Project 5 / Face Detection with a Sliding Window
The purpose of this project was to train a face-detector that could accurately classify portions of an image as either a face or not a face. I approached the implementation of this in three main steps
- Get training features using Histogram of Oriented Gradients (HoG) from positive examples and randomly sampled negative examples.
- Train an SVM to classify faces using the acquired features.
- Run a face detector using a sliding window at multiple scales and non maximum suppresion for the test images.
There were a few specific implementation details that made this project work smoothly. After using VL_feat's HoG implementation, the feature that is returned needs to be reshaped so that it's just one row. This allows for the stacking or concatenation of multiple features without having to keep track of which rows correspond to which feature. The parameters that were used for the different components of this algorithm were also tweaked until a desirable accuracy was acheived. For the SVM, a lambda of .0001 was used. For HoG, a cell size of 6 was used. For the threshold on confidence levels, I started at around 0.5 and then increased by .05 until 0.85 was used for the final implementation.
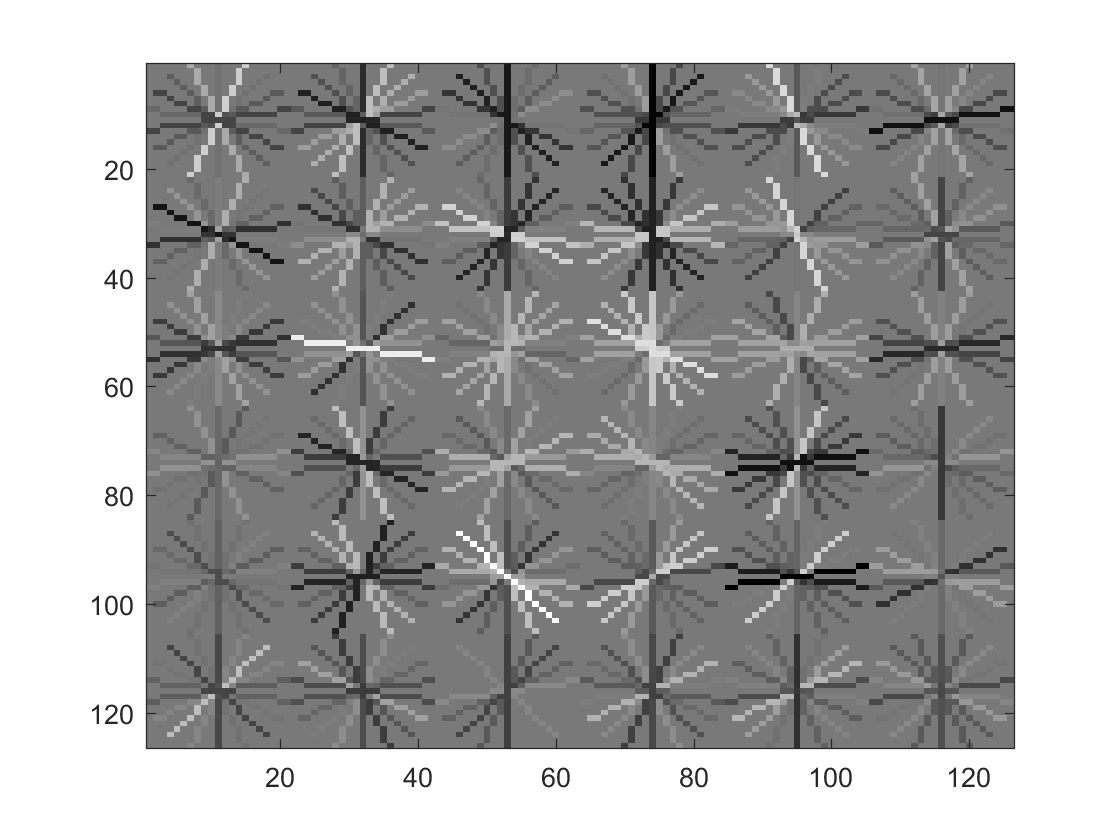
Face template HoG visualization Using Positive Features
Implementing the Sliding Window with multiple scales
scaled_img = imresize(img, scale);
[height, width] = size(scaled_img);
test_features = vl_hog(scaled_img, cSize);
img_cell_x = floor(width/cSize);
img_cell_y = floor(height/cSize);
temp_cell = feature_params.template_size / cSize;
window_x = img_cell_x - temp_cell + 1;
window_y = img_cell_y - temp_cell + 1;
D = temp_cell^2*31;
window_feats = zeros(window_x * window_y, D);
for x = 1:window_x
for y = 1:window_y
window_feats((x-1)*window_y+ y,:) = ...
reshape(test_features(y:(y+temp_cell-1),x:(x+temp_cell-1),:), 1,D);
end
end
Results in a table




