Project 5 / Face Detection with a Sliding Window
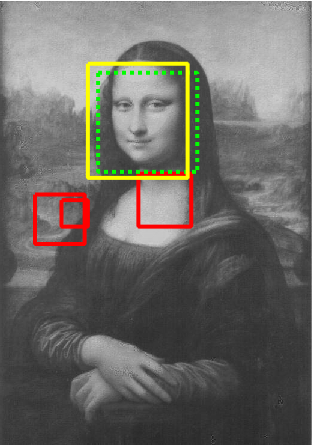
The goal of this project to implement a face detection algorithm similar to the sliding window detector proposed in Dalal and Triggs 2005. It uses a SIFT-like Histogram of Gradients (HoG) feature representation. The HoG template contains cells of 31 dimensions, with histograms counting number of pixels with graidents in 9 directions. Then the template is compared to small windows (subsections) of images at various scales. Then non-max supression is applied to handle overlapping boxes before outputing the face detections.
The classifier is a linear SVM (using vl_svmtrain()) that uses positive features from the Caltech 36x36 Caltech Web Faces project and negative features (from images with no faces). For each image in the test set, scaled images are created. These are converted to a HoG representation, and then each portion of the image is evaluated with the classifier. The portions with a high-enough confidence are used.
| HOG Cell Size | 6 | 4 | 3 |
|---|---|---|---|
