Project 5 / Face Detection with a Sliding Window

Example of a right floating element.
For this project I implemented a face detection system. The system uses hog features to train and detect faces using a support vector machine classifier.
- Collect Positive Features
- Collect Negative Features
- Train SVM Face Classifier
- Implement the face detector for test images
- Extra Credit: Use a different database of positive training images
Collect Positive Features
For each positive training image, I extracted hog features and flattened the features into a one dimensional array.
Collect Negative Features
A number num_samples was given as an input to this function which determined how many hog feature samples to have. For num_samples times, I picked a random image from the negative training data. Then I took the upper left most 36 X 36 patch of the image and extracted the hog features from it, and flattened the features into a one dimensional array.
Train SVM Face Classifier
To train the classifier I concatenated the features I extracted from the negative and positive training examples. Then I created an array of binary training labels. I fed the features and labels into an SVM classifier to train it. For my lambda I used .000001.
Implement the face detector for test images
Each test image was had dectections run on it for 12 different sizes. For each test image, the image was tested at 12 scales, where each scale was .9 the size of the last scale. At each scale the hog features were extracted from the image. Then using a sliding window, where the size depended on the size of the hog cell size, over the hog features the system tested for faces. The hog features where run through the trained SVM and if the confidence was above a confidence threshold, which I defined as -.5, then the part of the image corresponding to those hog features was kept as a detected face for that image. After running through all the test images, non-max suppression was preformed resulting in a lower number of detected faces per image.
Extra Credit: Use a different database of positive training images
I experiemented with using a different database of positive training images. The positive traning images supplied to us was the Caltech faces