Project 5 - Face Detection with a Sliding Window

Face detection is a computer technology that identifies human faces in images. It is used in a variety of applications, like facial recognition in video surveillance, human computer interface, image database management, photography and marketing. In this project, the sliding window model, which independently classifies all image patches as being object or non object, is implemented. The basic pipeline can be outlined as follows -
- Getting positive features from the positive trained examples
- Getting random negative features from scenes which contain no faces
- Training the classifier with the above mentioned features
- Running the classifier on the test set
OBTAINING POSITIVE FEATURES
This function returns all positive training examples from 36x36 images. Each face is converted into a HoG template by a single call to vl_hog. The template size and the cell size is chosen as 36 and 3 respectively. This is because a smaller cell size improves accuracy, though it takes more time to run.
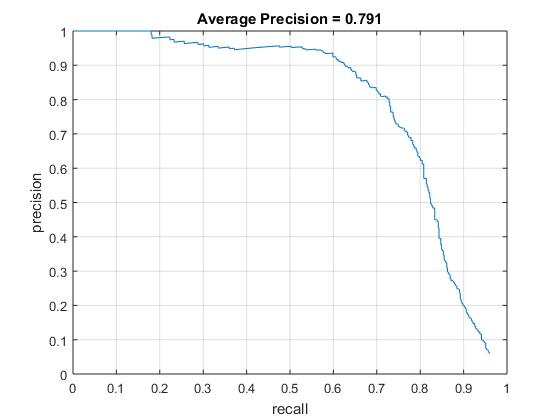
Choosing the cell size
Accuracy precision curve for cell size = 6
Accuracy precision curve for cell size = 3
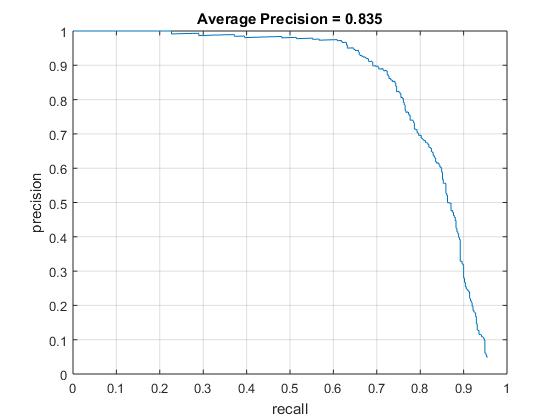
Hence, a cell size of 3 is chosen.
OBTAINING NEGATIVE FEATURES
This function is similar to the above function, except that this samples random negative examples from scenes which contain no faces and converts them to HoG features. The same feature parameters as above is employed here.
CLASSIFIER TRAINING
This function trains a linear classifier from the positive and negative examples with a call to vl_trainsvm. The regularization parameter lambda is an important parameter for training the linear SVM. It controls the amount of bias in the model, and thus the degree of underfitting or overfitting to the training data. Lambda value of 0.0001 is chosen for better results.
RUNNING THE CLASSIFIER ON THE TEST SET
This function converts each test image to HoG feature space with a _single_ call to vl_hog for each scale. Then the HoG cells are stepped over, taking groups of cells that are the same size as the learned template, and are classified. If the classification is above some confidence, the detection is retained and all the detections for an image are passed to non-maximum suppression. Different confidence values were implemented and a confidence of -0.5 gave the most accurate result. The general trend was with an increase in threshold, the accuracy increased but the number of false positives also increased. Hence, an optimum value of -0.5 is chosen. Non-maximum suppression, which counts a duplicate detection as wrong is run on the detections in order to improve the performance. The non-maximum suppression is done on a per-image basis. The scaling factor is taken as 0.75 and the image is scaled 10 times.
Output after basic pipeline
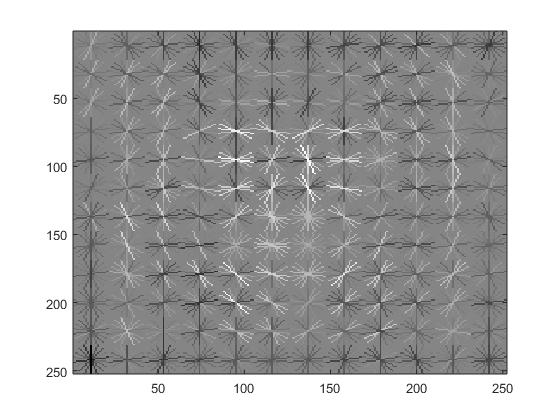
HoG features
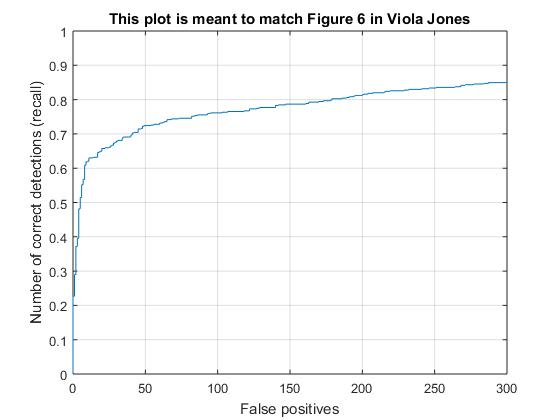
Precision Recall curve
Example of detection on the test set