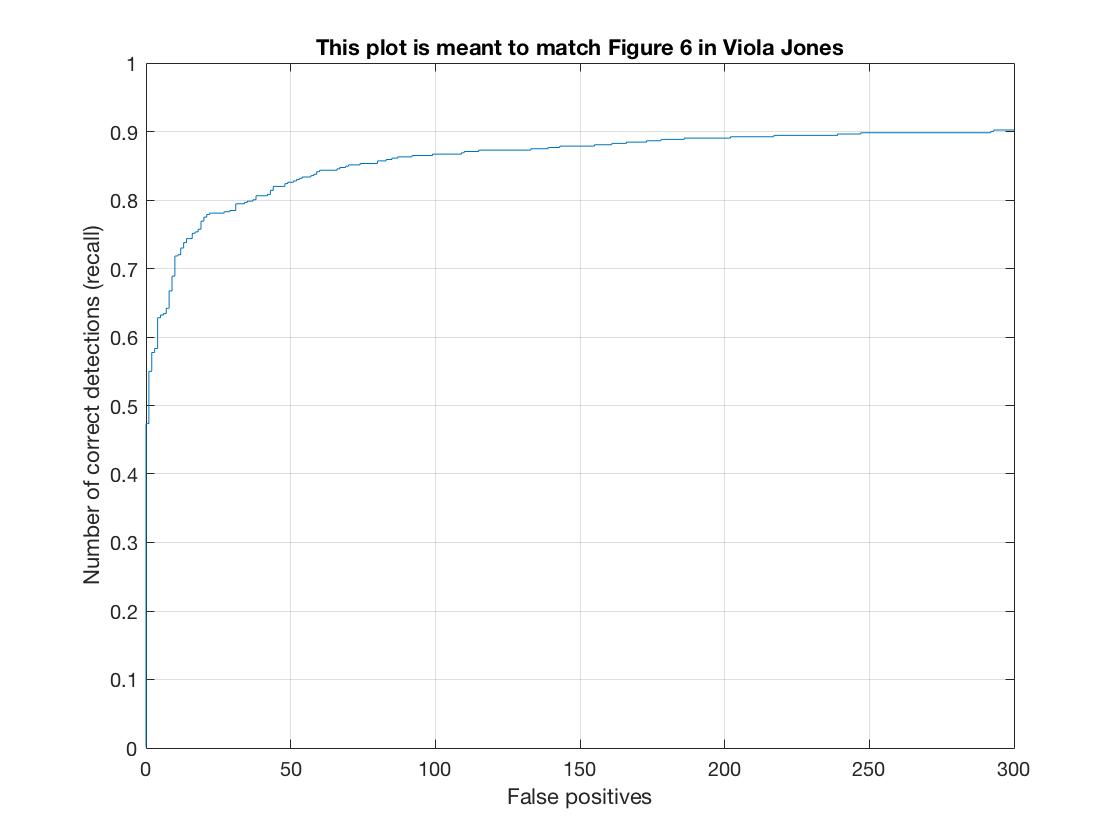
| Average Precision (%) | 82.9 | 88.9 | 90.4 |
| Accuracy | 0.998 | 0.999 | 1.000 |
| True Positive rate | 0.397 | 0.397 | 0.398 |
| False Positive rate | 0.000 | 0.001 | 0.000 |
| True Negative rate | 0.601 | 0.601 | 0.602 |
| False Negative rate | 0.002 | 0.000 | 0.000 |
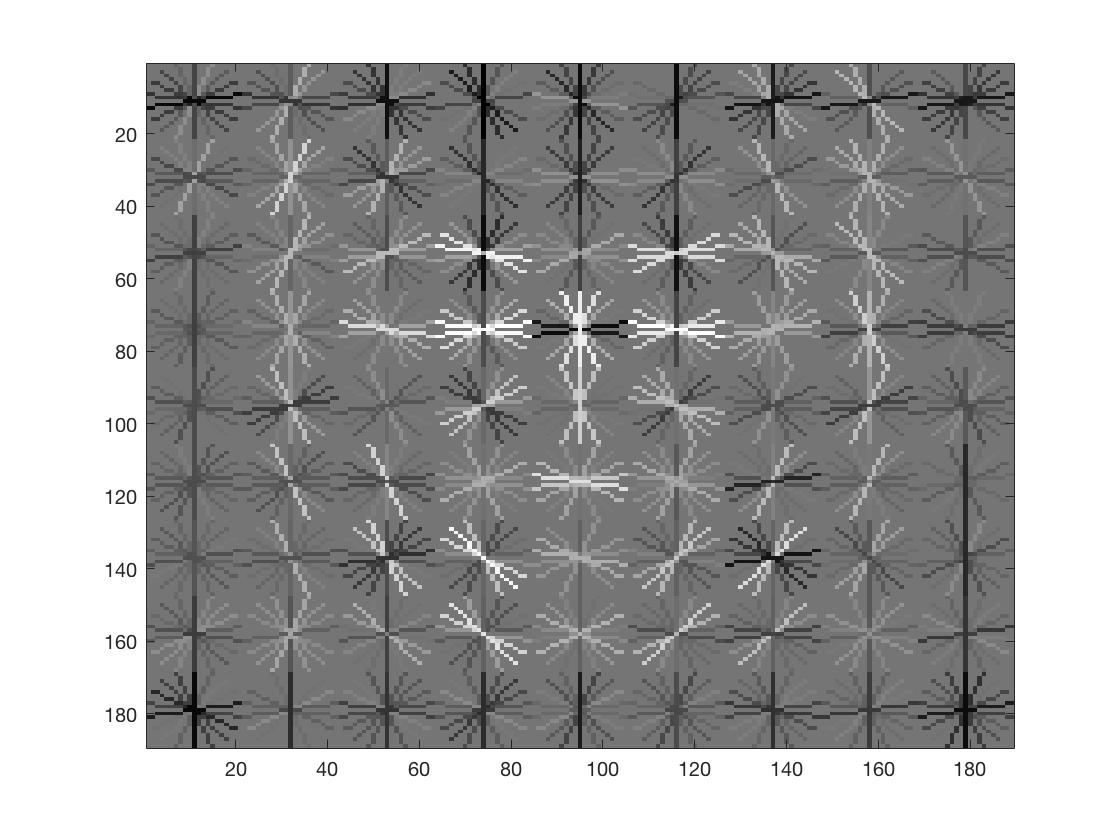
