Project 5 / Face Detection with a Sliding Window
In this project, I implemented face detection. I trained an SVM with a training set with examples of faces and non faces. Image are represented as Histograms of Gradients (HoG features). The first part of the pipeline is loading thousands of positive training examples and converting them to HoG features. The next step is sampling many random negative features (features without faces). Next, the svm is trained with these positive and negative examples. Next, the trained SVM is used in test images to detect candidate faces on a sliding window at various scales.
Getting Positive Features
Positive training examples were sampled using vl_hog(). I used the entire training set.
Getting Random Negative Features
I sampled about 10000 negative features for training the SVM. Sampling was done without replacement. I found that increases in the number of negative features sampled over 10000 did not drastically improve results.
Classifier Training
Training an SVM was done using vl_trainsvm(). I chose a lambda of .0001 because that gave me the best average precision.
[w b] = vl_svmtrain(combined_features, combined_labels, lambda);
Run Classifier
For finding instances of faces among the testing images, I found that a minimum confidence of -0.5 was best. I chose a template size of 36 and a hog cell size of 6. I sample the image with a sliding window at a starting scale of 1.0, and then .85 and then .85 * .85 and so on until the image is too small to search for faces. Using a smaller scale step did not improve results much, but did increase runtime a lot. Here's the relevant code for multi-scale classification.
scale = 1.0; % the current scale of the img compared to the original
scale_mult = .85; % what to multiply the current scale by to get the next scale
%loop through the scales
while min(size(img)) > feature_params.template_size
%convert img to HoG feature space
hog_img = vl_hog(im2single(img), feature_params.hog_cell_size);
hog_template_size = feature_params.template_size / feature_params.hog_cell_size;
%iterate through all (most) possible patches
for row = 1:(size(hog_img, 1) - hog_template_size)
for col = 1:(size(hog_img, 2) - hog_template_size)
% get the subsection of the hog img
hog_img_subsection = hog_img(row:row + hog_template_size - 1, col:col + hog_template_size - 1, :);
hog_img_subsection_flattened = reshape(hog_img_subsection, 1, hog_template_size^2 * 31);
% evaluate the subsection of the hog img against the svm
confidence = dot(w, hog_img_subsection_flattened) + b; %for some reason dot works but * doesnt
if confidence > MIN_CONFIDENCE %keep
x_min = (col - 1) * feature_params.hog_cell_size + 1;
y_min = (row - 1) * feature_params.hog_cell_size + 1;
x_max = x_min + feature_params.template_size - 1;
y_max = y_min + feature_params.template_size - 1;
% reverse the scale to get the original coordinates
x_min = x_min / scale;
y_min = y_min / scale;
x_max = x_max / scale;
y_max = y_max / scale;
cur_bboxes = [cur_bboxes; x_min y_min x_max y_max];
cur_confidences = [cur_confidences; confidence];
cur_image_ids = [cur_image_ids; test_scenes(i).name];
end
end
end
scale = scale * scale_mult;
img = imresize(img, scale_mult);
end
Every candidate region found by the code above is given to the non-maximum supression function to get rid of duplicate matches like so:
[is_maximum] = non_max_supr_bbox(cur_bboxes, cur_confidences, original_image_size);
Results
I achieved an average precision of 84.1%
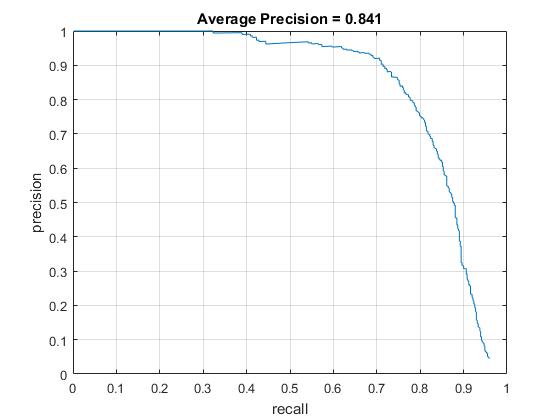
My learned face/head detector looked like this:
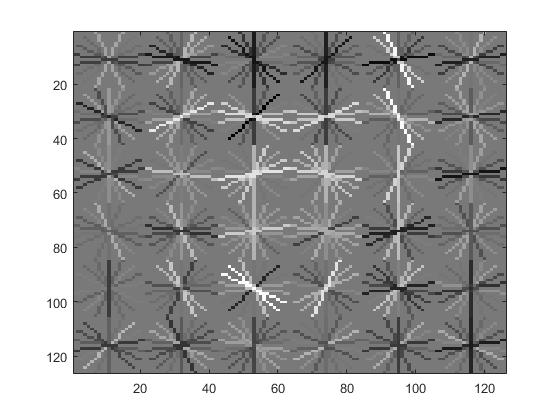
Here's the recall/false positive curve. You can see it leveling off at about 85%.
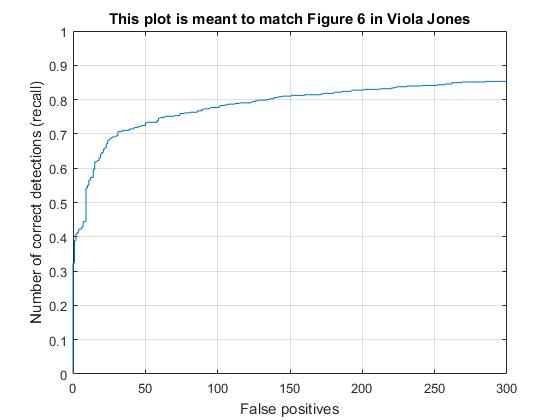
Thanks to looking for faces on multiple scales, I was able to detect faces in a scale-invariant fashion.


Although there were many false positives for every test image, true positives almost always had a higher confidence than the false-positives
Here are the highest-confidence detections for our class. I set the confidence threshold to 1.5 for the photo of our class to filter out most of the false positives. I also resized the photo to be smaller in an image editing program, so that the algorithm would run faster.

And some other classes