EXTRA/GRADUATE CREDIT
HARD NEGATIVE MINING
The 'run_detector' function was modified to run the detector on the images in 'non_face_scn_path', and keep all of the features above some confidence level. That is, we are taking into account the features of all non faces that have been detected as faces, falsely by the detector. These features are then appended to the random negative features obtained previously and the SVM is retrained.
Comparison of results with and without hard mining for k = 6
Without hard mining
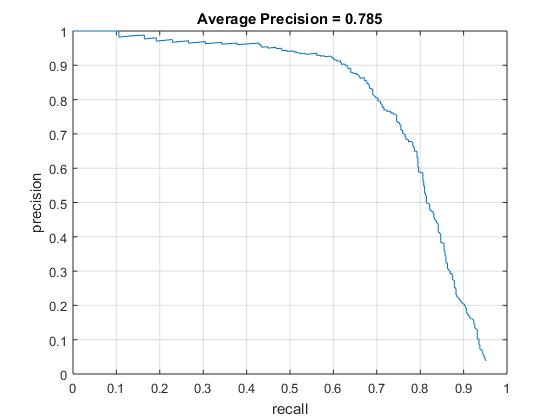
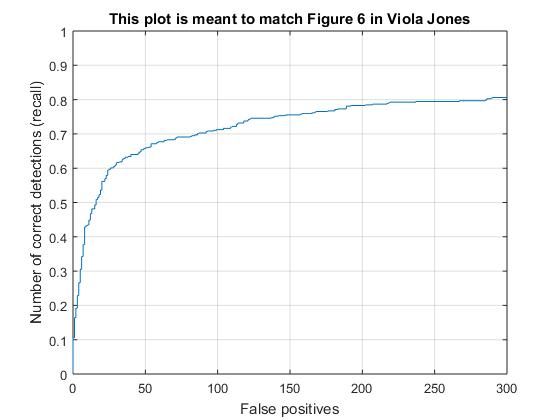
With hard mining
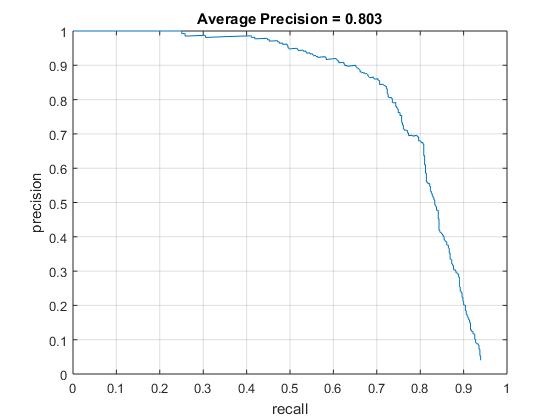
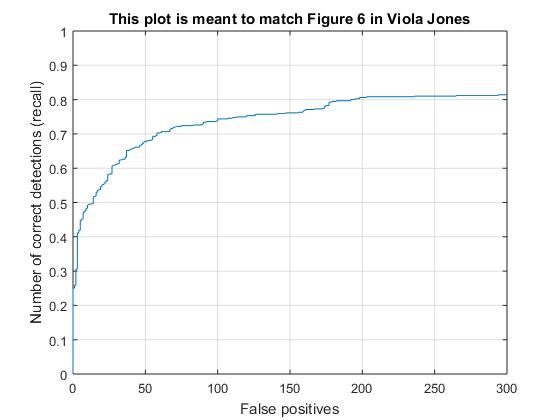
Example of detection on the test set after negative hard mining




As we can see, the number of false positives has reduced significantly after negative hard mining.
MIRRORING, ROTATING IMAGE AND OBTAINING POSITIVE FEATURES
The image is flipped, rotated and the positive features are taken. This allows detectiom of even tilted faces
The sliding window protocol works efficiently in detecting faces. However, all the faces might sometime not be detected clearly and the number of false positives might sometime be very high. Hence, the parameters such as lambda, confidence, number of samples, training data etc influence the accuracy to a large extent and must be tuned properly. The accuracy improves as one increases the number of positive and negative features ( using hard negative mining).