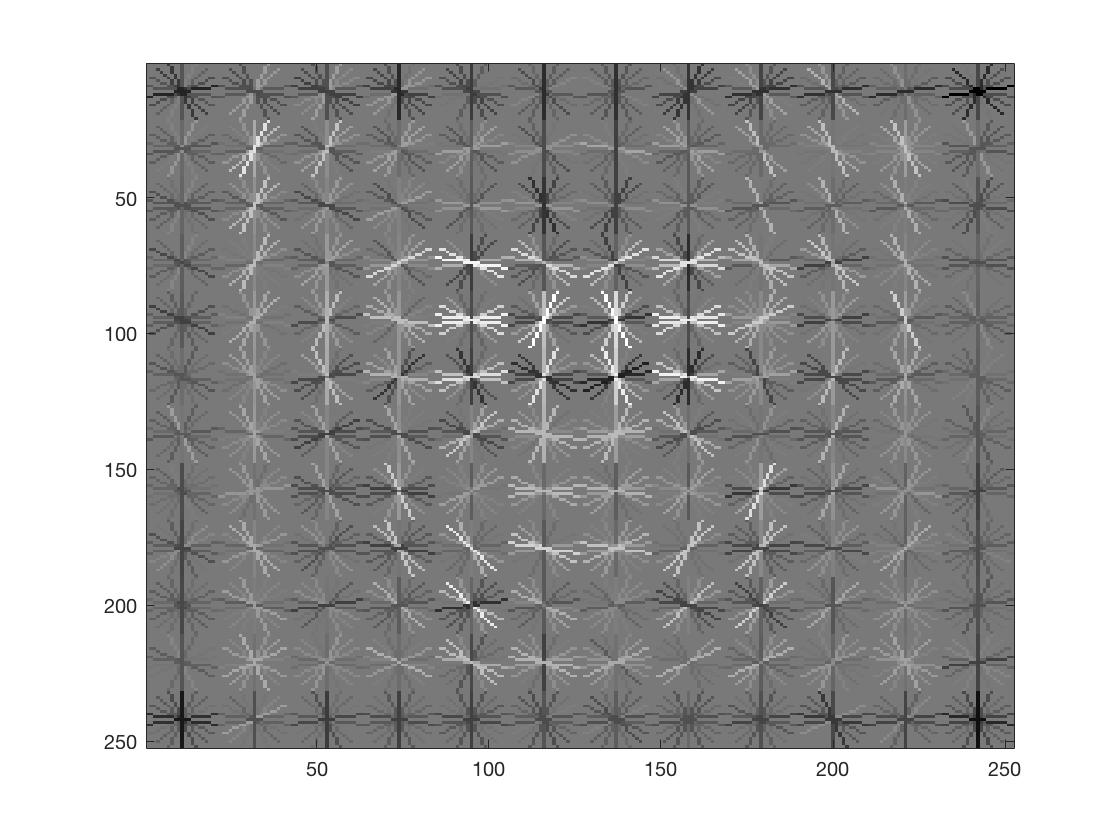
| HOG Image | 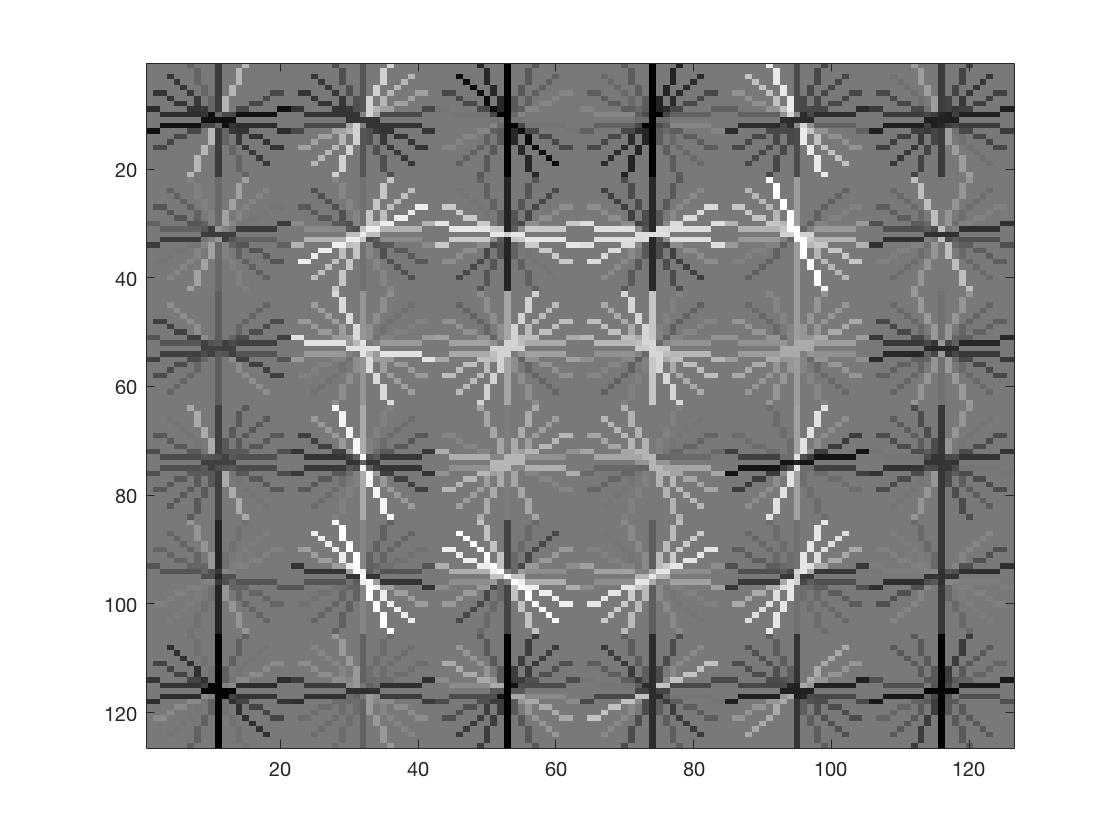 |
 |
 |
| Average Precision | 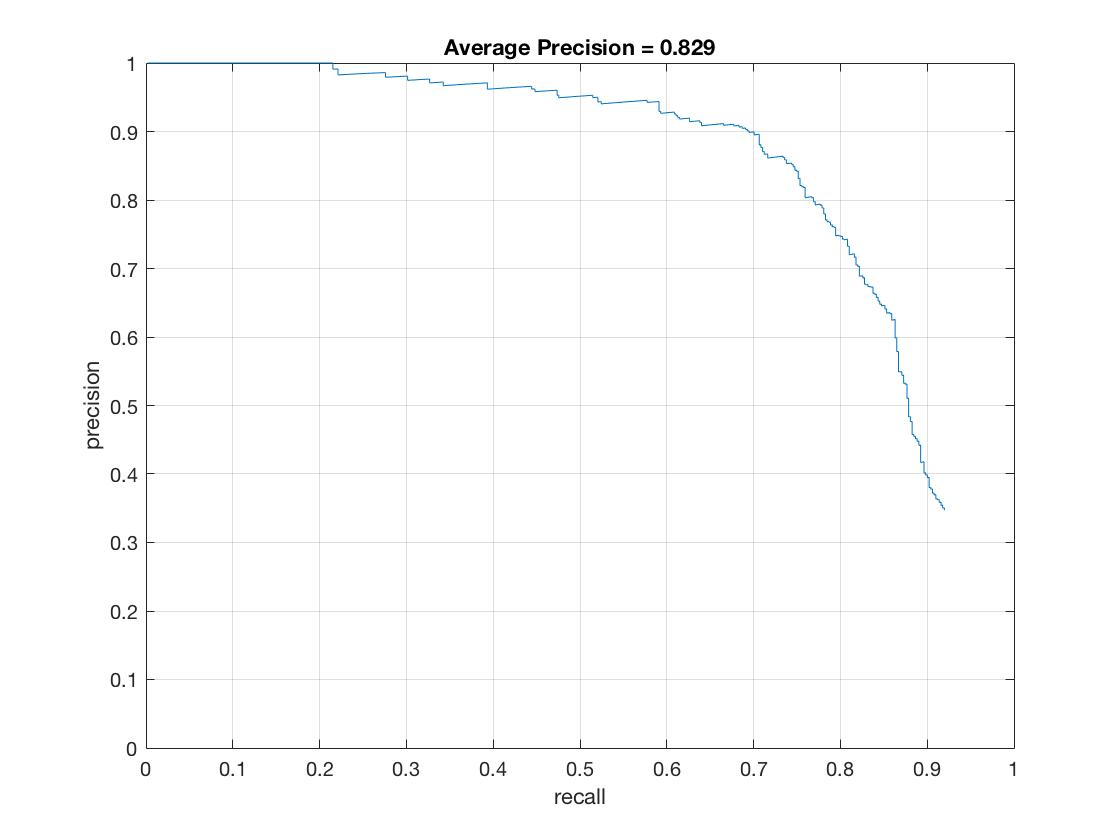 |
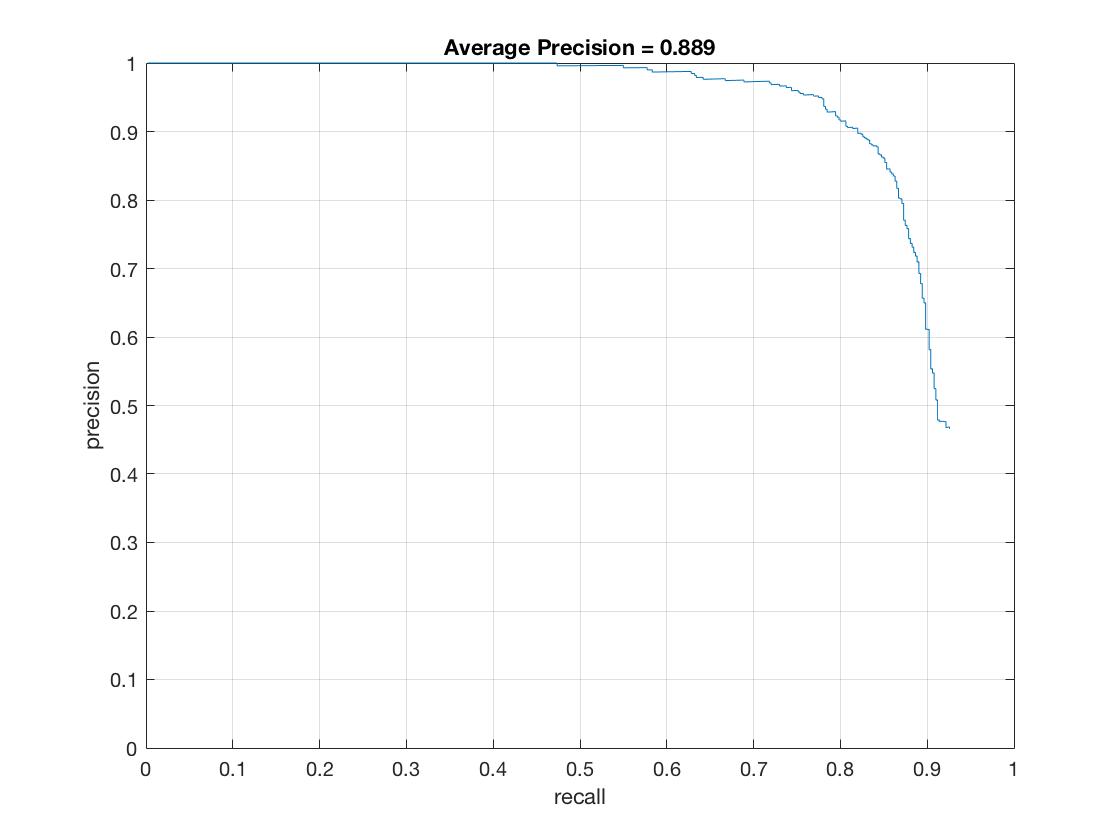 |
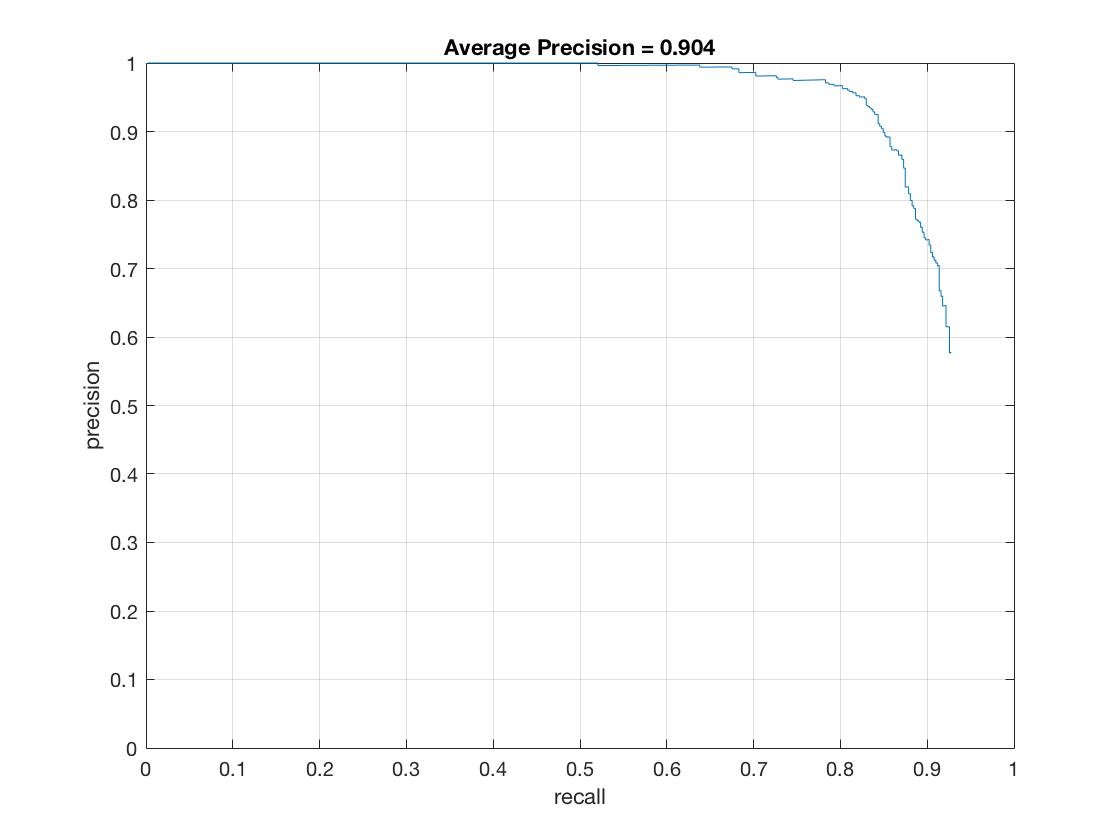 |
| Recall vs False Positives | 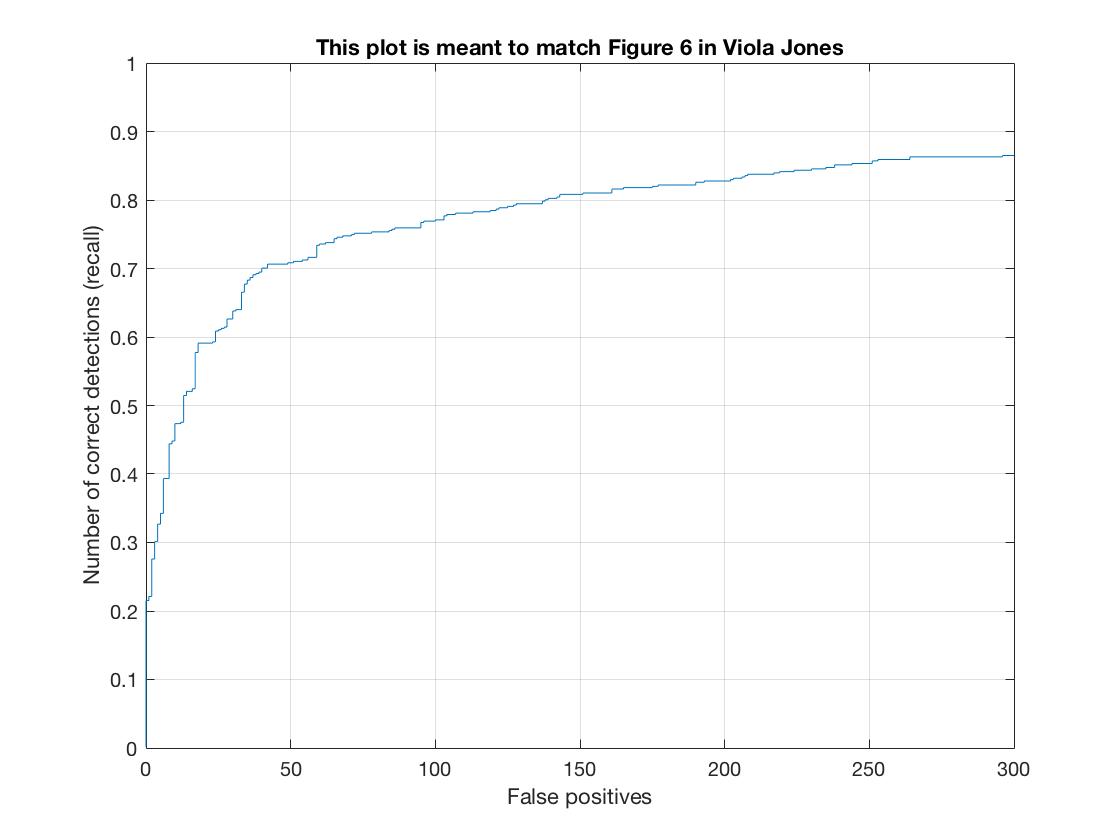 |
 |
 |
