Project 5 / Face Detection with a Sliding Window


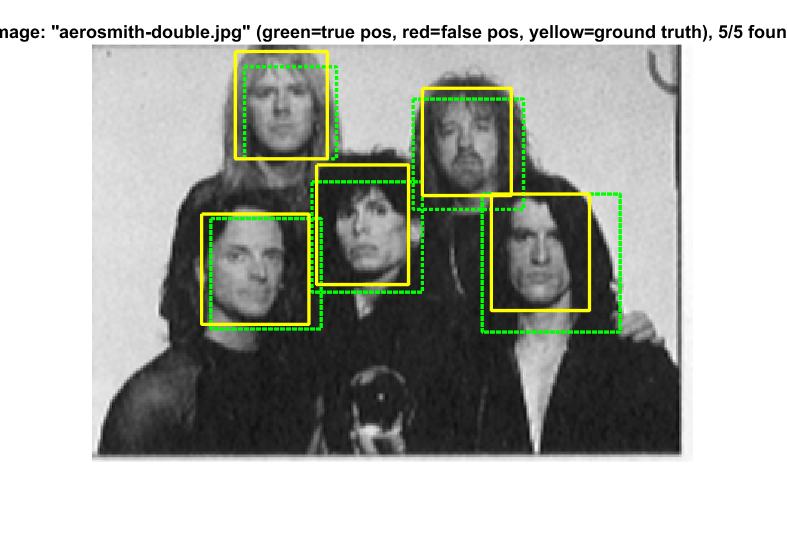
Example of a face detection.
The project was aimed at implementation of face detection using HOG features. It is similar to the sliding window algorithm by Viola Jones. The sliding window model is conceptually simple: independently classify all image patches as being object or non-object. Sliding window classification is the dominant paradigm in object detection and for one object category in particular -- faces -- it is one of the most noticeable successes of computer vision. The procedure can be briefly listed as follows:
- Positive features from images using HOG features.
- Negative features from images using HOG features.
- Train SVM to recognise object.
Positive features from images using HOG features:
All the images containing the object of interest are called positive images. These image contain only the object of interest and nothing else. In our case, these images contain faces. HOG features are used to extract features from these images and are called positive features. One thing worth noting here is that all the images that we use for positive data set have to be of the same size. The face detection template is directly dependent on the dimensions of these images.
Negative features from images using HOG features:
Images that contain everything but object of interest are called negative images. In our case, these images do not have faces and can have anything else. A patch of dimension equal to that of dimensions of positive image is extracted from the negative images and the features extracted from these images. They are called negative features.
Train SVM to recognise object.
We train SVM on the positive and negative features to be able to distinguish between them. A template is generated using SVM in which a shape similar to that of face can be observed if we squint the eyes. This means our algorithm has figured out the structure of the face. This template can now detect faces in test images
Different Scales for better detection:
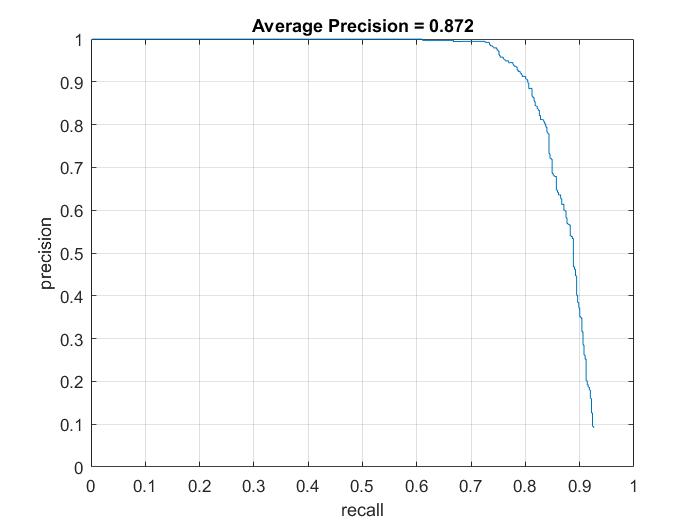
The average precision obtained using the detection obtained using above steps is about 38%. It can be highly increased if we use multi-scale technique for recognition. We detect the possible face patches at various different scales of the original image and the non-max suppression technique is used to remove unwanted patches which overlap with high confident patch.
Code for multi-scale detection
This can be repeated for different scales. We have used {1,0.9,0.8,0.7,0.6,0.5} scales and chosen the patches which happen to have confidence of more than 0.
img1 = imresize(img,0.8);
hog_test = vl_hog((img1), cellsize);
[m n p] = size(hog_test);
for j=1:1:m-factor-1
for k=1:1:n-factor-1
patch = hog_test(j:j+factor-1,k:k+factor-1,:);
features = patch(:)';
confidence = features*w + b;
if(confidence > -0)
cur_confidences=confidence;
cur_x_min = ceil(k*cellsize/0.8);
cur_y_min = ceil(j*cellsize/0.8);
cur_bboxes = [cur_x_min, cur_y_min, cur_x_min+36/0.8, cur_y_min+36/0.8];
cur_image_ids = {test_scenes(i).name};
img_bboxes = [img_bboxes; cur_bboxes];
img_confidences = [img_confidences; cur_confidences];
img_image_ids = [img_image_ids; cur_image_ids];
end
end
end
Precision Recall curve.
Example of detection on the test set from the starter code.


|


|
Hard Negative Mining
We can increase the average precision by using the concept of hard negative mining. In this, we train a SVM model on the negative and positive features as we did previously. We use this model and knowing that none of the images in negative image dataset should contain faces, we find all the patches in these images which have been falsely detected as faces. The features for these patches are re-fed to the SVM model for it to learn in particular that these features are negative. Implementing hard negative mining works better at rejecting non-face regions. I tried detecting most confident faces only and in some cases face detection failed though false positive rate drops by a huge factor. It can be clearly seen in images below.

|
CAR detection
Using the exact concept which we used for face detection, we made a model that could detect cars. The dataset of car is avaiable on the UIUC Car dataset website here . Unlike the face detection, where the ratio fo width to height was 1, here the ratio of width to height is roughly 2. This needs to be taken into account when we are adjusting the parameters of the HOG descriptor for genrating an appropriate template. The template that we could generate using tweaking various parameters is as below:
Short Comings of HOG descriptor:
All the images that were used to extract hog features and train SVM were frontal faces. Thus model can detect faces that are frontal only. Profile faces and inclined faces cannot be detected with this kind of descriptor.
