Project 5 / Face Detection with a Sliding Window
In this project we implement face recognition with histogram of gradient (HoG) feature and linear SVM in a sliding window manner. Positive data are 6713 cropped 36x36 faces selected from Caltech Web Faces project. Negative training data are collected from Wu et al. and the SUN scene database. We use the CMU+MIT benchmark test set, which contains 130 images with 511 faces.
Extracting feature from positve images
We extract HoG feature from the 36*36 face images. HoG cell size is set to 6 pixels, producing 6*6*31 dimension feature for each image. We flatten the feature matrix and use it as the feature for each positive image. Note that due to vl_feat's requirement, image intensity should be converted to single value ranging from 0 to 1.
for i=1:num_images
image_path = fullfile(train_path_pos, image_files(i).name);
image = imread(image_path);
if length(size(image)) == 3
image = rgb2gray(image);
end
image = im2single(image);
hog = vl_hog(image, feature_params.hog_cell_size); % 6-by-6-by-31
feat = hog(:);
features_pos(i,:) = feat';
end
Extracting feature from negative images
We randomly sampled 30000 multiscale patches from negative images, i.e., images that do not contain faces. To do this, we run a sliding window with window_size and sw_step, which we set to be half the window_size. Then we sample from these crops, resize them to be 36*36 in size, and extract HoG feature from them.
window_sizes = 36*[1/2 1 2 4 10];
...
for window_size = window_sizes
sw_step = window_size/2;
num_crops = length(window_sizes) * floor((h-window_size)/sw_step) * floor((w-window_size)/sw_step);
idx_use_crop = randi(floor(samples_per_img/length(window_sizes)), 1, num_crops);
i_crop = 0;
for r = 1:sw_step:h - window_size
for c = 1:sw_step:w - window_size
i_crop = i_crop+1;
if ~isempty(find(idx_use_crop==i_crop))
patch = image(r:r+window_size-1, c:c+window_size-1);
patch = imresize(patch, [feature_params.template_size,feature_params.template_size]);
hog = vl_hog(patch, feature_params.hog_cell_size); % 6-by-6-by-31
feat = hog(:);
features_neg(count,:) = feat';
count = count + 1;
if mod(count,5000)==0
count
end
end
end
end
end
Training SVM classifier
We feed features (both positive and negative) and their labels (1 for positive, -1 for negative) into the linear SVM classifier. Lambda is tuned to be 0.00001.
feats = cat(2, features_pos', features_neg');
num_pos = size(features_pos, 1);
num_neg = size(features_neg, 1);
labels = cat(2, ones(1,num_pos), -1*ones(1,num_neg));
% num_train_data = length(labels);
% idx_train_data = randperm(num_train_data);
% [w, b] = vl_svmtrain(double(feats(idx_train_data)), double(labels(idx_train_data)), 1);
[w, b] = vl_svmtrain(feats, double(labels), 0.00001);
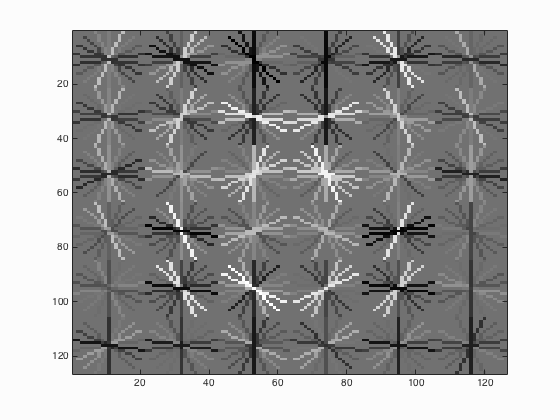
Visualizing the obtained weight w by reshaping the w vector to be 6*6*31 and utilizing matlab function imagesc. The detector shows strong response to the edges of face template.
Up to this point, as a sanity check if we multiply the trained weight with the extracted training set features and add trained bias back, we should obtain an accuracy very close to 1:
accuracy: 0.998
true positive rate: 0.069
false positive rate: 0.002
true negative rate: 0.929
false negative rate: 0.000
vl_hog: descriptor: [6 x 6 x 31]
vl_hog: glyph image: [126 x 126]
vl_hog: number of orientations: 9
vl_hog: variant: UOCTTI
Running detector on test set
We resize each test image with multiple scales, convert them into HoG feature, and crop 6*6 patches in the HoG space with sliding window manner (step size set to be 1). It worths mention that allocating the feature matrix in advance is important due to the large number of possible windows:
num_windows = sum((floor(1./scales*im_height/feature_params.template_size*feature_params.hog_cell_size) - 5) .* (floor(1./scales*im_width/feature_params.template_size*feature_params.hog_cell_size)) - 5);
feats = zeros(num_windows, (feature_params.template_size/feature_params.hog_cell_size)^2*31);
bboxes = zeros(num_windows, 4);
count = 0;
As post-processing, we threshold the confidence and apply non-max suppression to refine the detections.
ths = -0.5;
...
confidences = feats*w + b;
logic_ths = confidences > ths;
bboxes = bboxes(logic_ths,:);
confidences = confidences(logic_ths);
num_detection = length(confidences);
image_ids = cell(num_detection, 1);
image_ids(:) = {test_scenes(i).name};
is_valid_bbox = non_max_supr_bbox(bboxes, confidences, size(img));
Results in a table
Selected test images below show that this simple pipeline is robust enough to recognize extremely large faces, large number of occurance of faces, and hand drawn faces.


