Project 5 / Face Detection with a Sliding Window

Example of a right floating element.
In this project we attempt to create a face detector using a sliding window technique.
- get training features
- classifier training
- mining hard negatives
- run_detector()
Get Features
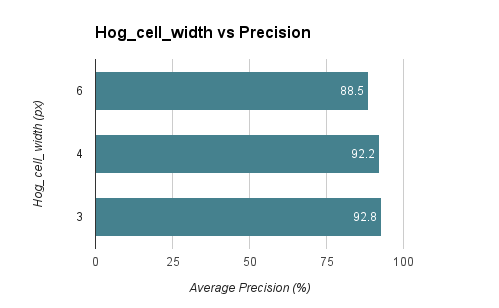
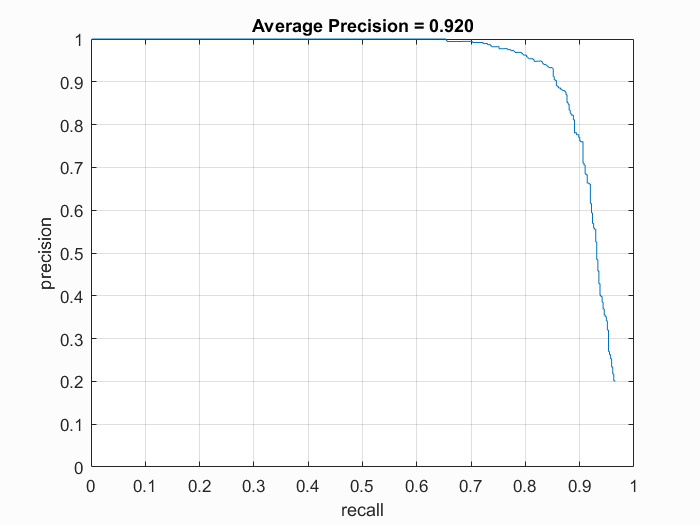
We first need to collect positive features and random negative features to train our SVM. We're given 36x36 pixel faces to use as our positive features. We're also given a collection of negative features, so we randomly pick a number of pictures and sample a random patch of pixels as our negative feature. We tried different values of hog_cell_size (6, 4, 3) and overall having a cell size of 3 was most precise with 93% average precision. This could be due to smaller cell sizes capturing more spacial information, which is important when it comes to locating face areas.
function features_pos = get_positive_features(train_path_pos, feature_params)
image_files = dir( fullfile( train_path_pos, '*.jpg') ); %Caltech Faces stored as .jpg
num_images = length(image_files);
dimensionality = (feature_params.template_size / feature_params.hog_cell_size)^2 * 31;
features_pos = zeros(num_images, dimensionality);
for i = 1:num_images
image_path = fullfile(train_path_pos, image_files(i).name);
image = single(imread(image_path));
hog = vl_hog(image, feature_params.hog_cell_size);
features_pos(i, :) = reshape(hog, [1 dimensionality]);
end
end
function features_neg = get_random_negative_features(non_face_scn_path, feature_params, num_samples)
image_files = dir( fullfile( non_face_scn_path, '*.jpg' ));
num_images = length(image_files);
dimensionality = (feature_params.template_size / feature_params.hog_cell_size)^2 * 31;
features_neg = zeros(num_samples, dimensionality);
s = 1;
while s <= num_samples
image_file = datasample(image_files, 1);
image_path = fullfile(non_face_scn_path, image_file.name);
image = single(rgb2gray(imread(image_path)));
[r, c] = size(image);
if r > 0 && c > 0
rand_row = randi(r - feature_params.template_size + 1);
rand_col = randi(c - feature_params.template_size + 1);
patch = image(rand_row:rand_row + feature_params.template_size - 1, ...
rand_col:rand_col + feature_params.template_size - 1);
hog = vl_hog(patch, feature_params.hog_cell_size);
features_neg(s, :) = reshape(hog, [1 dimensionality]);
s = s + 1;
end
end
end
Classifier Training
We use these training features to train out linear SVM. We use a lambda of 0.0001 as it was recommended and it did produce the best results during this and previous projects.
num_pos = size(features_pos, 1);
num_neg = num_negative_examples;
lambda = 0.0001;
X = [features_pos; features_neg];
Y = [ones(num_pos, 1); zeros(num_neg, 1)] * 2 - 1;
%YOU CODE classifier training. Make sure the outputs are 'w' and 'b'.
