Project 5 / Face Detection with a Sliding Window

This project consisted of using a sliding window detector to detect faces within a picture. HOG features were used to train an SVM to determine if a certain patch contained a face. At first only a single scale detector was used, but multiple scales were later implemented.
Gathering Training Examples
Positive training samples were given as a 16x16 grayscale image that contained a crop of a face. These were converted to a set of HOG features that were then vectorized. Negative training examples were gathered by sampling random 16x16 patches from images that were known to not contain faces. Again, the patches were converted to a set of HOG features and then vectorized.
Single Scale Detection
At first, detections were only made at a single scale. This worked well if the faces in the image matched the template size of 16x16 pixels. However, faces that were larger or smaller were always missed. The fast run time of the single scale detector allowed for a quick way to tune other parameters when trying to maximize the average precision of the system.
The code was first run with a "lambda" SVM parameter of 0.001, a hog cell size of 6, and confidence threshold of -0.75
|
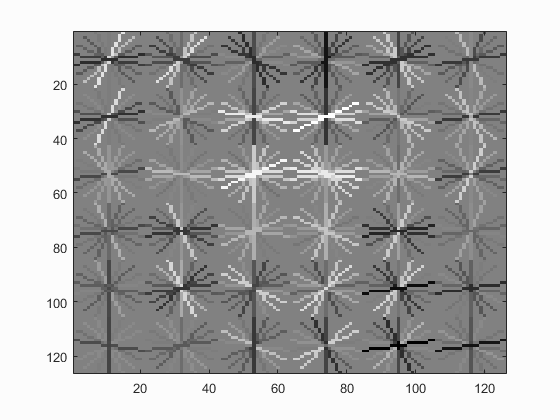
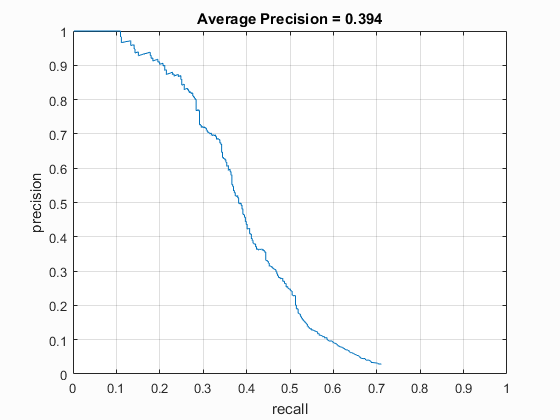
Left: HOG template generated when using a HOG cell size of 6. Right: Precision recall curve of the trained classfier.


|
Detections with a confidence threshold of -0.75.
Images with faces that happen to be approximately 16x16, the size of the training examples, are often successfully detected. However, due to the low confidence threshold, many false positives were also detected. To reduce the amount of false positives, the confidence threshold was increased to 1.1


|
Detections with a confidence threshold of 1.1.
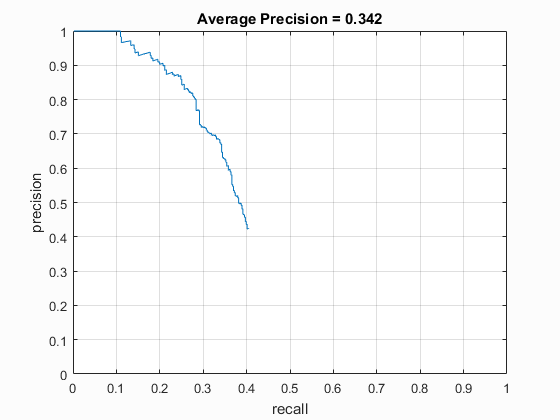
After increasing the confidence threshold to 1.1, many of the false positives were eliminated, but some true positives were also filtered out. While in the two examples shown most of the faces are detected, looking at pictures with faces bigger than the template size makes the detector unable to detect them. Such examples are shown below.