| Classifier | 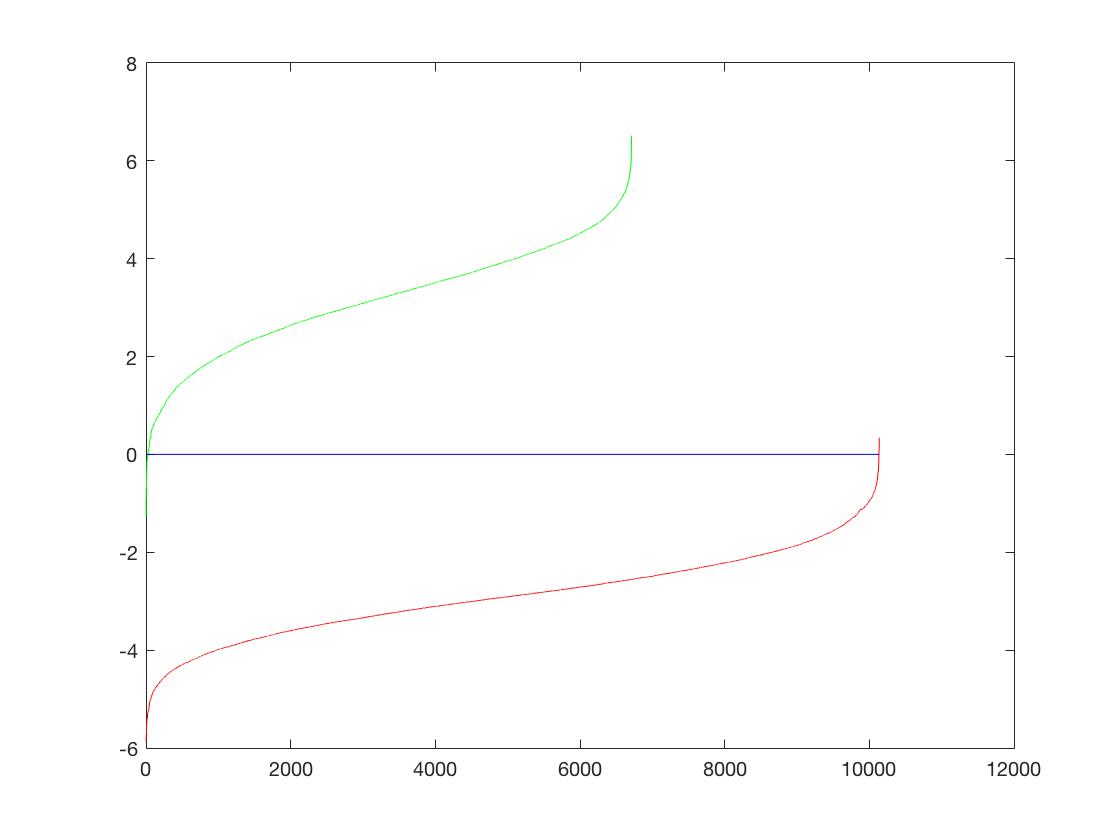 |
 |
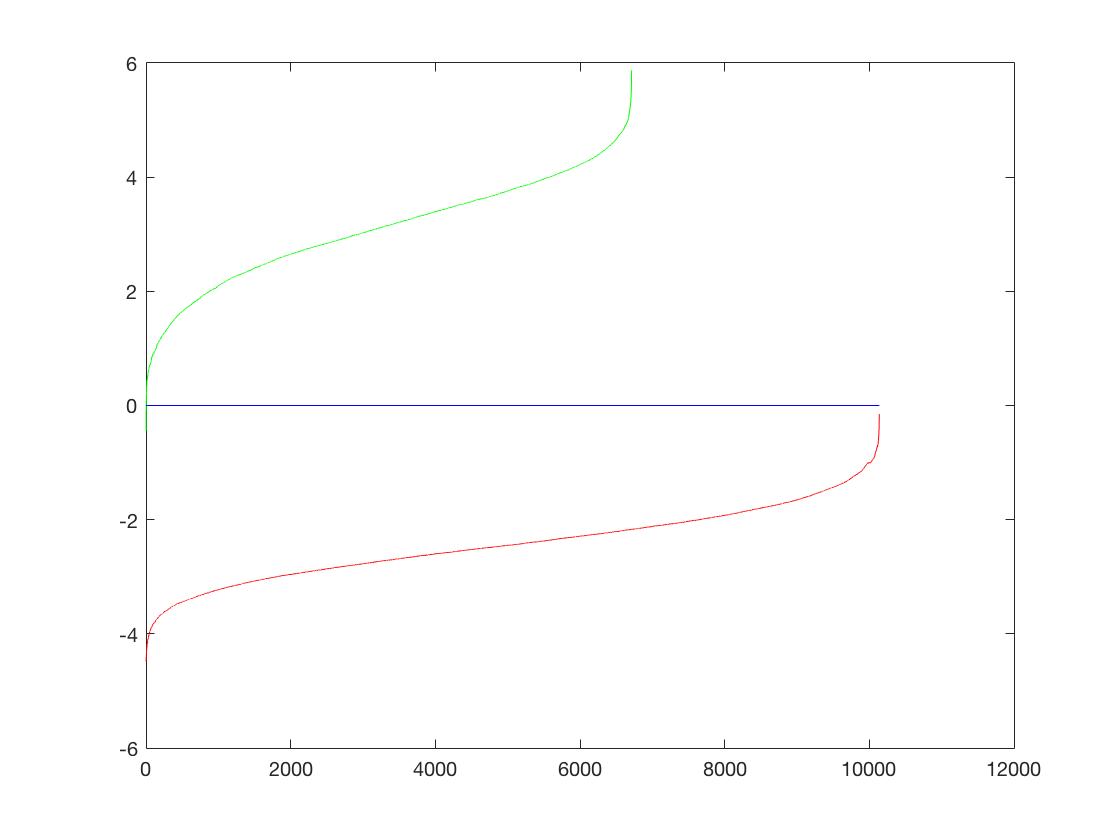 |
| Sample Result |  |
 |
 |
Configurations
Smaller HoG Cell Sizes semmed to improve performance. I used a lambda value of 0.0001 for the SVM classifier, and a threshold of 0.3 for the confidence values. We can see that smaller HoG cells result in more face-like HoG templates.