dataset. I choose to use the "Labeled Faces in the Wild" dataset from MIT. This dataset has images of famous persons and celebrites. There are a total of 5749 people in the dataset and a total of 13233 images, since some people have more then one image of their face in the dataset. I had to run through all the images in the dataset and convert the images to grayscale and resize them to 36X36. Since the images were mostly just the face I did not have to crop the images. This is an example of an image of the famous tennis player Serena Williams, this is before gray scale and crop because that would be annoyingly small and hard to see.

Results
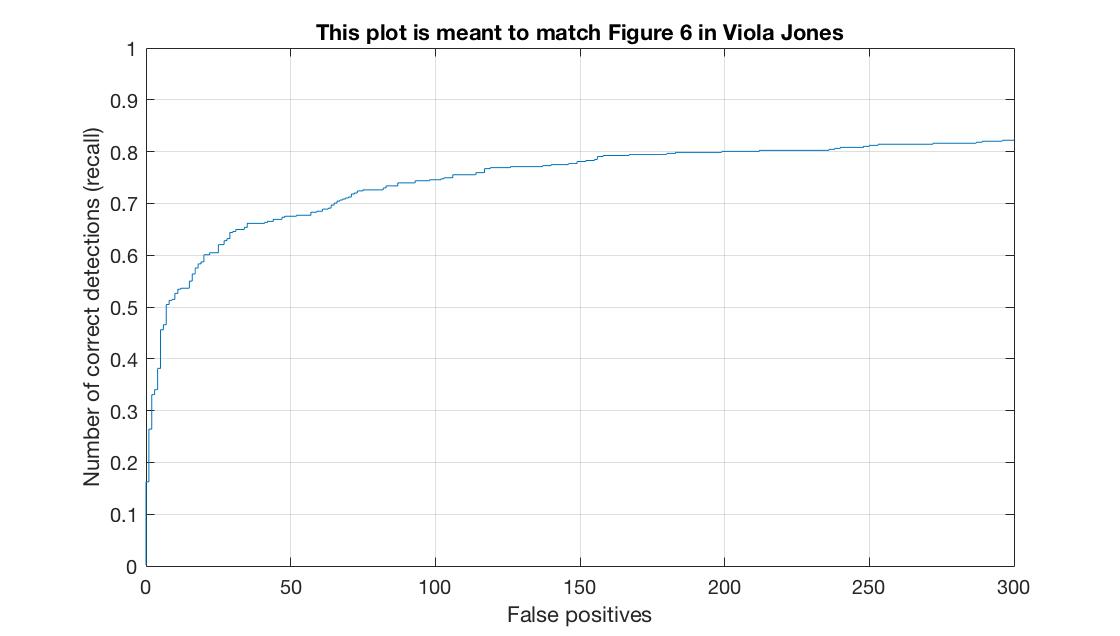
The results running the detector at only a single scale and using a 6 hog cell size. Average Precision = .279