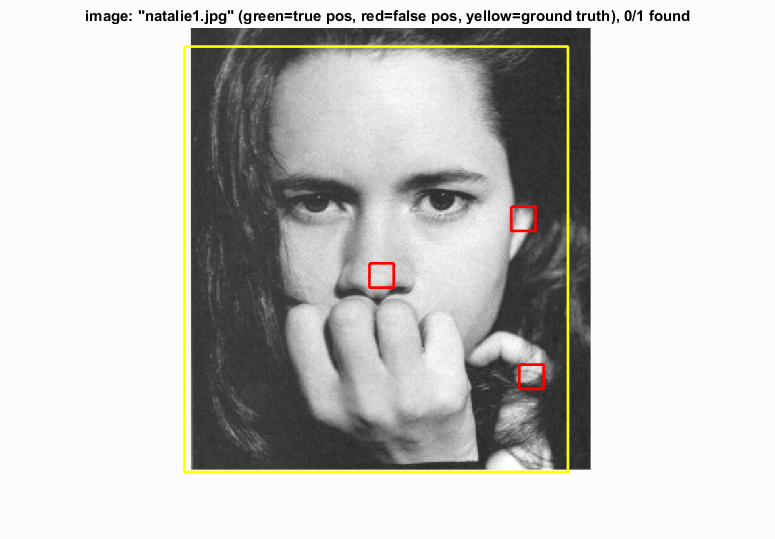
|
Images where a single scale detector is unable to find faces.
SVM Tuning
Before moving on to a multi scale detector, the lambda parameter of the SVM was explored. The examples above were a result of a SVM that was trained with a lambda paramter of 0.001. While the lambda parameter was varied, the threshold confidence was kept constant at -0.75, HOG cell size at 6, and only a single scale used.
| lambda | Average Precision |
| 0.000001 | 0.389 |
| 0.00001 | 0.390 |
| 0.00001 | 0.400 |
| 0.0001 | 0.383 |
| 0.001 | 0.342 |
| 0.01 | 0.389 |
| 0.01 | 0.275 |
It seems that a smaller lambda works generates a better trained SVM up to a certain extent.
Multi-Scale Detection
In order to detect faces larger than the template size, multi-scale detection was implemented. This was a simple task, as the image only needs to be scaled and the bounding boxes detected unscaled to fit the original image.
scaleStep = 0.7;
img = imresize(img, scaleStep);
...
%other code unchanged from single scale detection
...
curs_bboxes((x-1)*numFeatsY + y,:) = floor([(x-1)*feature_params.hog_cell_size+1, (y-1)*feature_params.hog_cell_size+1, ...
((x-1)*feature_params.hog_cell_size+feature_params.template_size+1), ...
((y-1)* feature_params.hog_cell_size+feature_params.template_size+1)] ./scaleStep;
The lambda paramter was kept at 0.001 to make it comparable to the single scale detector. The HOG cell size was kept at 6 and 15 scales were used for each image, with every scale rescaling the image by 0.7.
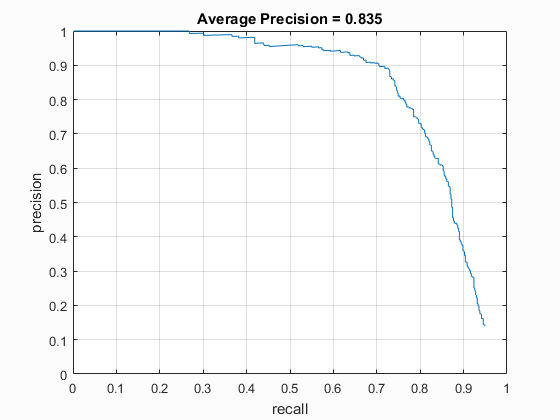

