Project 5 / Face Detection with a Sliding Window
Project 5 focused on finding faces using Dalal Triggs.
- get_postive_features.m: Positive features were obtained by converting thousands of 36x36px images of faces, obtained from a Caltech database of faces, into 36x36px sized Histogram of Gradients. The HoGs were obtained by running vl_hog from the vl_feat MATLAB library.
- get_random_negative_features.m: Negative features were obtained by randomly cutting 36x36px windows of scenes that contained no images and running them through vl_hog. In doing so we obtain HoGs of the same dimensions as our positive features, which will serve as our template HoG that we will use as a sliding window.
- classifier training: We append the positive features and negative features into a single vector, creating an apporopriate label vector of 1's and -1's. We then pass in both vectors into a Linear SVM (vl_svmtrain) to obtain W and B variables, which we can use to classify potential faces.
- run_detector.m: The bulk of the project lies here. This is where we downscale the image to various sizes, convert the scaled image into an HoG, run our template HoG over the scaled image HoG using sliding window, thresholding with a certain confidence value, perform non-maximum-supression, and finally obtain facial bounding boxes and confidences for each image file.
Results
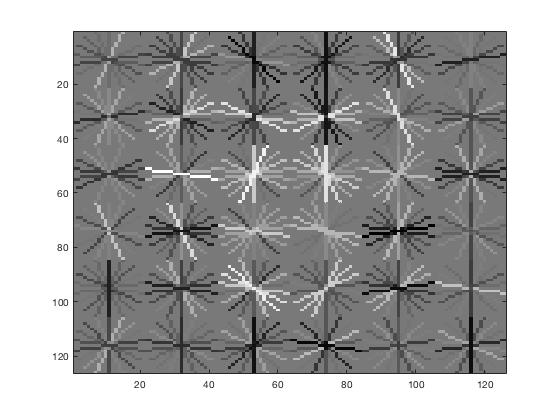
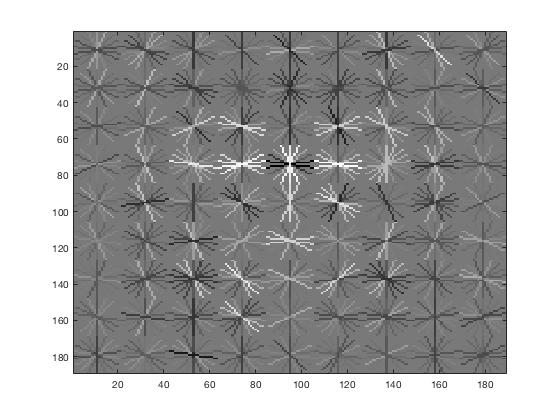
With a cell size of 6px, the resulting HoG template (left) has features that resemble faces. The upper center of the face tends to have vertical accentuation, whereas the tops and the lower sides of the faces are unlikely to have horizontal features. With a cell size of 4px (right), the features become more defined, more focused around the area around the eyes. Eyebrows are angled downwards, eyes are horizontal, and the nose bridge is vertical.
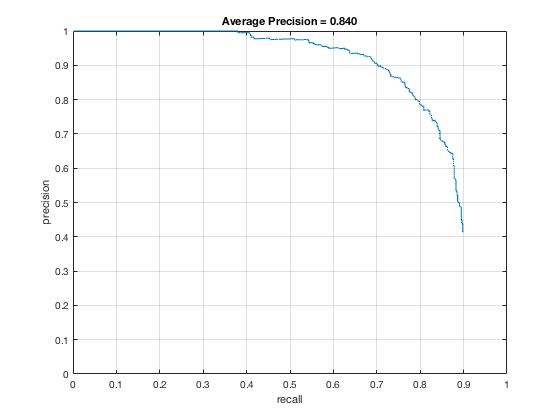
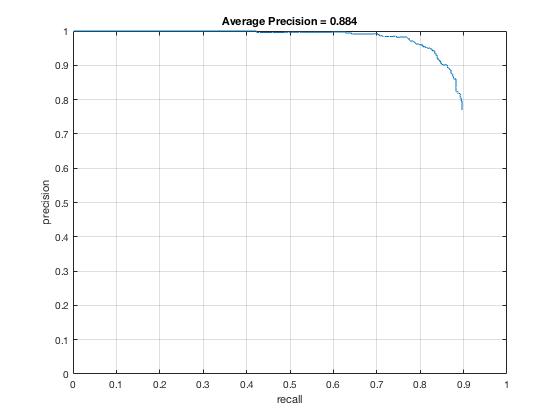
From the 6px precision-recall graph (left), we see that precision starts falling off drastically as we reach 70% recall. At about 88% recall, our precision hits 50%. At that point, we would have as many false positives as true postiives. The average accuracy was .840. For the 4px precision-recall graph on the right, we see that the precision holds up until around 85% recall where it starts to fall off drastically. Using a smaller cell size allows for finer-grained sliding window alignments, which was the largest problem with the HoG template matching.

Although a face like this would seem straightfoward to recognize, the difficulty was due to scaling. Our template was only 36x36px which meant that the image had to be scaled down significantly and the HoG cells needed to align nicely with the face. It is also interesting to see that the algorithm found some of the circular objects in the background as false postiives. The circular figures have very slight vertical features in the center, with a lack of horizonal features near the bottom sides, which align enough with our facial template.
Extra Results




Forward, simple faces were easy to find. When there were very few faces that were detectable, the algorithm starts finding faces in odd places. Without confident facial recognition an image, non-maximum-supression is less able to throw out obvious non-faces.