[w b] = vl_svmtrain(X', Y', lambda);
Mining Hard Negatives (EC)
Though our SVM has can test well against the training data, we decided to run our SVM through a test data of non-face pictures to find false positives. We use these false positives to retrain our SVM. We basically run our current SVM through the sliding window procedure on the non-facial test images and if there is a false positive with a high enough confidence, we save the HOG feature. After we collect our false positives, we append this data to the old features we found earlier and retrain the SVM. This code is very similar to the run_detector() code. Including hard negatives into my training actually caused the program to score less. This overtrained the SVM to throw out too many positives. Results are in the table below.
Running this process to retrain the SVM
function [features_false_pos] = false_positive_detector(non_face_scn_path, w, b, feature_params)
non_face_scenes = dir( fullfile( non_face_scn_path, '*.jpg' ));
%initialize these as empty and incrementally expand them.
bboxes = zeros(0,4);
confidences = zeros(0,1);
image_ids = cell(0,1);
SVM_CONFIDENCE_THRESH = 0.5;
template_size = feature_params.template_size;
hog_cell_size = feature_params.hog_cell_size;
patch_width = template_size / hog_cell_size;
dimensionality = (feature_params.template_size / feature_params.hog_cell_size)^2 * 31;
features_false_pos = zeros(0, dimensionality);
for i = 1:length(non_face_scenes)
fprintf('Detecting faces in %s\n', non_face_scenes(i).name)
img = imread( fullfile( non_face_scn_path, non_face_scenes(i).name ));
img = single(img)/255;
if(size(img,3) > 1)
img = rgb2gray(img);
end
cur_bboxes = zeros(0, 4);
cur_confidences = zeros(0);
cur_image_ids = {};
cur_false_pos = zeros(0, dimensionality);
scales = [1, 0.9, 0.8];
for s = scales
% Scale image
s_img = imresize(img, s);
% Hog the image
hog = vl_hog(s_img, hog_cell_size);
[rows, cols] = size(s_img);
[h_rows, h_cols, ~] = size(hog);
% Go through image in hog space
for r = 1:h_rows - patch_width + 1
for c = 1:h_cols - patch_width + 1
% Get patch and test on SVM
patch = hog(r:r + patch_width - 1, c:c + patch_width - 1, :);
patch = reshape(patch, [1 patch_width^2 * 31]);
confidence = patch * w + b;
% if good confidence, add original image coordinates
if confidence > SVM_CONFIDENCE_THRESH
tlc = ((c - 1) * hog_cell_size + 1) / s;
tlr = ((r - 1) * hog_cell_size + 1) / s;
brc = ((c + patch_width - 1) * hog_cell_size) / s;
brr = ((r + patch_width - 1) * hog_cell_size) / s;
cur_bboxes = [cur_bboxes; [tlc, tlr, brc, brr]];
cur_confidences = [cur_confidences; confidence];
cur_false_pos = [cur_false_pos; patch];
end
end
end
end
num_patches = size(cur_bboxes, 1);
cur_image_ids(1:num_patches,1) = {non_face_scenes(i).name};
%non_max_supr_bbox can actually get somewhat slow with thousands of
%initial detections. You could pre-filter the detections by confidence,
%e.g. a detection with confidence -1.1 will probably never be
%meaningful. You probably _don't_ want to threshold at 0.0, though. You
%can get higher recall with a lower threshold. You don't need to modify
%anything in non_max_supr_bbox, but you can.
