Project 5 / Face Detection with a Sliding Window
This project attempts to use a sliding window detector to identify faces in images. First, images of faces are used to generate a positive set of HoG features. A set of non-face images are then used to generate a negative set of HoG features. These positive and negative features are then used to build an SVM classifer.
The next part of this project is to use the SVM classifier to detect faces in new images. The sliding window detector creates HoG features at multiple scales in these images and classifies each cell using the classifier. The cells with the highest confidence are then passed to a non-maximum supression function, and the detected faces are returned with bounding boxes.
 Results from my Face Detector
Results from my Face Detector
Positive Features
To generate an effective classifier, features needed to be extracted from images of known faces. The input dataset was the Caltech Web Faces set, which contains 6713 cropped faces. For every face, a HoG feature (cell_size=6) were generated from each 36x36 image , as well as it's mirror reflection. Adding the mirror image to the positive dataset increased average precision by .01.
Negative Features
Feature of non-faces are needed so the classifier can see examples of what is not a face. In my tests, I used 10000 negative examples. My algorithm sampled every image in the dataset at random scales and positions of 36x36 patches to provide enough randomness and coverage of the input images. Adding scale randomization increased average precision by .05. Increasing the number of examples only slightly increased precision, and significantly increased runtime.
Classifier Training
The combination of positive and negative features was used to create an SVM classifier (lambda=0.0001). The classifier performed with .999 accuracy on the training data with .000 false positive and false negative rates.
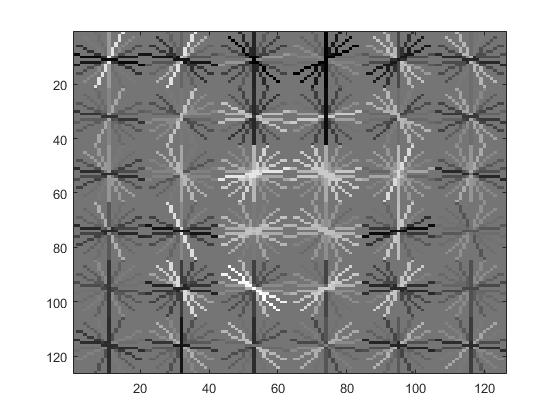 Histogram of Gradients Face Detector
Histogram of Gradients Face Detector
Sliding-Window Feature Detector
A multi-scale sliding window feature detector was created to identify faces in images. At each scale (0.9 downscaling each iteration), each input image was used to create a HoG feature representation. Each group of 6x6 cells (the templates were 36x36 pixels, and the cells were 6x6 pixel, so 6 cells were needed to span an entire template) was classified using the SVM classifier to generate a confidence in that group of cells being a face. If a confidence was less than 1, the feature was discarded. This was done for each scale until the image was no longer more than 36x36. The confidences and bounding boxes for each feature were passed into the provided non-maximum supression function, which returned a set of non-overlapping bounding boxes. The resulting bounding boxes were used to identify which parts of the images were faces. Below are the results of the detector.
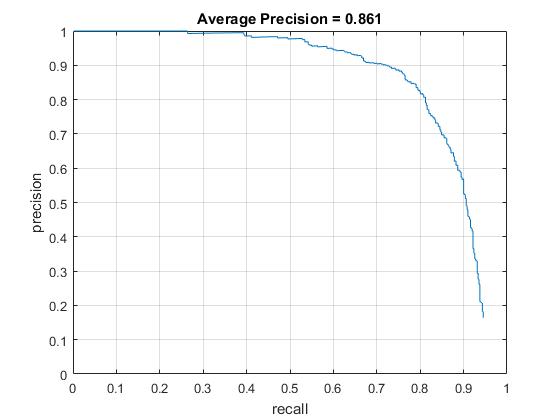 Precision of the Feature Detector vs. Recall Precision sharply decreases as recall increases.
Precision of the Feature Detector vs. Recall Precision sharply decreases as recall increases.
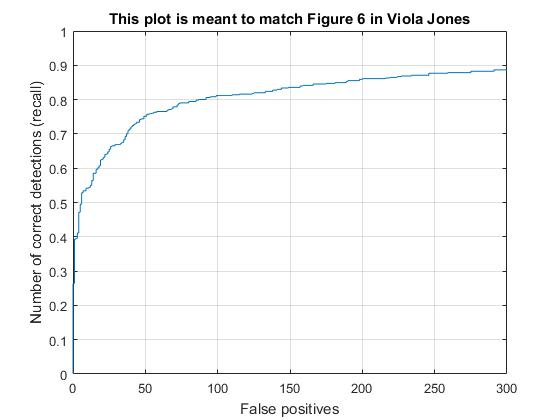 Recall vs. False Positives As the recall increases, the number of false positives also increases.
Face Detection on the Argeninian Soccer Team In this image, all 11 faces were correctly identified, but there are also a large number of false positives throughout the image.
Recall vs. False Positives As the recall increases, the number of false positives also increases.
Face Detection on the Argeninian Soccer Team In this image, all 11 faces were correctly identified, but there are also a large number of false positives throughout the image.
 Face Detection on Audrey Hepburn In this image, there are many face detections, none of which are actually her face
Face Detection on Audrey Hepburn In this image, there are many face detections, none of which are actually her face