Project 5 / Face Detection with a Sliding Window
Here, we train an object detector using the algorithm proposed by Dalal and Triggs.

Obtaining Features
I use the positive image dataset provided with the project. For each image, the hog map is computed based on a specified step size. I also flip each image to obtain another set of hog features and augment the positive training set. For the negative images, I cut out samples for multiple scales of the same image and then compute their hog map (pseudo code shown below). These positive and negative features are then passed to a SVM classifier which finds suitable parameters.
%Pseudocode for cutting out negative image features
while count < num_samples
Read a random image from negative data set
% Keep scaling down this image by a parameter as long as it's larger than our template
while size(img,1) > Template Rows && size(img,2) > Template Columns
Find a random position in the image and crop out a template sized block
features_neg(count,:) = reshape(<Hog map for this block>,1,[]);
img = imresize(img, scale);
count = count + 1;
end
end
Sliding Window Detector
For this, I compute the hog map of the test image at multiple scales and then iterate over each template_size block to see if the classifier classifies it as a positive instance or a negative instance. For each positive instance, I then compute the bounding box by taking that block which matched and multiplying it with the inverse of the scaling value. All such bounding boxes are concatenated and then the non-maximum suppression function provided with the starter code is applied to remove lower confidence box(es) with a high degree of overlap with a higher confidence box.
Results
The learned hog detector is visualised below for different step sizes:| Hog Cell Size | 3 | 4 | 6 |
| Detector Visualisation | 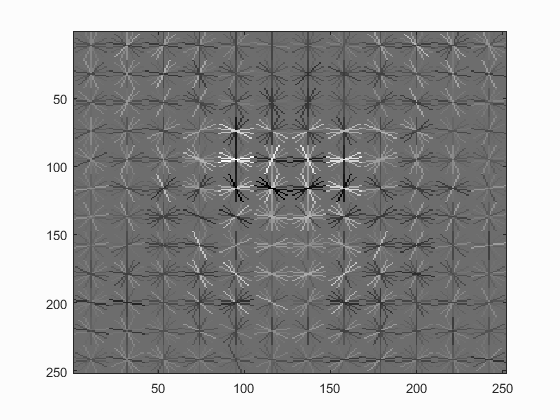 |
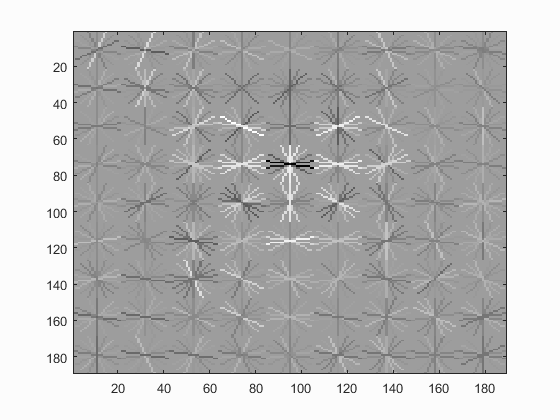 |
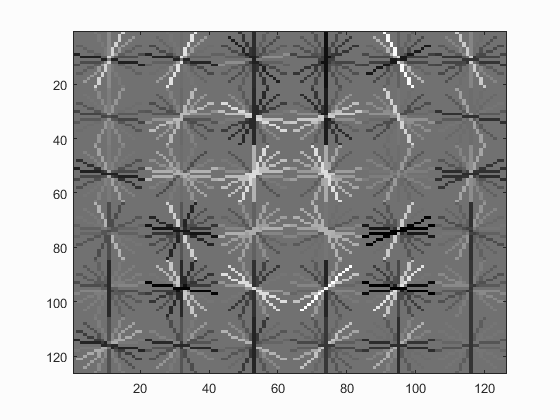 |
Results of Detected Images