[is_maximum] = non_max_supr_bbox(cur_bboxes, cur_confidences, size(img));
cur_confidences = cur_confidences(is_maximum,:);
cur_bboxes = cur_bboxes( is_maximum,:);
cur_image_ids = cur_image_ids( is_maximum,:);
cur_false_pos = cur_false_pos( is_maximum,:);
bboxes = [bboxes; cur_bboxes];
confidences = [confidences; cur_confidences];
image_ids = [image_ids; cur_image_ids];
features_false_pos = [features_false_pos; cur_false_pos];
end
Running the Detector
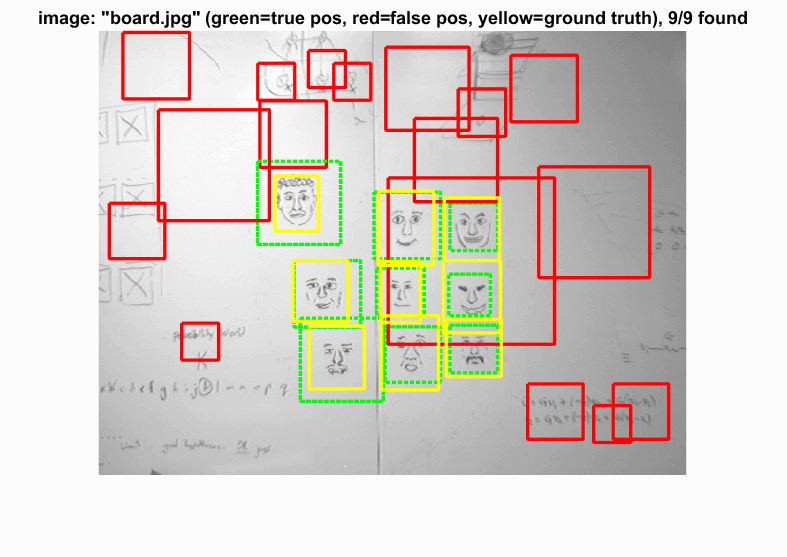
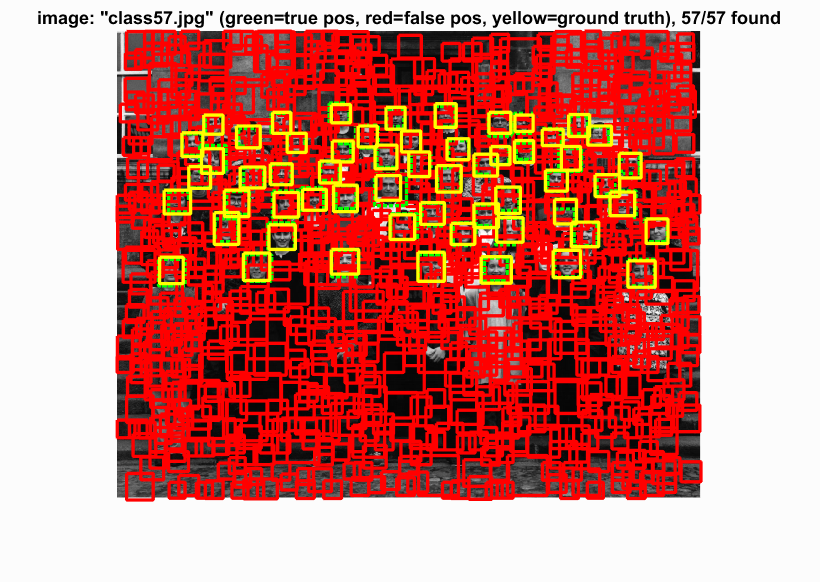
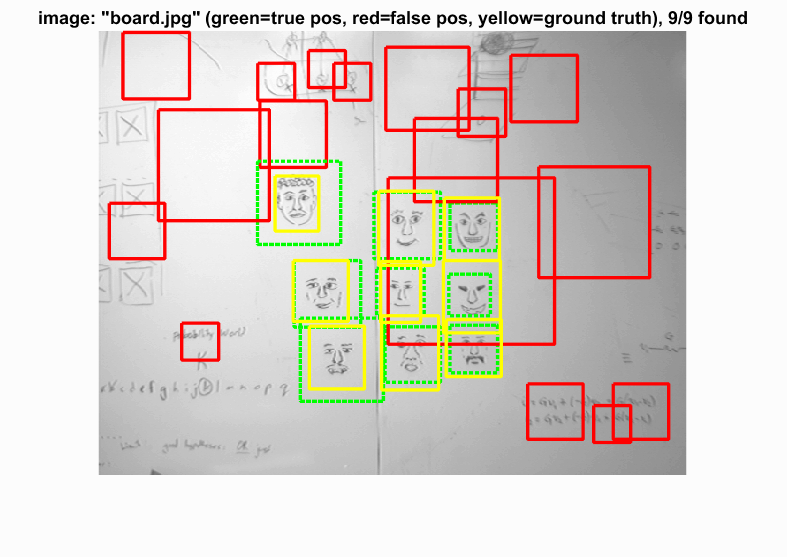
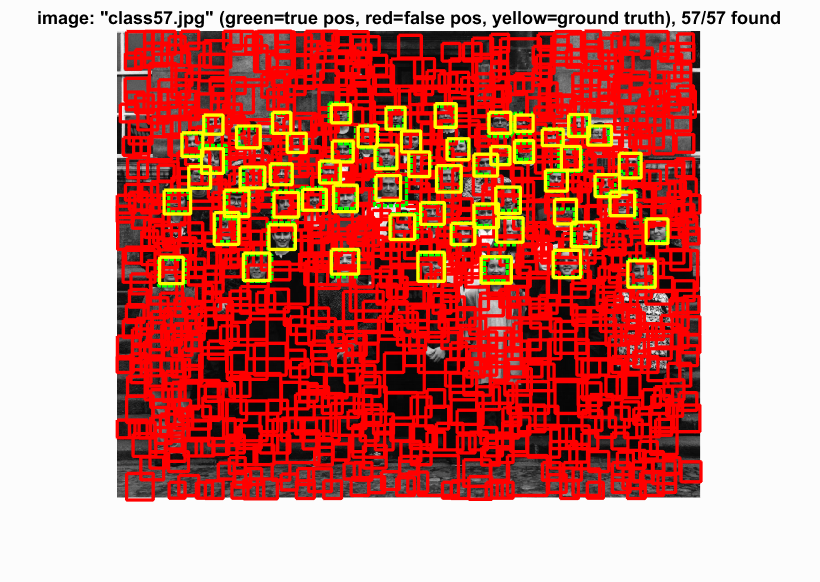
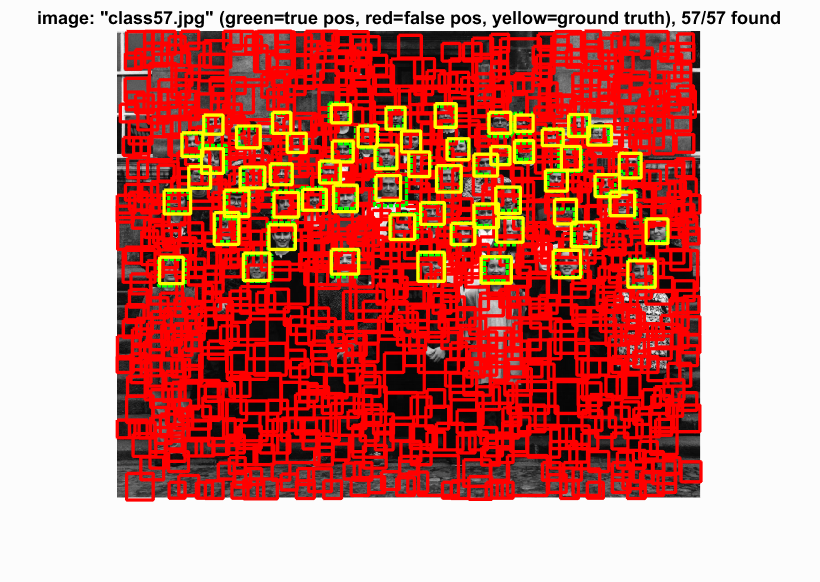
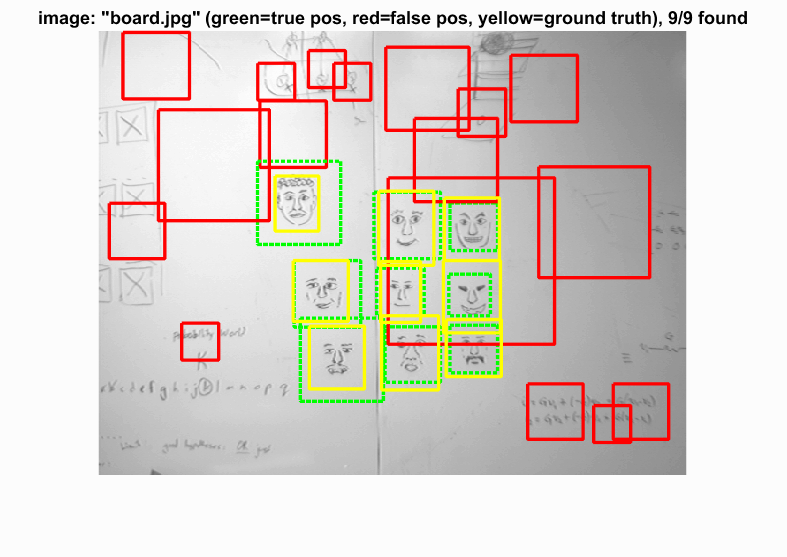
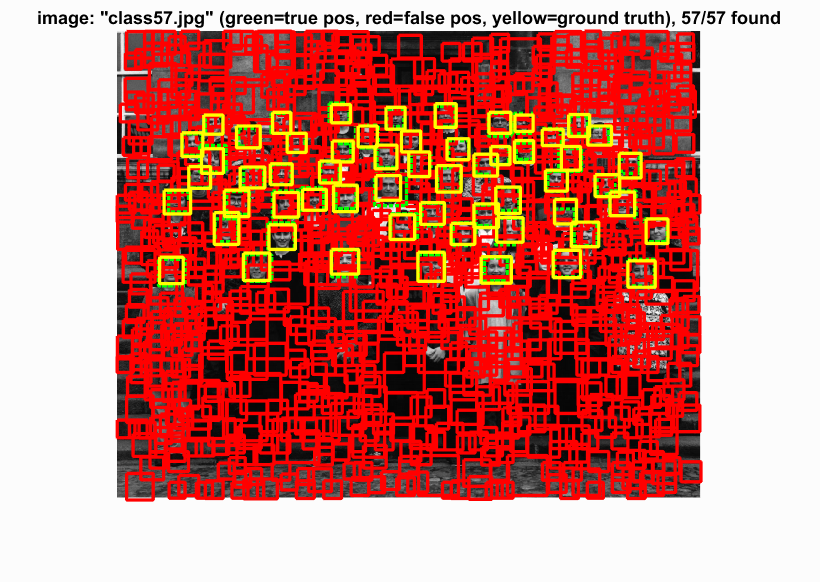
