Project 5 / Face Detection with a Sliding Window
For this project, I implemented Dalal-Trigg's Histogram of Gradient feature representation of images in order to train an SVM classifier to detect human faces in an image. The three main components of the project were creating positive features, sampling negative features, and running the detector on the test set. There is also the matter of tuning the classifier and while I will talk about that more in depth later, the actual code for training the SVM is minimal and is eclipsed by the SVM work done in the previous project.
Positive Features
In order to give the face detector a reference for what a human face looks like, it's necessary to feed it good approximations of what human faces look like. The function get_positive_features.m implemented this behaviour by reading in each image in the training directory and calling vl_hog on it. Additionally, each image was then flipped over the y axis to create a mirrored image. Since a mirrored face is still essentially a face, this allowed me to double the set of positive images.
Negative Features
On the flip side of positive features, it is important to have a steady supply of negative images so that the classifier can learn what get_random_negative_features.m was more concerned with getting a good sample of negative features than getting all of them. To do this, I first selected a random image from the dataset and scaled it by an arbitrary amount (although ensuring that it would be at least large enough to fit one 36x36 window HoG). From this, I then took a random patch of the image and calculated the HoG for that. This procedure was repeated for as many samples as necessary. In practice, around 40k negative samples seemed to give me good performance.
SVM Training
Linear Support Vector Machines have one main hyperparameter -
Face Detection
Having created a face recognizer, the next step was to see how well it could detect likely faces in a larger image. To accomplish this, each image was converted into its HoG feature representation, then iterated over in a sliding window to classify those gradients as either a face or not a face. If the classification passed over a threshold of -0.1, then the classification was kept to non-max suppression later. For each image, this process was done at scales ranging from full size to 10% size in order to allow our classifier to detect faces much larger than those it had been previously trained on. Finally non-max suppression was run on the detected faces in order to eliminate overlapping duplicates. In some cases, this decreased total detections by an order of 10.
Results
With the training parameters mentioned above, average precision and recall scores both were around 70%. When I tried decreasing HoG cell size to 3 or 4 pixels rather than 6, much higher scores in the neighborhood of 80% were achieved, however those tests took much longer than the allotted 10 minutes to run on my computer and so while more accurate, they do not reflect the more useable results gotten from using cell sizes of 6.
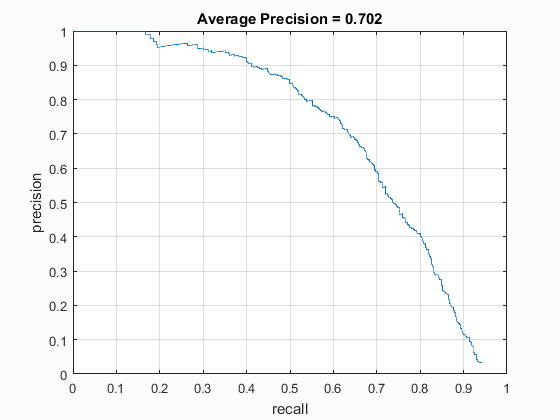
Upon receiving this less than stellar precision, I decided to investigate what sort of images were the most troubling for my classifier. Large faces tended to be an issue for my classifer, especially female ones. Additionally, cartoon/drawn faces and non-square ones tended to be difficult for the classifier.




On the otherhand, male faces tended to do pretty well, even fairly noisy depictions.