 |

 |

 |
Precision Recall Curves
The precision recall curves for different cell sizes have been shown below. These are good, but not greatly tuned values I could obtain. Step size of 3 was prohibitively slow (~15 minutes), but gave a really good accuracy.| Hog Cell Size | 3 | 4 | 6 |
| Average Precision | 0.925 | 0.881 | 0.883 |
| Precision Recall Curve | 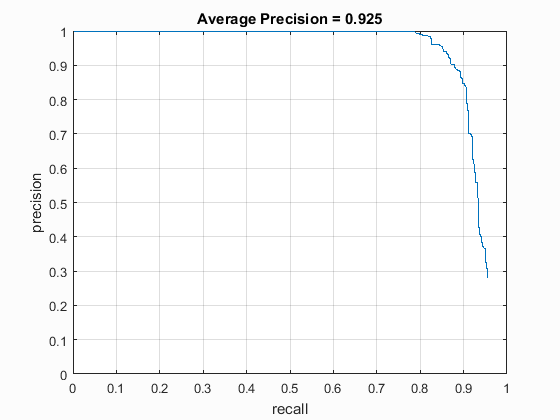 |
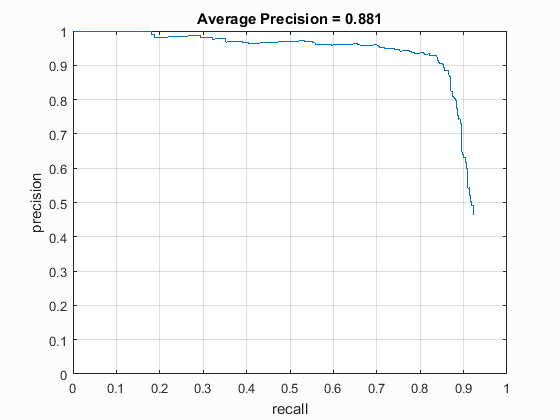 |
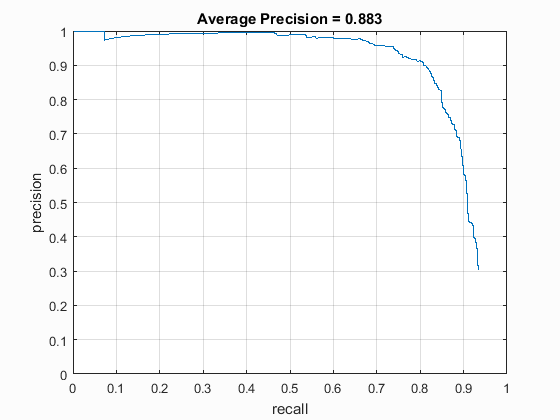 |
Hard Negative Mining
I implemented hard negative mining by running the sliding window detector on the negative training set. I then selected all bounding boxes with threshold greater than 1, cropped the image there and saved it in a separate folder to be used as another isntance of negative image. For this, I simply suitably modified the code from one of the visualize_images functions. I have saved this as a function mine_negatives.m. The mined images are saved in the folder data/hard_negatives.
The results I got after doing this varied. At one point, I got a 10% reduction in the value of average precision after augmenting the negative image set with these images. In other cases, I had to reduce the thresholds to get a value of average precision comparable to that obtained without hard negatives. Qualitatively, the way I understand it is that because of negative mining, I might have actually stopped detecting the borderline faces (like the ones on cards, etc).
Car Detection
As an additional data set, I implemented the same detection on images of cars. I obtained the dataset from the UIUC Image Database. This dataset consisted of 550 positive images of resolution 100 x 40 which were side views of cars. I've included them in the final zip file. I ignored the negative images from that dataset and instead used the ones provided with this project (after removing the two cars that were present in them). The trained detector is visualised as shown below:
Some results of running this detector on the test images provided with the dataset are shown below. A not insignificant amount of cars weren't detected, a lot of them being black. I suspect this might have something to do with a lack of positive training instances. I didn't get time to decipher the way they had annotated their ground truth for test images, so I couldn't modify it/get suitable comparisons with ground truth.
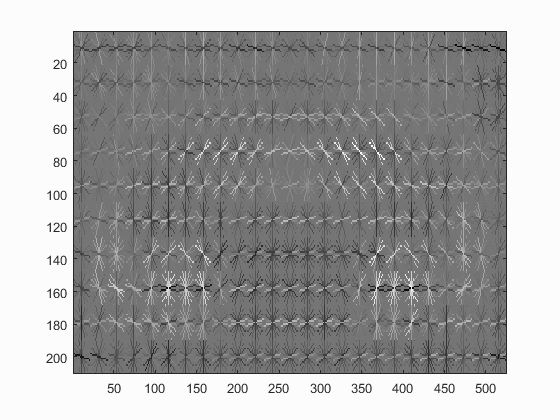
Results of Detected Images

 > > |

 |

 |

 |