Project 5 / Face Detection with a Sliding Window
Overview
The idea behind this project is to create a sliding window algorithm that would be able to detect certain things in images. Here, face detection was set as the explicit goal, in a similar way that a lot of cameras feature it. Not only should it be able to work on a real-life images, it should also be able to detect drawn faces.
Gathering positive and sampling negative features.
Before starting training, I first needed to gather features. I started with gathering positive ones, which was a fairly straight-forward process of just making a vl_hog() function call, "flattening" the 3D feature into a 1D row, and then appending it to the training matrix.
Gathering negative features was a bit trickier, since we only need to sample a certain number of them. I solved this problem by making my step cell size to be the feature_params.template_size / feature_params.hog_cell_size on y-axis and twice that on x-axis. This allowed me to sample some number of negative features from every single image. However, this produced more than we would normally want anyways, so then I just used randsample() function to sample the exact number of features I want from the ones I gathered
Training an SVM
Training was fairly quick to implement since it was very similar to what I did in the previous project. I tried to tweak the lambda value, however, I observed the exact same kind of variation I had in the previous project, and the exact same lambda value of 0.000076 ended up to work the best. Running the training set through the trained SVM produced accuracy of 1.0 with no false positives or negatives.
Writing a detector, single-scale and then multi-scale
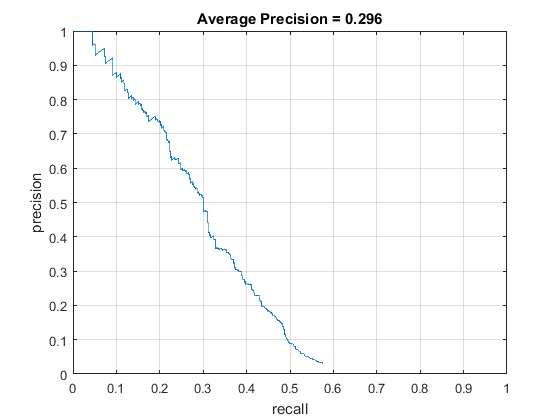
Once I have trained an SVM, the time has come to write a detector that I should be able to run on images where I am trying to detect faces. I started with a single-scale detector. The most complicated part was to figure out the calculations necessary for translating cell features into real x/y coordinates. After trying many different confidence thresholds in-between -1.0 and 0.0, I settled on -0.5. Lower threshold produced more false positives, and higher failed to detect some faces. These are the results I managed to obtain using my single-scale detector. Note: non-max suppression was not utilized since we are only using a single scale, thus rendering non-max suppression useless. I also accounted for the rare edge case of no faces being detected in the image, because when encountered, it breaks the rest of the code.
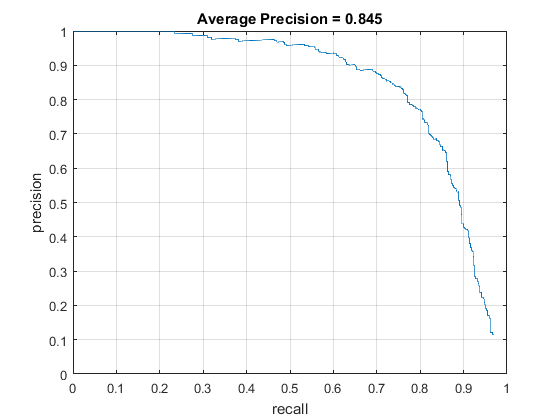
After that, I set on implementing a multi-scale version of my detector. The only major difference was the accounting for scale. What I did in this case, I found the smallest dimension of my image (x or y) and with my starting scale being 1, every iteration I multiplied it by 0.8 (scale factor), resizing the image, and running my detector on that, continuing that until my sliding window becomes bigger than the smallest image dimension found earlier. Higher scaler factors (up to 1.0) give more accurate results, however, I was not satisfied with the runtime for 0.9, so I settled on 0.8. This implementation, in my opinion, became the most optimal one I managed to build with a total runtime of less than 8 minutes. Below you can see the accuracy results and the trained SVM used for this multi-scale detector that employed 6x6 HoG feature cells.
For the sake of experiment, I decided to push it to the max and try 4x4 and 3x3 feature cells.
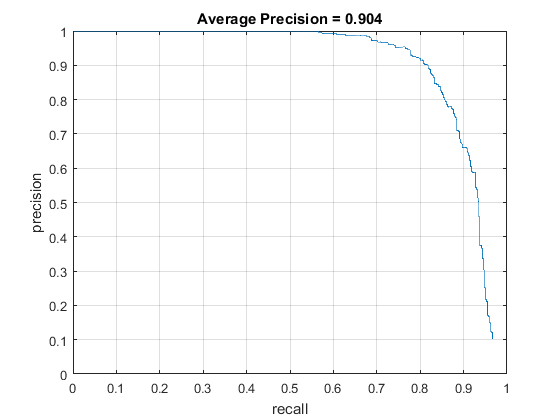