With the SVM parameters, we then run the sliding window process through our test data. We first turn the test image into HOG space, look at a window of hog features, compute the SVM with the HOG parameters, and evaluate the confidence. We kept any value greater than a threshold (-0.2). We also applied this technique to 10 different scales of the image to compensate for different close-up facial pictures. This choice to scale the image this many times may have made the cell sizes 3 and 4 have no difference. With these two cell sizes, we can see that the precision and bounding boxes are nearly identical. The HOG features must be picking up enough information to make a decision. The program also had a hard time detecting very detailed images such as audrey's image and tended to detect photos with a little blur. Because our hog template was only 36 pixels, the high frequencies cannot be accurately depicted and are lost.
function [bboxes, confidences, image_ids] = run_detector(test_scn_path, w, b, feature_params)
test_scenes = dir( fullfile( test_scn_path, '*.jpg' ));
%initialize these as empty and incrementally expand them.
bboxes = zeros(0,4);
confidences = zeros(0,1);
image_ids = cell(0,1);
SVM_CONFIDENCE_THRESH = -0.2;
template_size = feature_params.template_size;
hog_cell_size = feature_params.hog_cell_size;
patch_width = template_size / hog_cell_size;
for i = 1:length(test_scenes)
fprintf('Detecting faces in %s\n', test_scenes(i).name)
img = imread( fullfile( test_scn_path, test_scenes(i).name ));
img = single(img)/255;
if(size(img,3) > 1)
img = rgb2gray(img);
end
cur_bboxes = zeros(0, 4);
cur_confidences = zeros(0);
cur_image_ids = {};
scales = [1, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1];
for s = scales
% Scale image
s_img = imresize(img, s);
