Project 5 / Face Detection with a Sliding Window
One of the classic tasks of computer vision is to detect faces. The first truly successful approach was outlined by Viola and Jones. They showed how a data driven approach using machine learning and hand selected features gave a new benchmark in accuracy while running quickly enough to be deployed in cameras. Dalal and Triggs improved upon this approach using a support vector machine (SVM) and histogram of oriented gradients (HOG) as image features. I will outline my implementation of this agorithm and share some results.
Image Representation
Many different approaches exist to represent images for efficient manipulation in tasks like recognition. Many of the hand selected features involve tallying image gradients. HOG features are no different. To find HOG features, you look at small chunks in an image and create a histogram of the gradients. When taken throughout the image, this gives a good approximating of the stucture of the image.
In my implementation, I used HOG cell of size 6, meaning each histogram was calculated over a 6x6 area. Smalled cell sizes can lead to greater accuracy, at the cost of computational time. Within each histogram, there 31 different directions, so the dimensionality of each cell is the cell size squared times 31.
Dilal Trigs Algorithm
Dilal Trigs uses the HOG features of various training images to "learn" what features correlate with faces and what features do not. Given enough data to train, a linear classifier can then be applied directly to the HOG features of a new image to determine if it contains a face.
In my implementation, I use an SVM to classify HOG features. For positive examples, I extract HOG features from images containing faces with HOG template size of 36 and HOG cell size of 6. For negative examples, I sample HOG features from images that do not contain faces. Given that these negative examples are images with various sizes, I randomly choose an image patch of size 36 to extract the HOG features from. For the SVM, I use a reguralization constant of lambda = 0.00006.
One of the nice things about this approach is that we can visualize the direction of gradients the SVM responds to at various places in an image. This represents the generic representation of a face. An image of the weights that my SVM learned are shown below. If you squint, you can see a vague outline of a face.
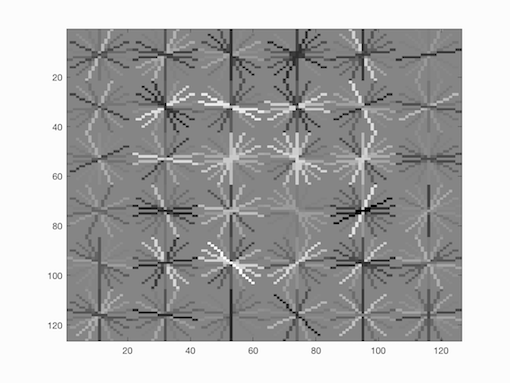
Learned Face Representation.
As a quick note, once trained, the SVM could classify everything in the training set with 100% accuracy as expected. As we'll see, it struggles a bit more with test set.
Detecting Faces
To detect faces, I use a sliding window approach at different scales to capture size differences. Specifically, I start at the smallest scale that allows the image to still contain a 36x36 template, and increment the scale by 0.05 until I reach the original scale of the image. At each scale, I slide a window of size 36x36 over the entire image, classifying that particular window according to its HOG features. Any window with confidence 0.95 or greater is kept as a window contaning a face.
Results
When trained over the CMU-MIT dataset, my implementation achieved an average precision of 0.876, as shown in the graph below. As expected the precision goes down considerably as recall increases, as the algorithm must consider more difficult matches in order to find all faces.
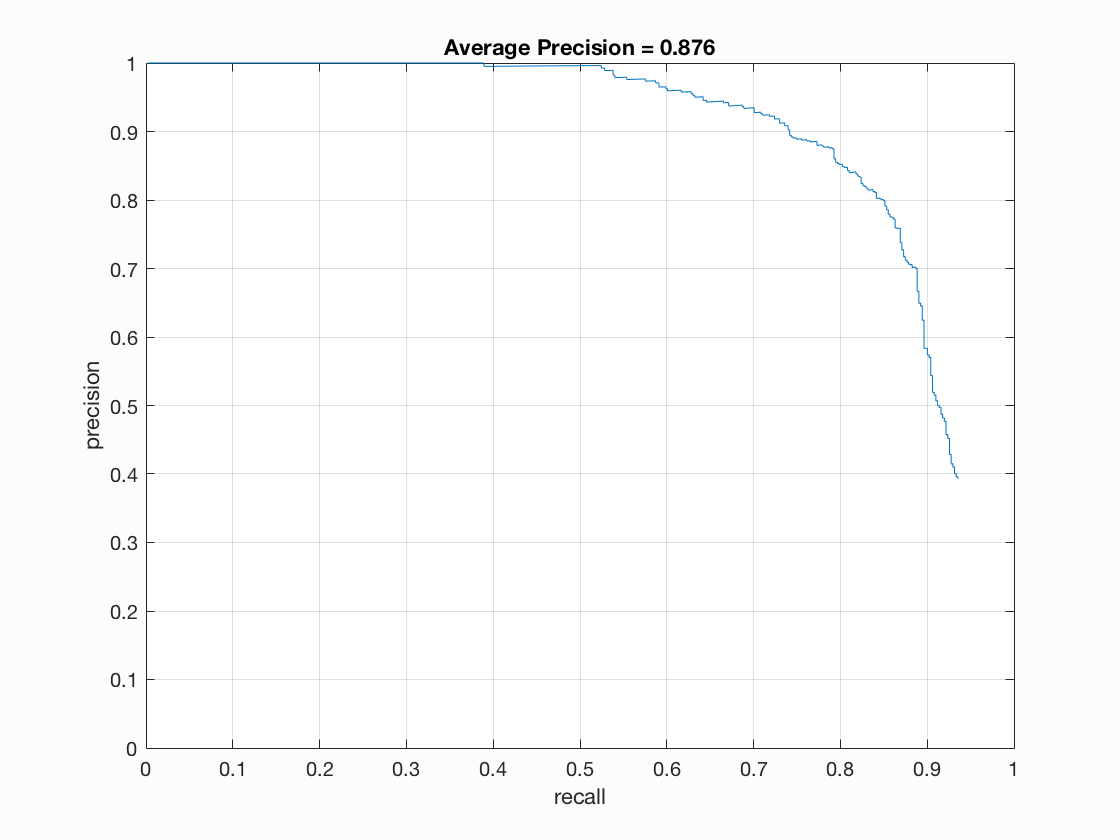
Learned Face Representation.
In terms of qualitative performance, we can see that the algorithm does well in relatively optimal conditions. For the class photo, the algorithm easily detects all the faces, even those in the photo on the projector. The same can be said for the Star Trek crew and the individual woman. Where the algorithm seems to have trouble is in regions of high contrast. For instance, the badges of the star trek crew are seen as faces, along with wrinkles in the jeans of some students. A few people's hands and legs trick the algorithm as well. This makes sense, considering the algorithm only naively looks for regions with gradients roughly similar to those of faces.

Dilal Trigs on the Class Photo.

Dilal Trigs on an Individual Woman.

Dilal Trigs on the Star Trek Crew.
To show some images which the algorithm doesn't do as well on, consider the same class photo, just under more difficult conditions, with students not looking directly at the camera or with some sort of object obscuring their face. While the algorithm still picks up some faces, many faces that are essentially unobstructed are now missed. This is because the template is not trained to be flexible and take into account occlusion or different angles of views. Similarly, in a lower resolution, the algorithm picks out many trivial regions of image intensity change as faces, even though these clearly bear little resemblance to a face.

Dilal Trigs on Hard Class Photo.

Dilal Trigs on Class 57.
Overall, the algorithm does a fine job under decent settings, but clearly needs further refinement to deal with more difficult scenarios.