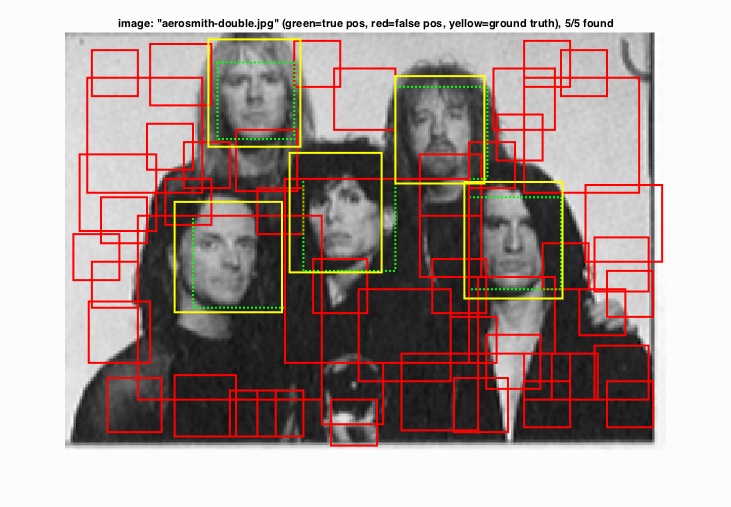

|
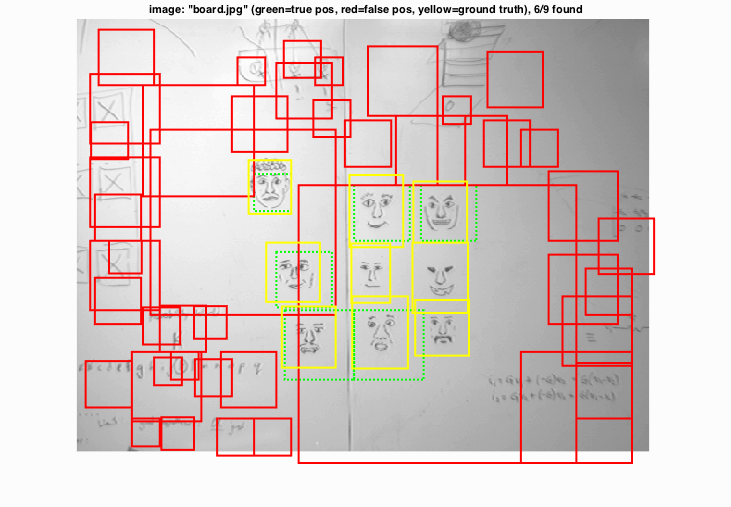



|
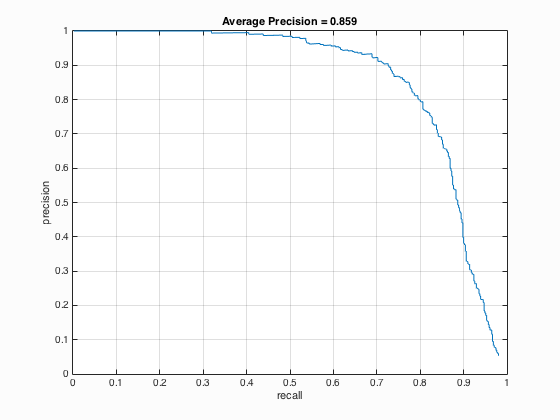
Precision Recall curve shows an average precision of 85.9%