|




|
Results from Extra Test image

The results for this image were not as good as for some of the original test images. Despite the fact that all faces were indeed found, there are a lot of false positives, particularly for the people in the front row where their entire bodies could be seen.
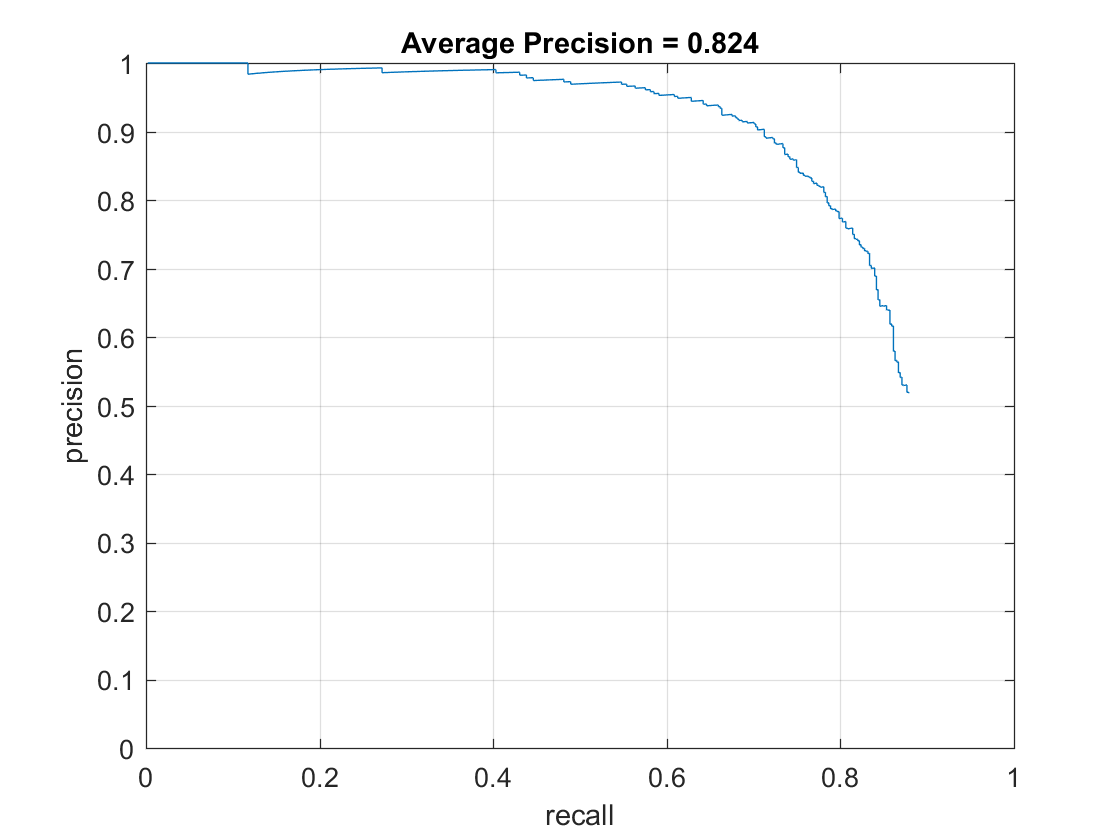
Precision Recall curve for final implementation.