Project 5 / Face Detection with a Sliding Window
get_positive_features.m
This is a relatively straight forward file to code. It basically allows for you to read an image and get its features from it. To do so, first read the file, convert the image to a singular image so that it is ready for vl_hog. Use vl_hog to extract the features from the image. No extra parameters are required. The cell size is given. To convert the feature to fit the feature_pos matrix, use reshape.
get_random_negative_features.m
This file is basically the same as get_positive_features.m. However, to generate several negative examples, I used randi to give me different minimum x and y coordinates of the same image. I used imcrop to generate the same sized negative images. To conclude, it was basically get_positive_features with the added bonus of using random start coordinates to get multiple negative examples.
classifier training
This is similar to the classifier training coded in the previous projects. X which is the unlabeled data is the appended version of feature_pos and features_neg. Y is the same size as X and is labeled as 1 for all feature_pos examples and -1 for feature_neg examples. To train the data, simply call vl_svmtrain with a suitable lambda. The only parameter to play around with was lambda. From the previous projects, we know that increasing lambda leads to avoiding misclassified examples. The default svmtrain suggested by the docs was 0.0001 and I stuck with it as works best.
rundetector.m
The goal of this file was to find the bboxes and their corresponding confidences from the test images at different scales. In order to do so I first extracted the features from every image using vl_hog. I iterated through the features (dim - row/cellsize, col/cellsize) while grouping features from cells together to form the template_size worth of pixels. I then resized the feature vector corresponding to the cell position and put it back into the cell_features matrix (dim N*D) so that I can calculate the confidences from the parameters w, b. Once I calculated the confidences, I filtered them by my predetermined threshold and calculated the corresponding bboxes, image_ids and confidences. While calculating the bboxes, I chose the length of each bbox to be template_size. I also normalized the sizes of the bboxes with their scale in order to allow the bbox to fit in the original image.
The parameters I played with were the threshold and scales. I tried thresholds ranging from 0.5 to 0.85. I noticed that thresholds above 0.7 and below 0.8 gave better results. I settled at 0.75. (0.6 threshold gave 0.81 accuracy and 0.8 gave 0.82 accuracy.) Again with the scales, I started with scales > 1 but I was limited by the memory on my machine so I chose to start at 1 and scale down. I chose to reduce scale by 0.7 and so I calculated scales from 1 to 0.2. More sensitivity to scales was unncessary as these scales gave a good accuracy and incorporating more scales did not give a great return on accuracy vs time. I also played with the number of negative examples. Increasing it ten fold to 100,000 increased to about 84%, a 2% increase.
EXTRA CREDIT
I did the extra credit of adding more positive images. I labeled and added 20 more images incrementally. After adding the first 5 images, I found accuracy to increase by about 1% to about 85%. However, for some reason as I added more images, the accuracy went down to about 75 then fluctuated and kept reducing as I added more images and finally settled at 50%.
I would hypothesize that this is because the labelling on my images were probably a little diffrent from the labelling in the dataset which I image to be of high quality. I also think that images found on the internet are higher in quality so the difference in size could have played a part as well. In doing the extra credit for this, I did learn the value of the time and effort it takes to create a high quality image dataset. I also think the camera angles and different expressions could account for the difference. Also it could be because I used memes as pictures for some. I have attached the extra images in the html folder and the text file for the ground truths.
for size = 6 and 10000 examples
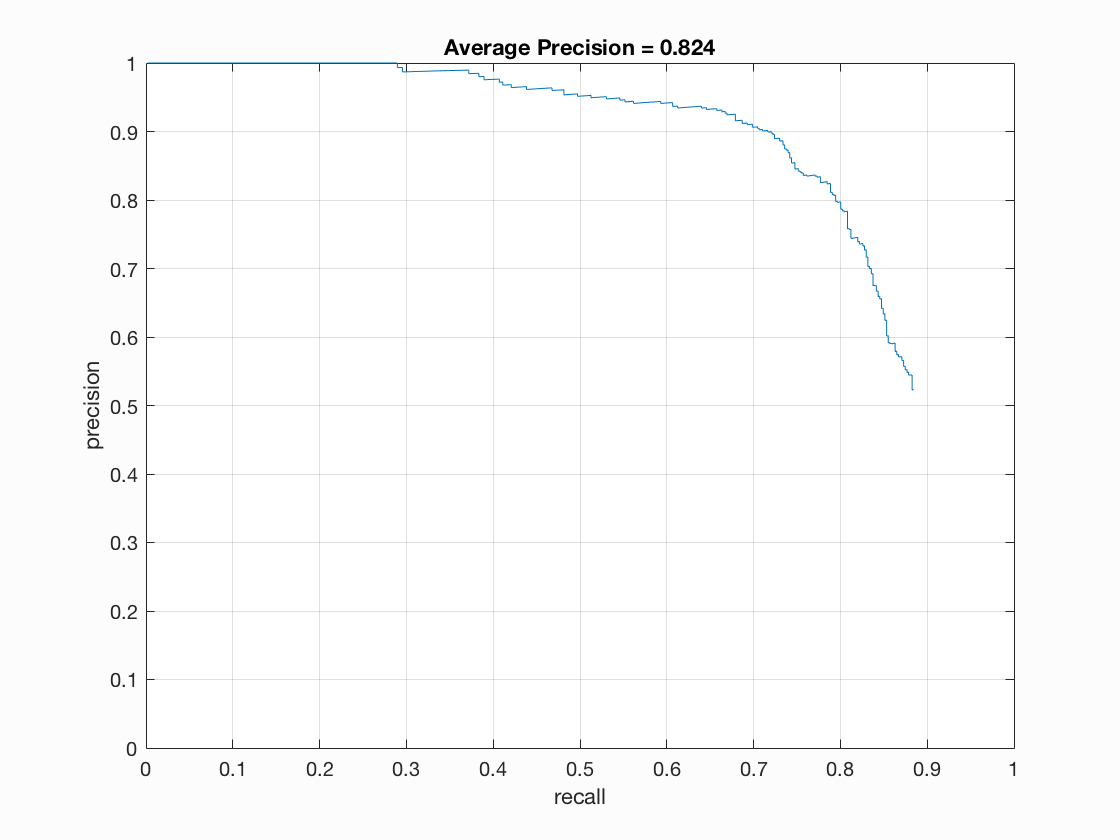
Precision Recall curve .
for size = 3 and 100000 examples
Example of detection on the test set.


Example of detection on the test set extra scenes.