Using 4x4, as can be seen here, brought the precision up dramatically, and the runtime increase, even though was noticeable, wasn't that bad with about 15 minutes total.
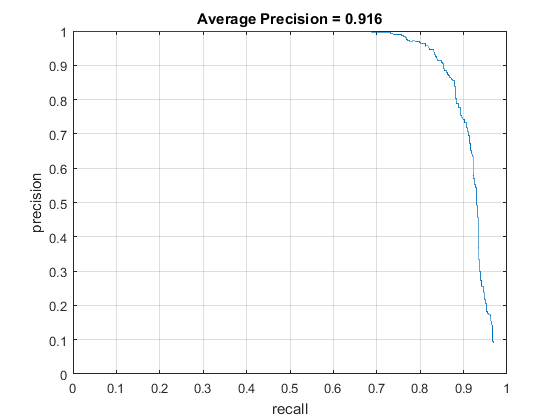

Using 3x3 HoG cells didn't bring precision up that much, but it increased runtime dramatically to somewhat around ~40 minutes.
Conclusion
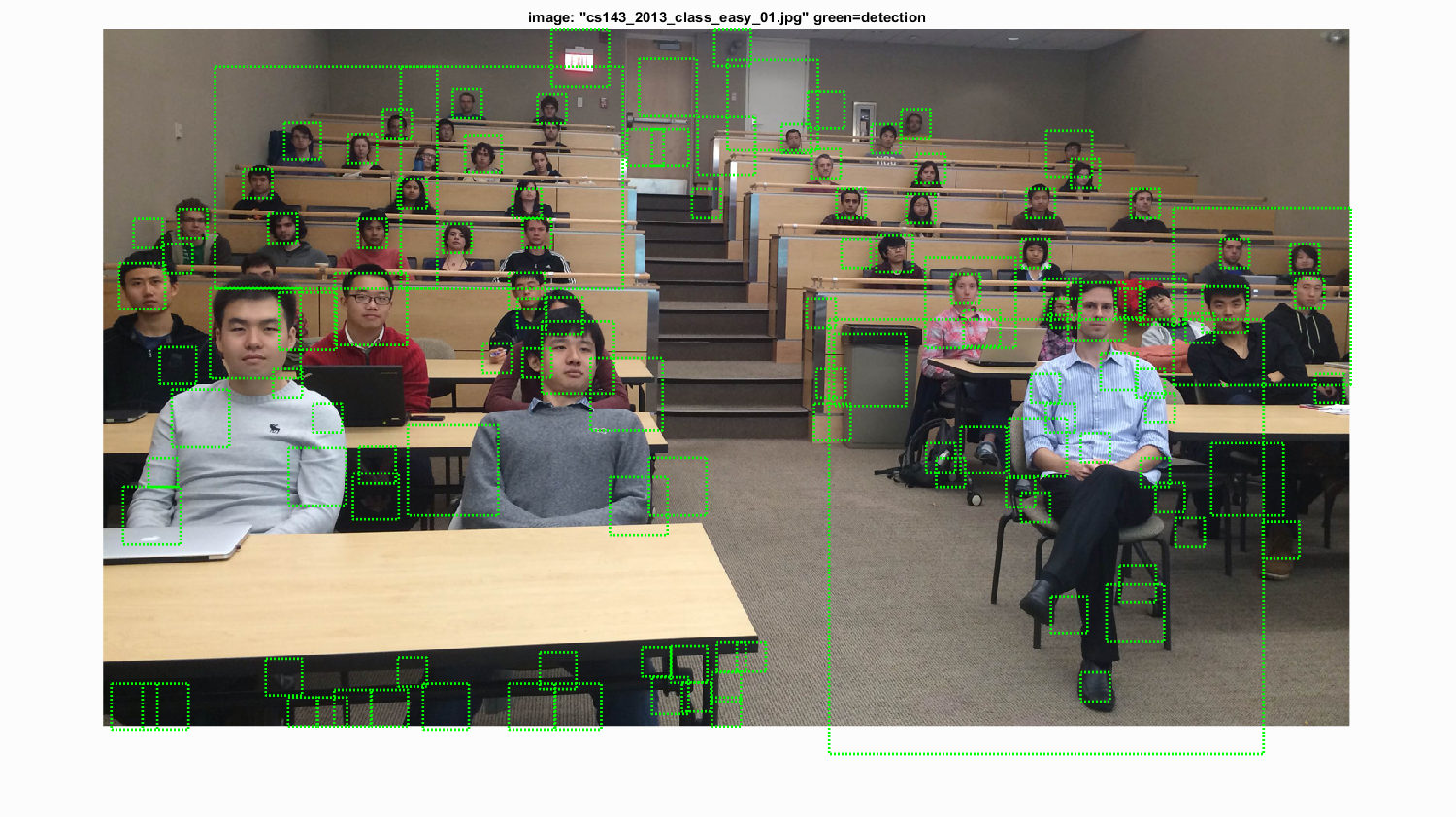
Overall, using a multi-scale sliding window for facial detection is pretty fast and effective. Even with the biggest (and thus most performant) HoG cells of 6x6, it manages to have an average precision to 0.84, which can be brought up even higher by either mining for negatives or modifying the training set with by distorting/blurring some of the images and training the SVM on it in additional to the original training images. The runtimes are also impressive, considering that in the previous project, the runtime was barely contained under 10 minutes. In conclusion, I am putting up a gallery of some of the face detections created by the algorithm with a 6x6 HoG cell size as a parameter, which can be seen below. First, I will display the results of the algorithm performing on the extra scenes and then on the normal testing set.
Extra testing set:









Regular testing set:







