Project 5 / Face Detection with a Sliding Window
Project description
The purpose of this project is to perform sliding window model to detect if certain scene contains faces or not. In order to achieve that, I extracted the HoG features of example faces as positive examples, while obtaining the HoG features of random portions of nonface scenes as negative. Then, a linear SVM classifier was trained based on those examples. Finally, I applied this trained classifer to the testing data and get result to evaluate this implementation.
- Get positive and negative features
- Train classifier using linear SVM
- Classifier on training data
- Classifier on testing data
1, Get positive and negative features
First I need to obtain the HoG features of both positive and negative examples. This is simply done by using the MATLAB build-in function vl_hog like below. The positive examples were provided as several 36x36 human faces. The negative examples are scenary photos that contain no faces. For the negative example, I randomly extract features in different scaling.
vl_hog_results = vl_hog(single(IM), feature_params.hog_cell_size);
2, Train classifier using linear SVM
This is pretty straight forward by using built in function vl_svmtrain. The positive features were all labeled 1, while the nagtive features were all labeled -1 when passed in as parameters.
lambda = 0.0001;
X = [features_pos; features_neg]';
Y = ones(1, size(X, 2));
Y(size(features_pos, 1) + 1:end) = -1;
[w b] = vl_svmtrain(X, Y, lambda);
3, Classifier on training data
Applying the SVM classifier to the training data. In this application, we can adjust the value of lambda to determine the level of the model that allows penalty. A smaller lambda would result in smaller penalty, and vice versa. In addition, if the lambda to be too small, a overfitted model would possibly be formed, while a too large lambda would result in over-generalized model. Here are the results compared with different lambda in SVM. Either too small lambda or too big lambda would lowering the precision. Also, the model can be affected by the cell size in building HoG feature. Smaller cell size means greater precision but lower speed. There is obviously a trade-off between the precision and speed.
Initial classifier performance on train data with cell size 6 and lambda 0.0001:
accuracy: 0.999, true positive rate: 0.653, false positive rate: 0.000, true negative rate: 0.347, false negative rate: 0.000
vl_hog: descriptor: [6 x 6 x 31], vl_hog: glyph image: [126 x 126], vl_hog: number of orientations: 9, vl_hog: variant: UOCTTI
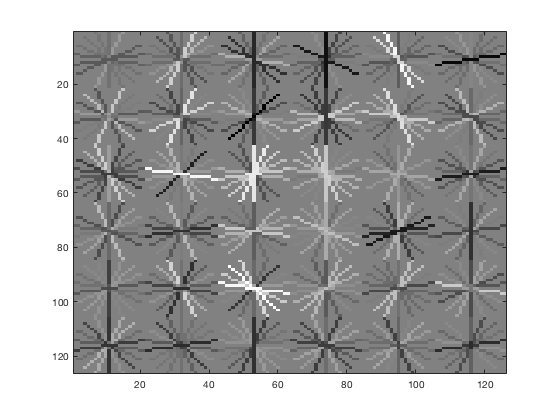 |
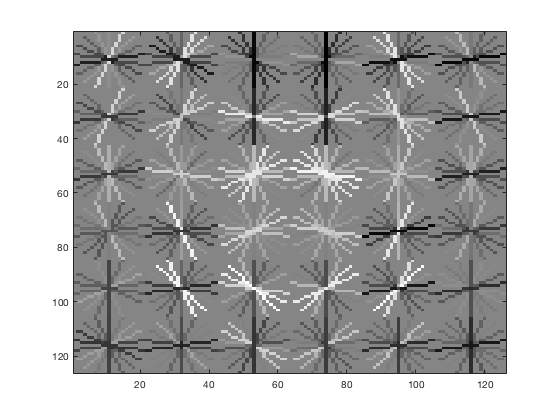 |
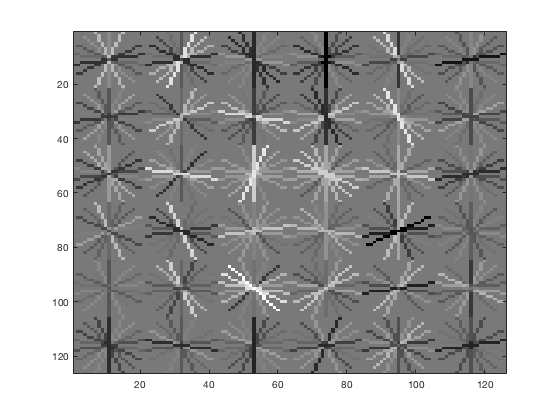 |