% Hog the image
hog = vl_hog(s_img, hog_cell_size);
[rows, cols] = size(s_img);
[h_rows, h_cols, ~] = size(hog);
% Go through image in hog space
for r = 1:h_rows - patch_width + 1
for c = 1:h_cols - patch_width + 1
% Get patch and test on SVM
patch = hog(r:r + patch_width - 1, c:c + patch_width - 1, :);
patch = reshape(patch, [1 patch_width^2 * 31]);
confidence = patch * w + b;
% if good confidence, add original image coordinates
if confidence > SVM_CONFIDENCE_THRESH
tlc = ((c - 1) * hog_cell_size + 1) / s;
tlr = ((r - 1) * hog_cell_size + 1) / s;
brc = ((c + patch_width - 1) * hog_cell_size) / s;
brr = ((r + patch_width - 1) * hog_cell_size) / s;
cur_bboxes = [cur_bboxes; [tlc, tlr, brc, brr]];
cur_confidences = [cur_confidences; confidence];
end
end
end
end
num_patches = size(cur_bboxes, 1);
cur_image_ids(1:num_patches,1) = {test_scenes(i).name};
[is_maximum] = non_max_supr_bbox(cur_bboxes, cur_confidences, size(img));
cur_confidences = cur_confidences(is_maximum,:);
cur_bboxes = cur_bboxes( is_maximum,:);
cur_image_ids = cur_image_ids( is_maximum,:);
bboxes = [bboxes; cur_bboxes];
confidences = [confidences; cur_confidences];
image_ids = [image_ids; cur_image_ids];
end
Results in a table
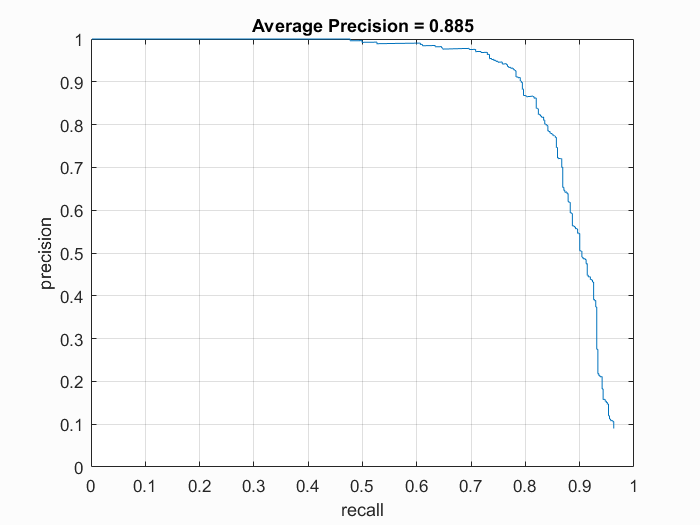
Cell Size: 6
|



|



|
Cell Size: 4
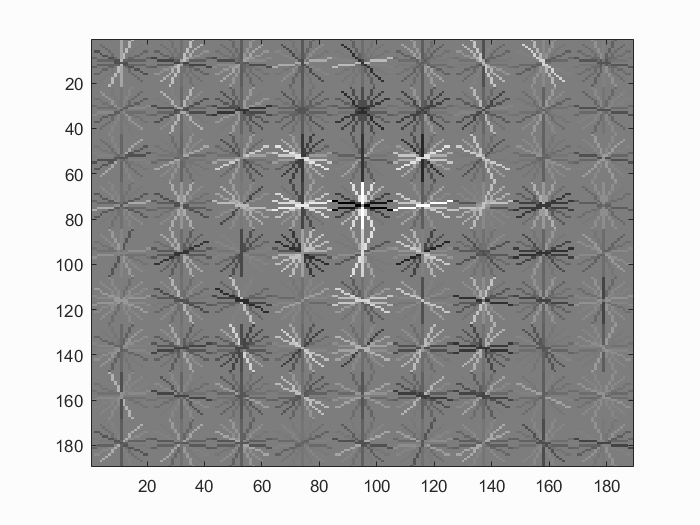
|



|



|
Cell Size: 4 with Hard Negs
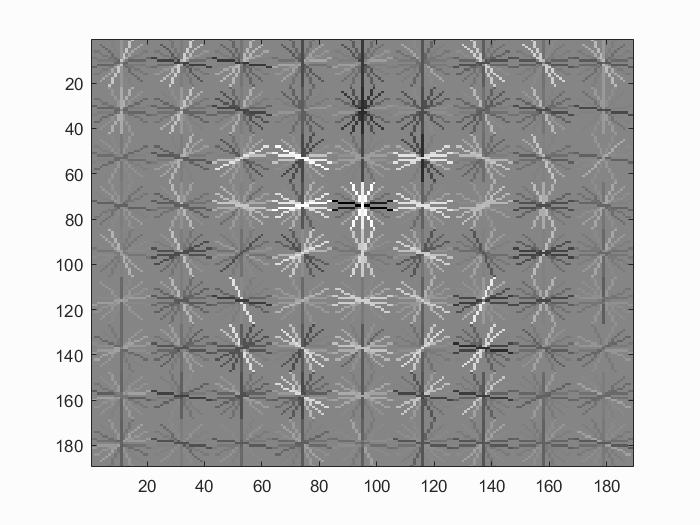
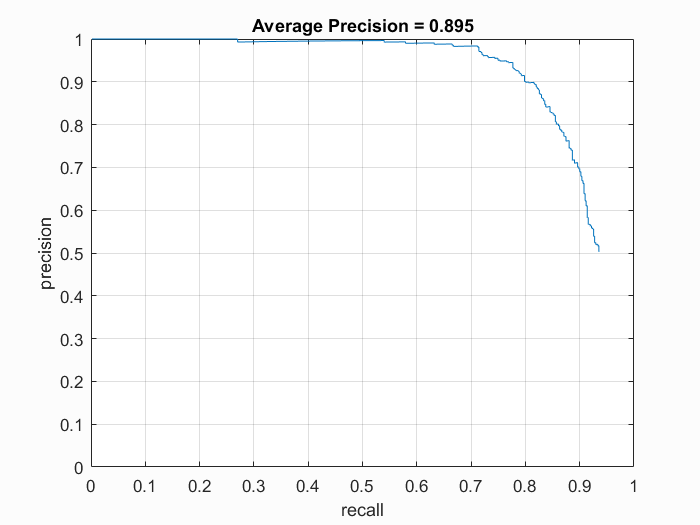
|



|



|
Cell Size: 3
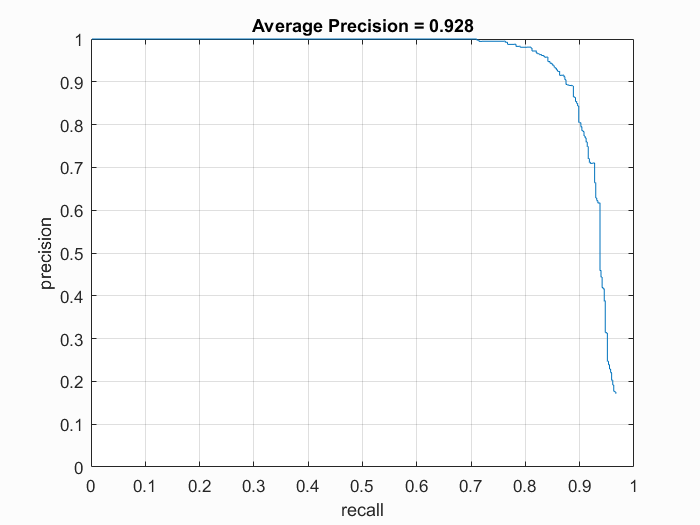
|



|



|
Class


|


|
Precision Recall curve for the starter code.
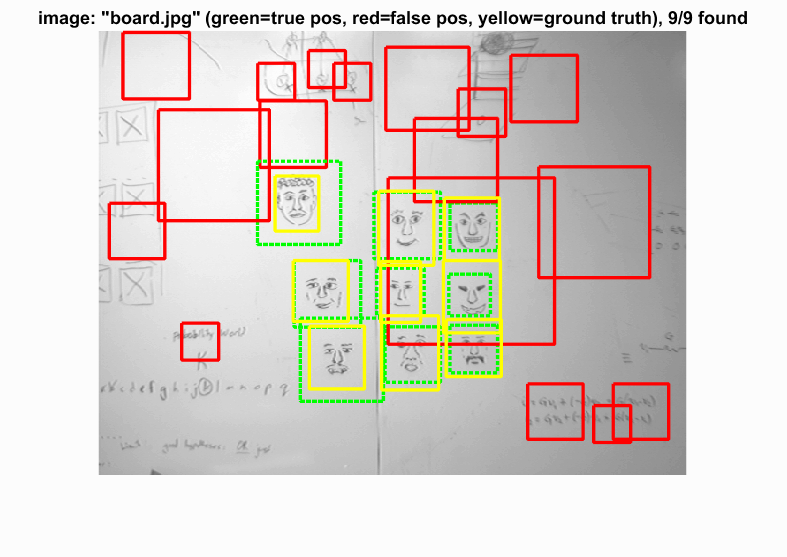
Example of detection on the test set from the starter code.