Extra Credit
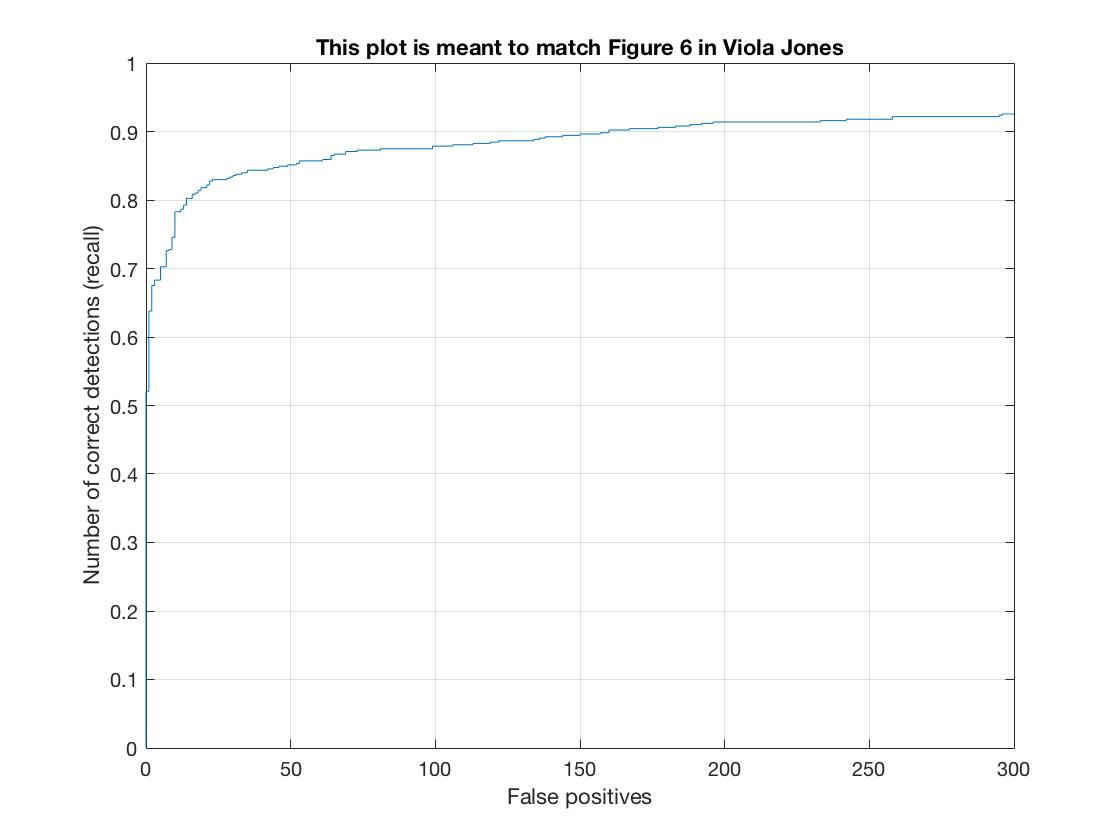
I flipped each image in the positive examples database to produce twice the amount of positive examples (6,713 x 2 = 13,426). This resulted in a more symetric template and increased precision. Here are the comparisons for HoG cells Size = 4.
| Configuration | Original | Doubled |