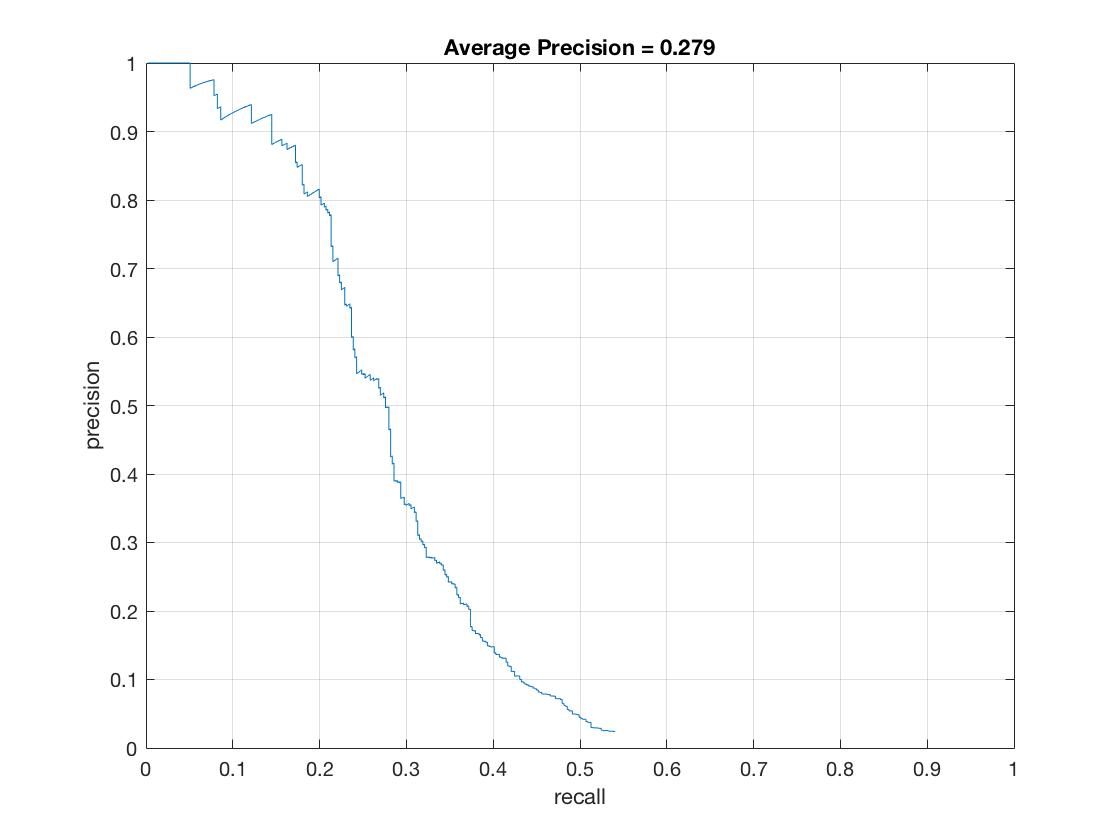
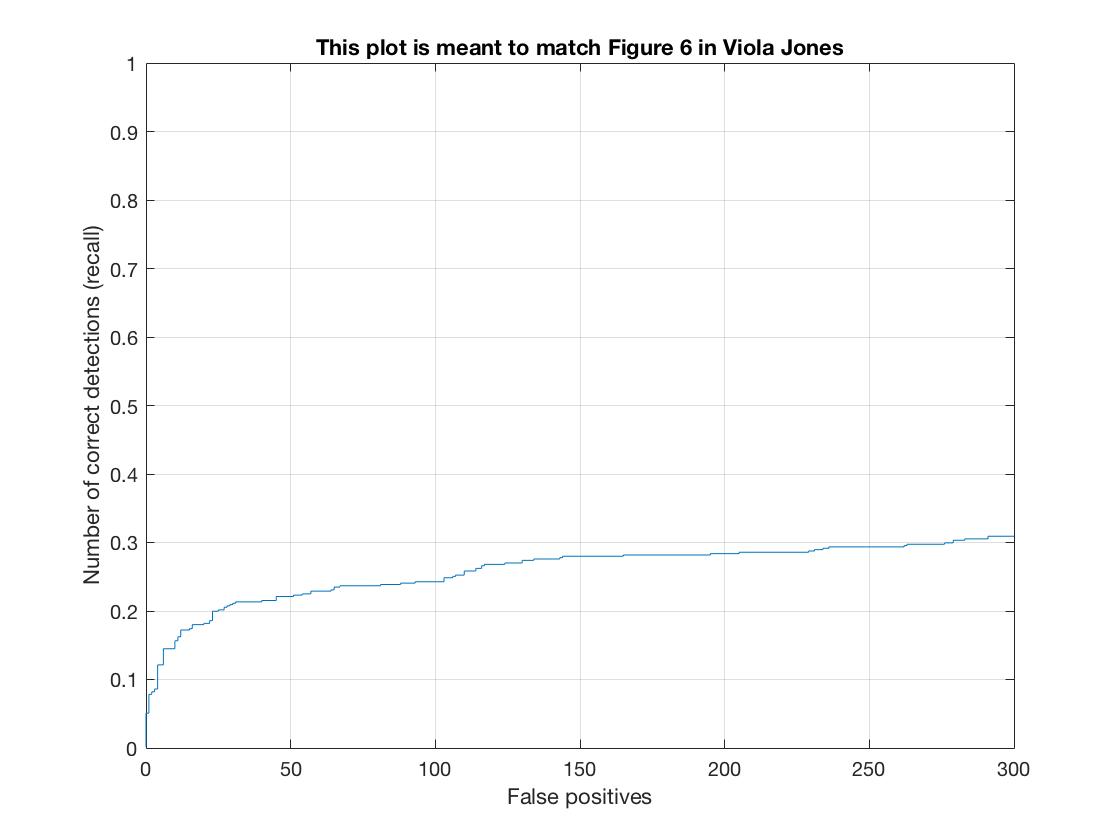
|
The results running the detector at 12 scales, downsizing the image by .9 each time and using a 6 hog cell size. Average Precision = .799
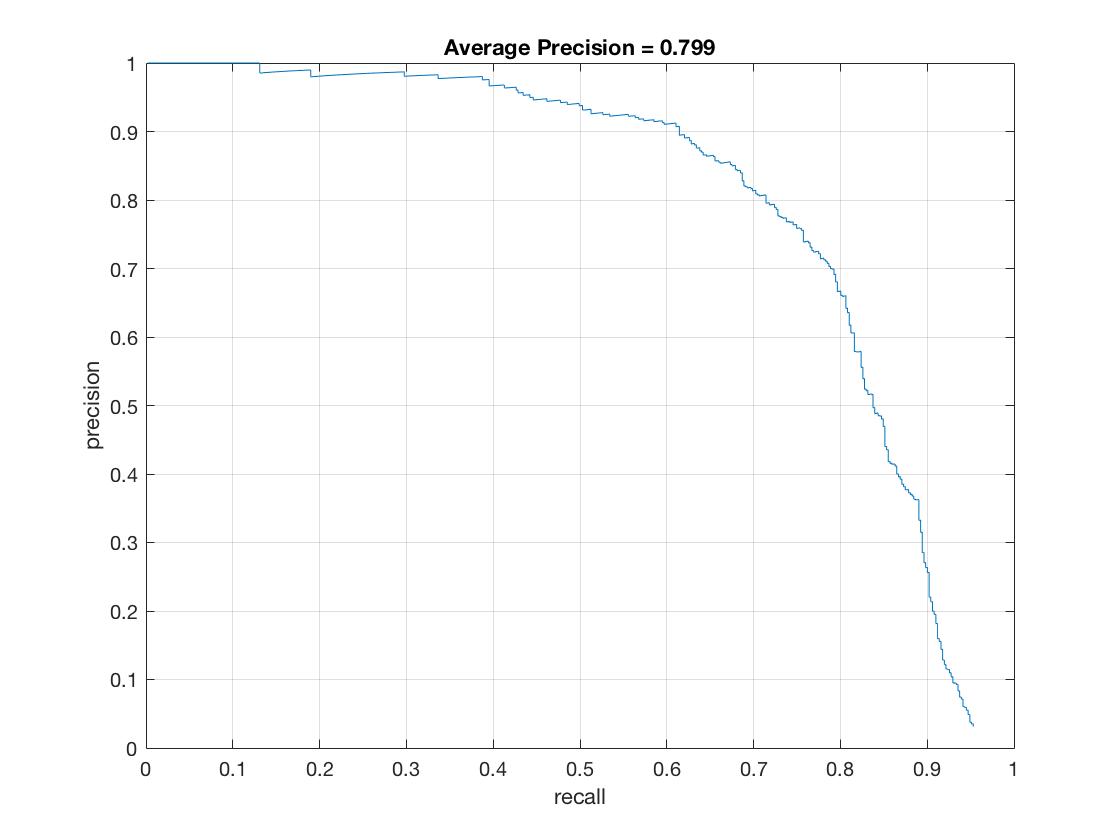
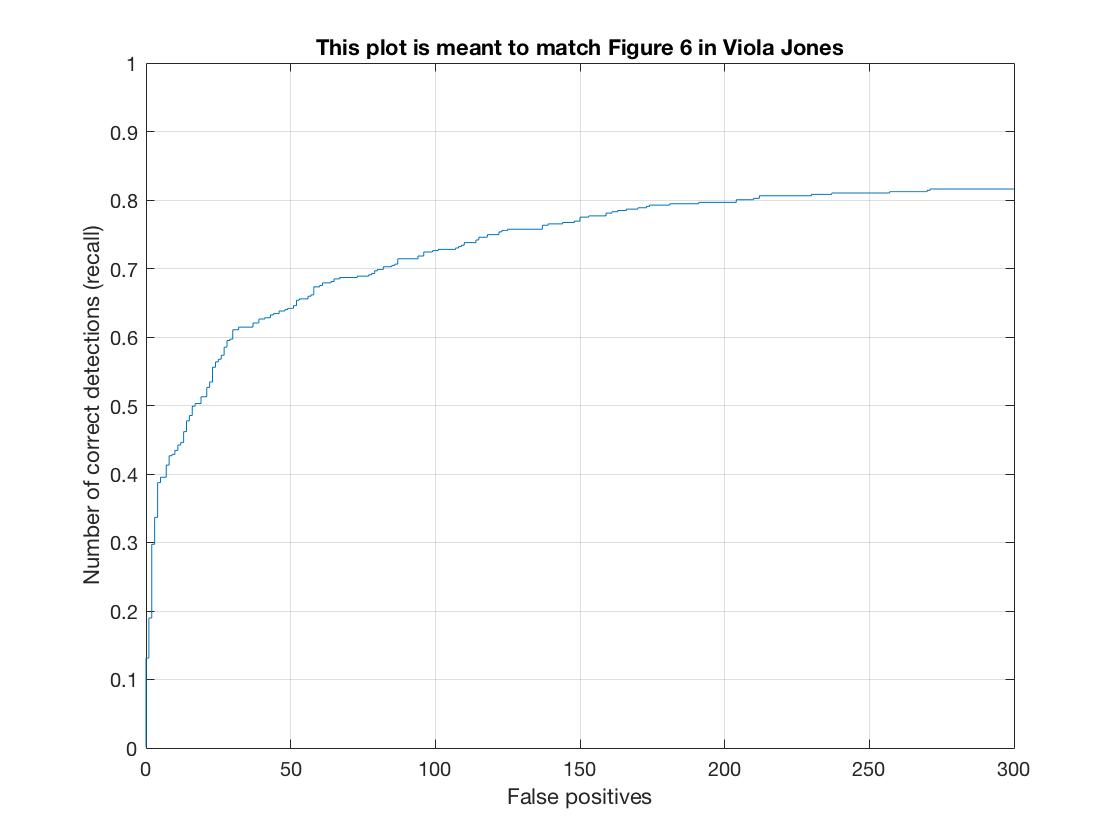
|
The results from using the "labeled pupils in the wild" dataset as positive training data and running the detector at 12 scales, downsizing the image by .9 each time and using a 6 hog cell size. Average Precision =
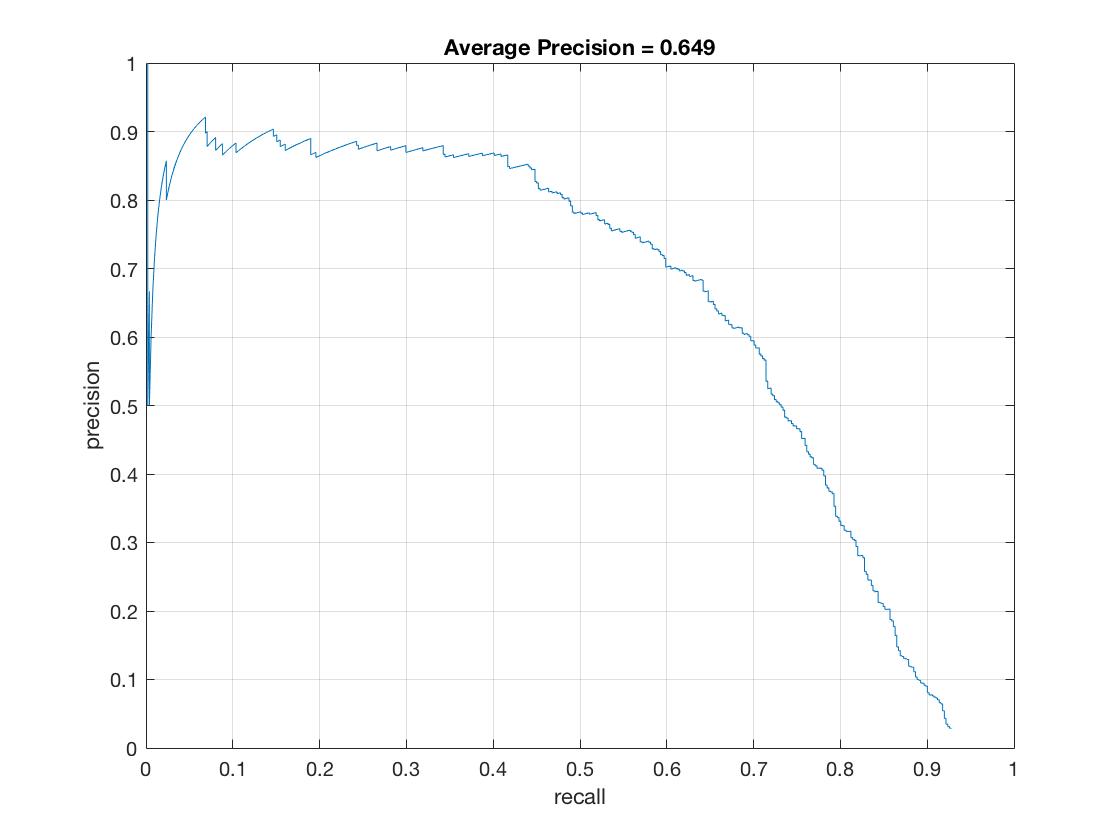
|
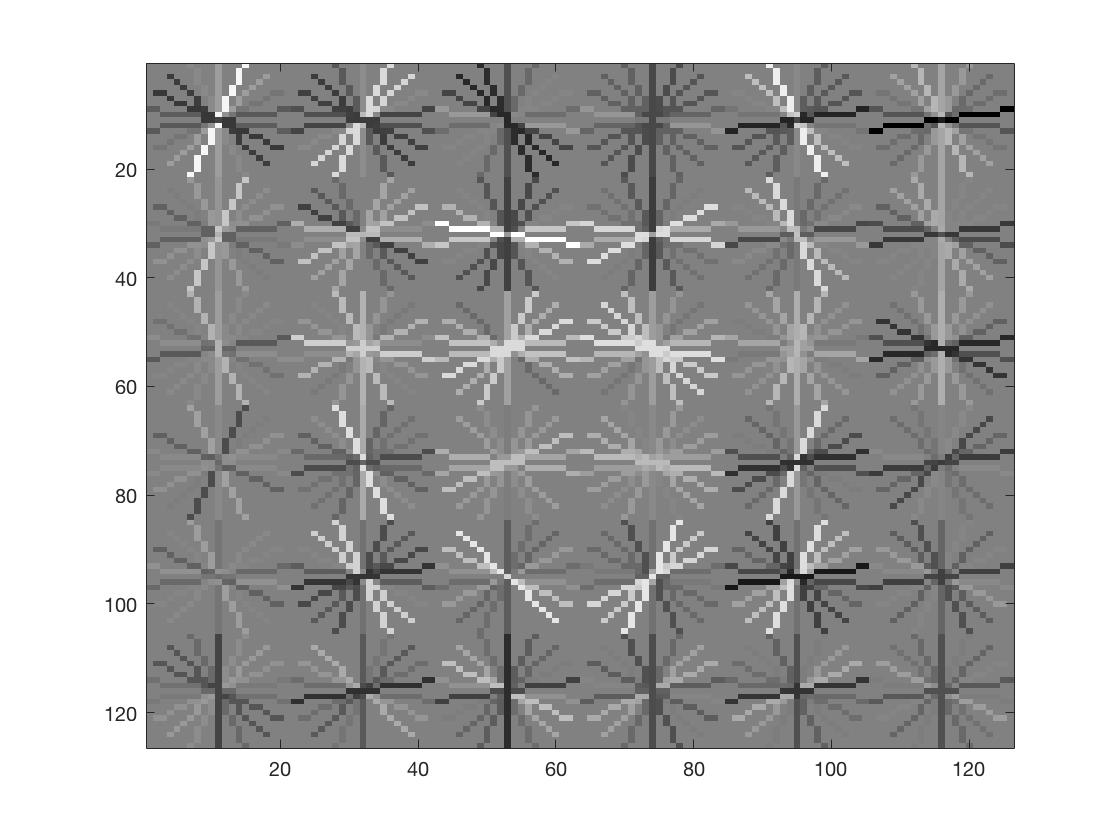
Face template HoG visualization for the my code.
Face Detection examples with hog cell size of 6.