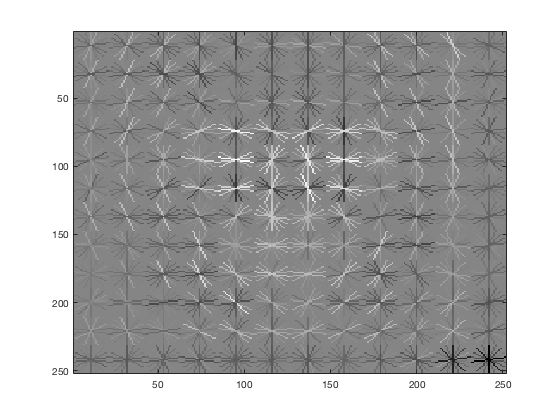 |
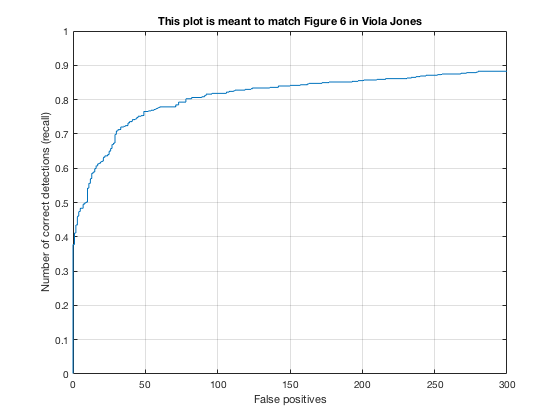
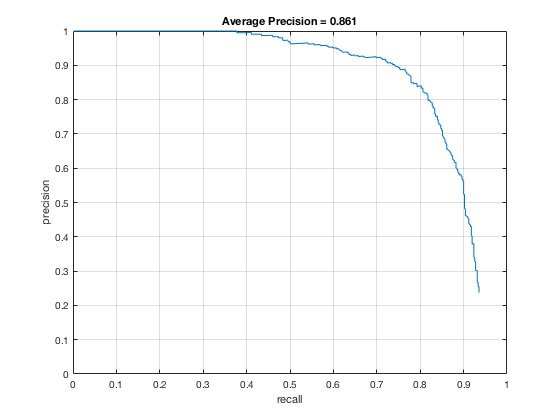
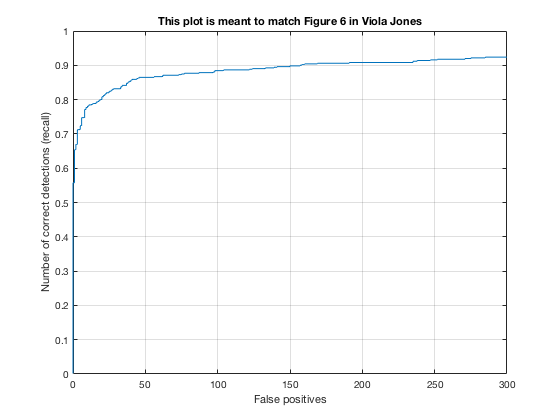
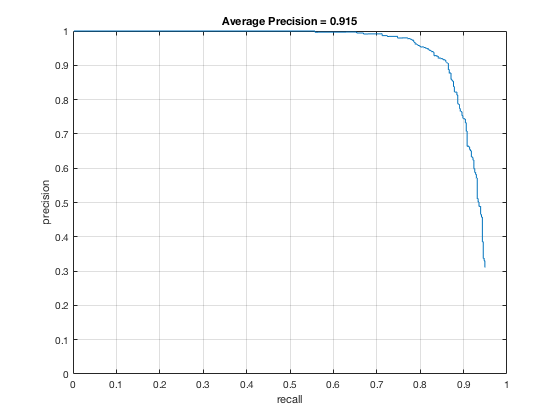
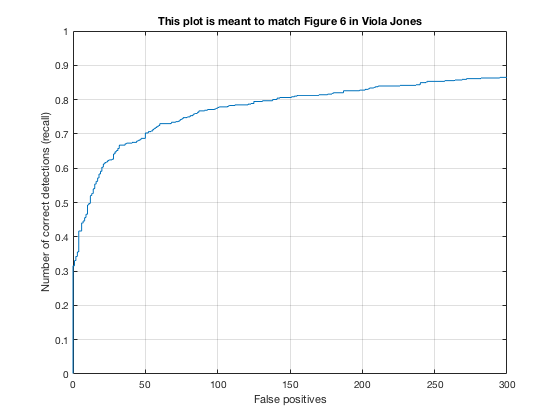
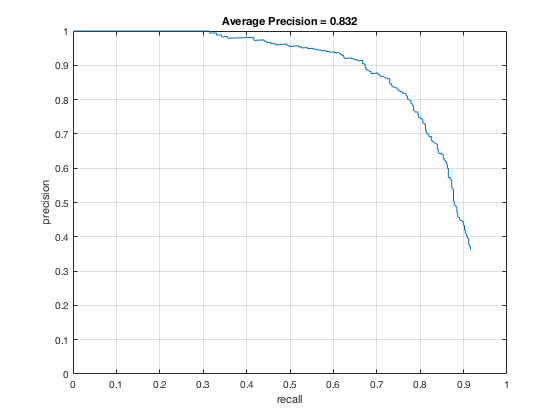
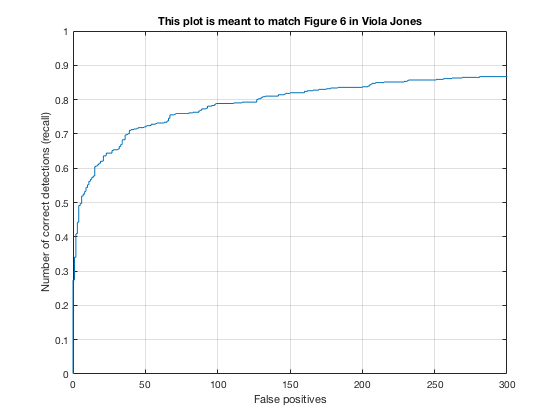
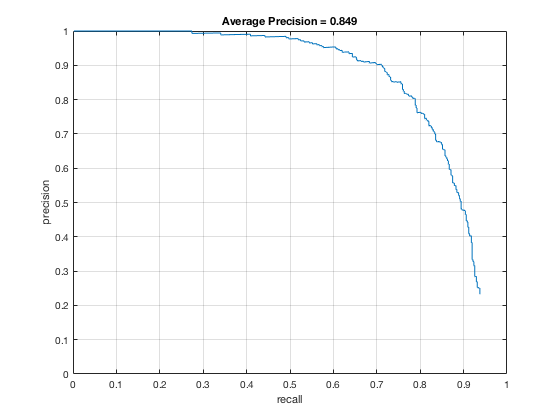
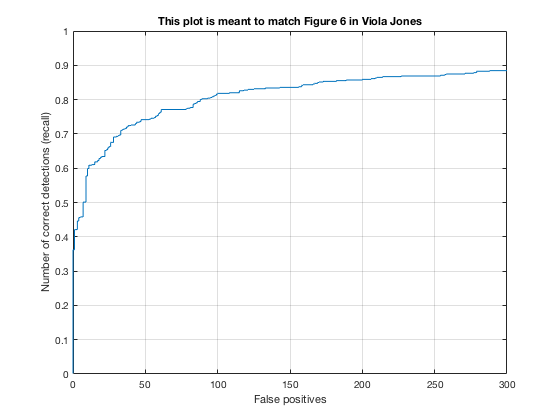
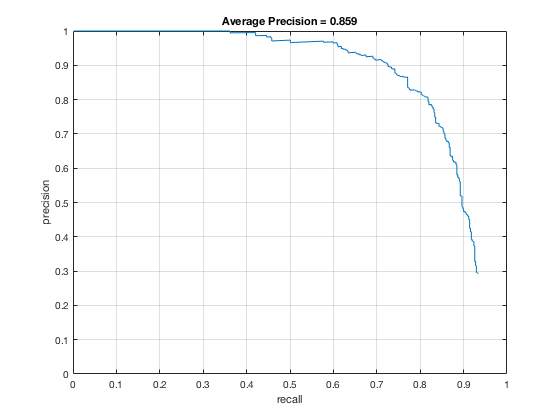
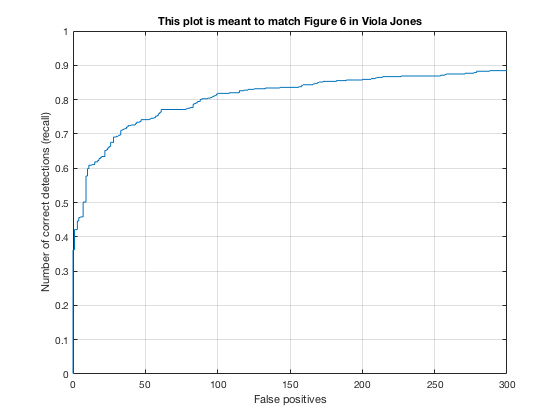
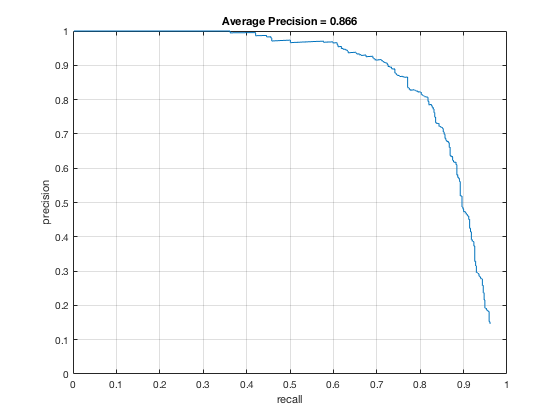
4, Classifier on testing data
Applying the trained model from previous step and test it on testing sets.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Conclusion
According to the controlled results: smaller cell size would result in higer accuracy, which is approximately 0.9. However, it will increase the false positive rate. On the other hand, change in lambda size would not affect fp rate and precision that much. However, lower lambda, which results in a little over fitting, would cause slower climb in false positive rate while increasing true posive prediction. In addition, change in threshold would lower the precision rate, also causes greater decrease in precision while recall increases.
In conclusion, the best paramter I found is cell_size = 3; lambda = 0.0001; threshold = 0.5.