|---|---|---|
| HoG Template | |
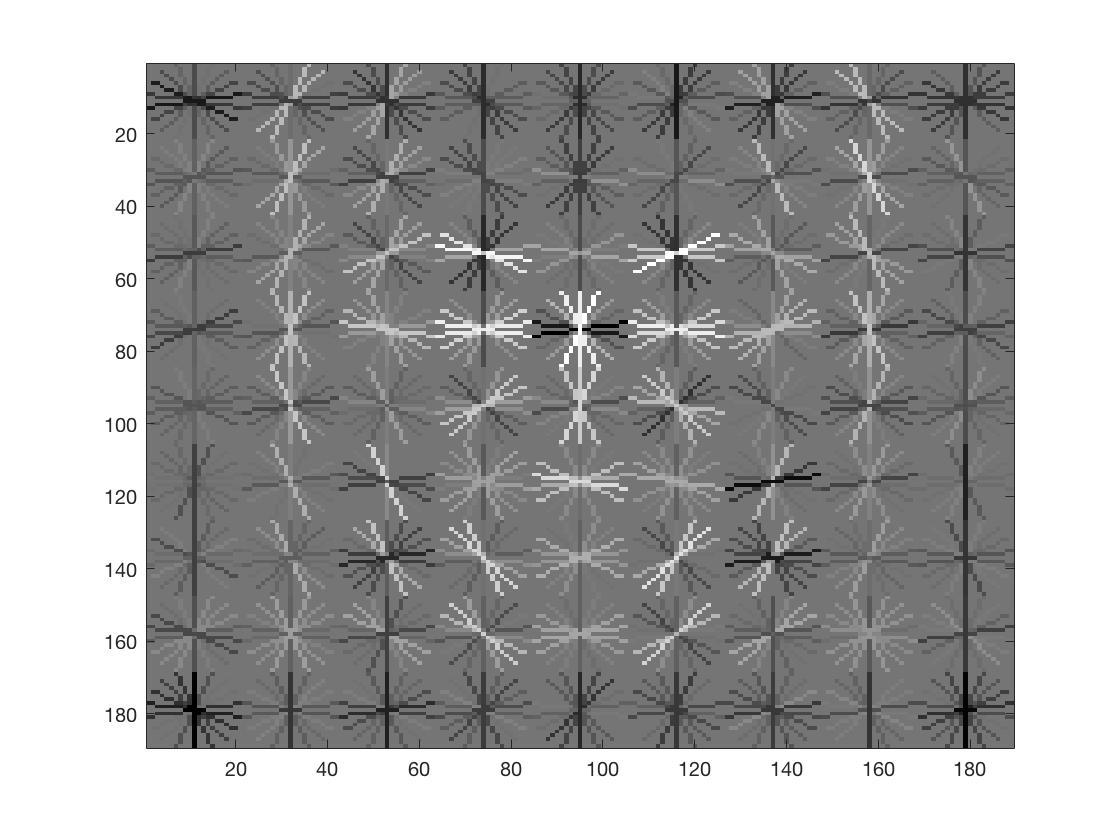 |
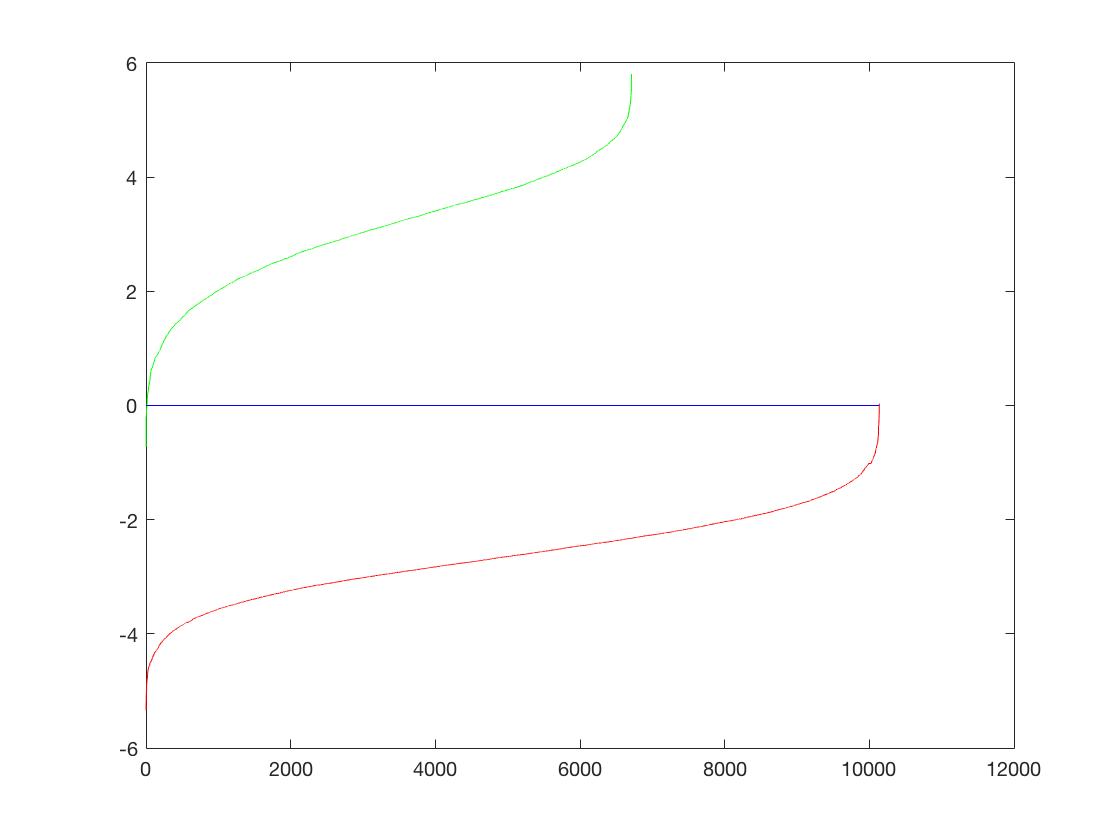
| Classifier | |
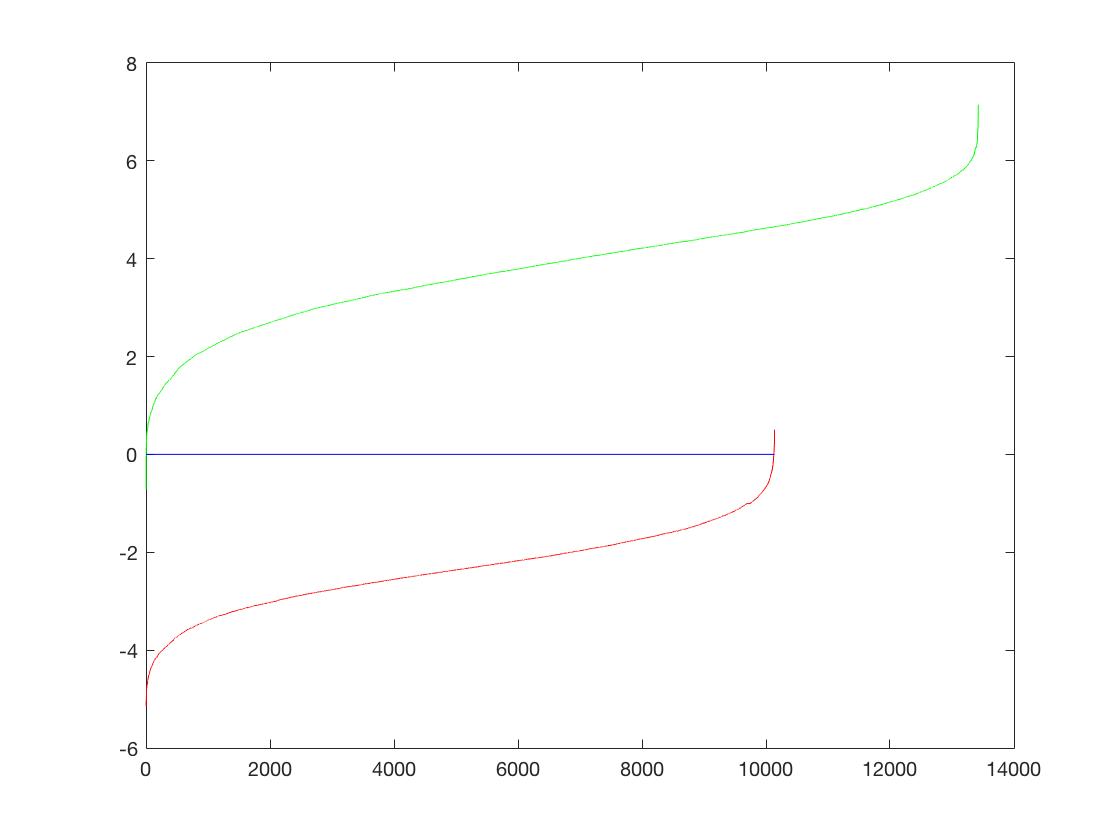 |
| Precision | 88.9 | 91.8 |
Sample Results
Here are some results with HoG Cell Size = 3 and double the number of positive training examples.


