG feature descriptor, based on the results of Dalal and Triggs, was implemented to satisfy the graduate requirements of the assignment. A brief description of the HOG feature description algorithm follows:
).
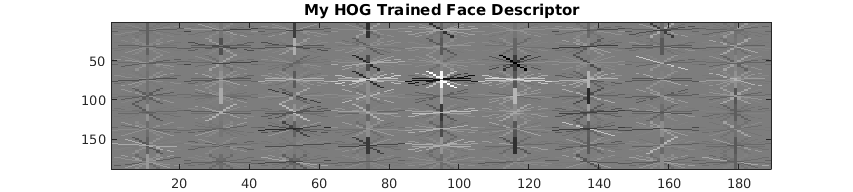
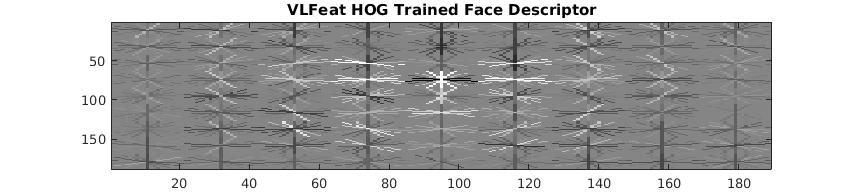
The implemented HOG was used to train the face detector shown in Figure 1 with a cell size of 4, which can be compared to the face detector generated using vl_HOG with the same cell size shown in Figure 2. While the implemented HOG face detector was viable, it used the Dalal Triggs variant–the vl_HOG face detector used the UoCTTI variant. The performance of the implemented HOG face detector was understandably worse.
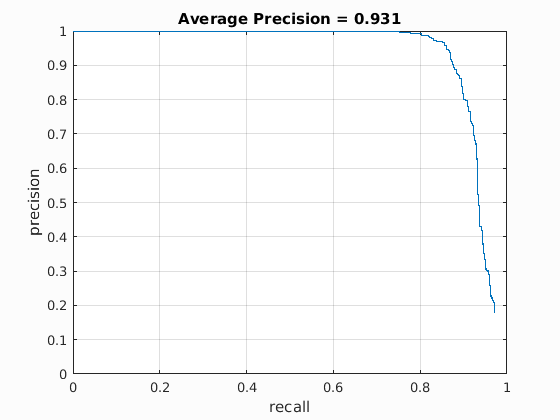
The results of the sliding window face detection using the HOG face detector are summarized in Table 1. Enormous improvements to average precision is achieved by performing face detection at multiple scales. Yet better improvements are obtained by decreasing the cell size of the HOG feature descriptor. The best average precision was 93.1% achieved with a cell size of 3; this results is captured in Figure 3. Further improvements could be achieved by decreasing the cell size to 2, but memory constraints made this infeasible for the purposes of this project.
| Method | Average Precision |
| Single Scale (Cell Size = 6) | 34.7% |
| Multiple Scale (Cell Size = 6) | 88.5% |
| Multiple Scale (Cell Size = 4) | 92.5% |
| Multiple Scale (Cell Size = 3) | 93.1% |
Face detection on the CalTech dataset can be seen in the following figures. While there are significant numbers of false positives, the vast majority of faces in the scenes are detected by the sliding window approach.
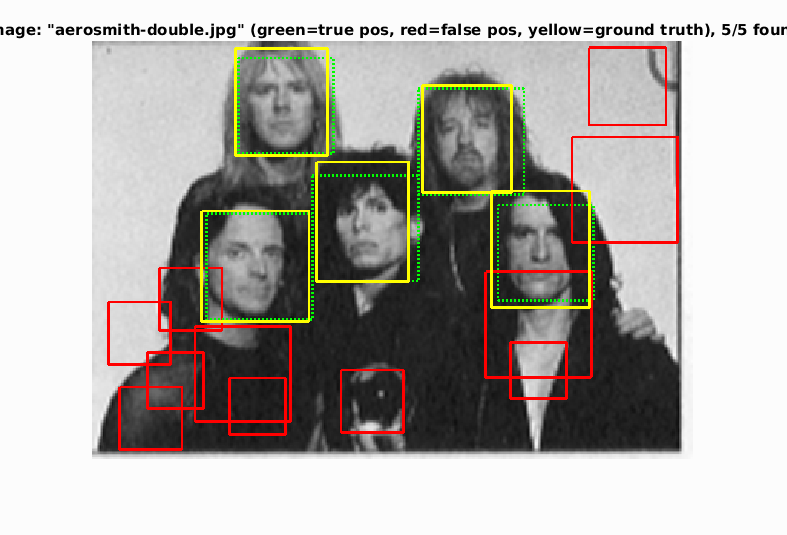







The sliding window approach to face detection by using HOG feature descriptors was successful, achieving an average precision of 93.1%. While faces were detected, the large numbers of false positives were this biggest limitation of this approach. Future work will explore probabilistically rejecting false positives.