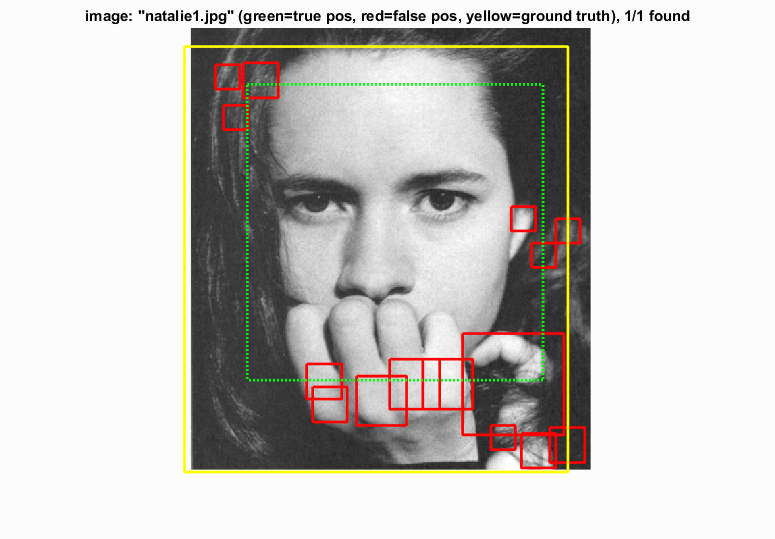
The multi-scale detector is able to find larger faces. Confidence threshold is 0.25.
With the multi-scale detector many more faces are detected, almost doubling the average precision. Once again, to reduce the amount of false positives, the confidence threshold was increased, this time to 1.3
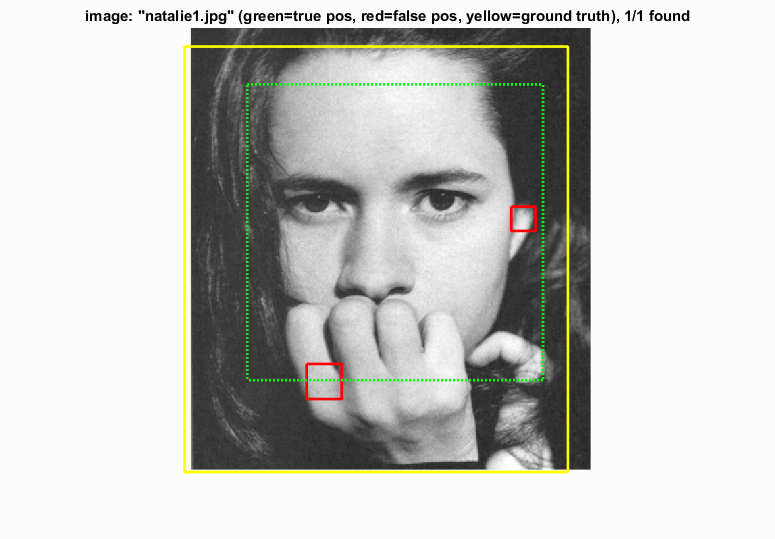
Multi-scale detection with a confidence threshold of 1.3
Further Increasing Accuracy
Finer HOG Resolution
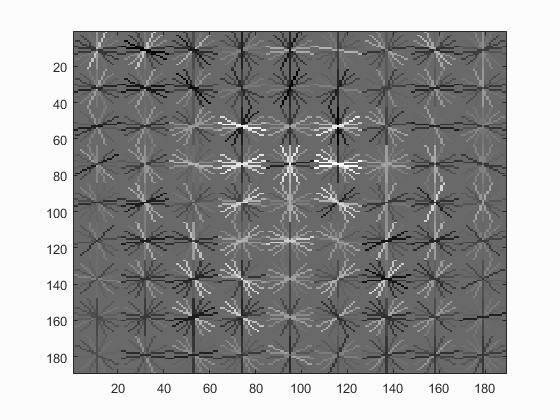
Decreasing the HOG cell size will create more HOG descrptors per patch, creating a finer resolution descriptor of the object being detected. First the HOG cell size was reduced from 6 to 4.
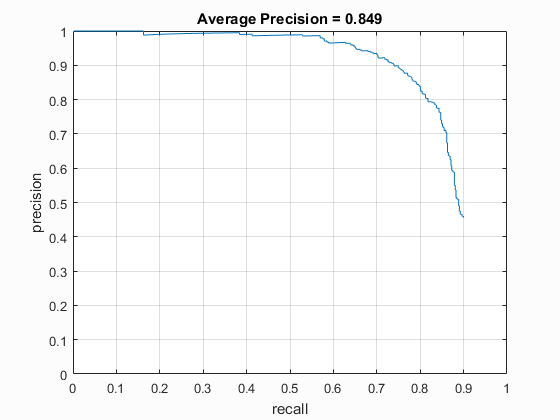
|
Left: HOG template generated when using a HOG cell size of 4. Right: Precision recall curve of the trained classfier.
Generating more HOG features does increase the precision, so the HOG cell size was then reduced even further to 3 to try to further increase the average precision.
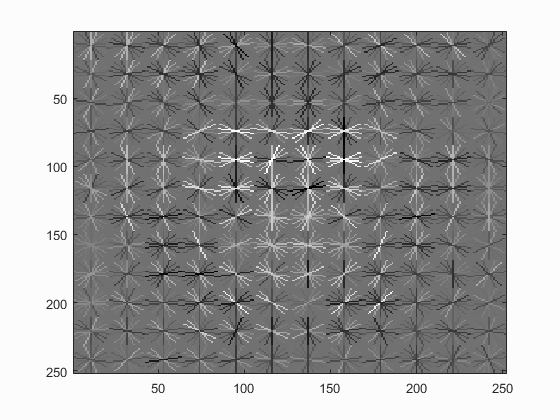
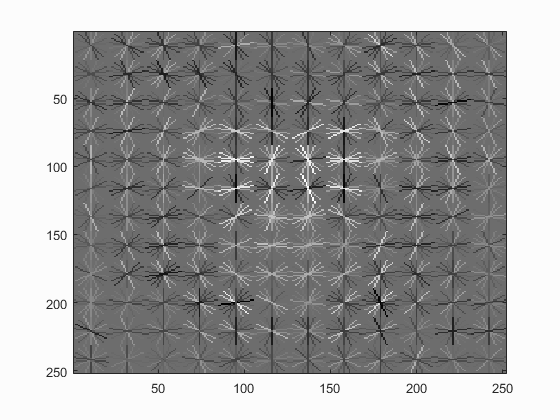
|
Left: HOG template generated when using a HOG cell size of 3. Right: Precision recall curve of the trained classfier.
Smaller Scale Jumps
More data can also be gathered from the images by scaling by a smaller amount every iteration. Scaling by 0.9 instead 0.7 with 20 iterations instead of 15 allows a finer scale-step to be established.
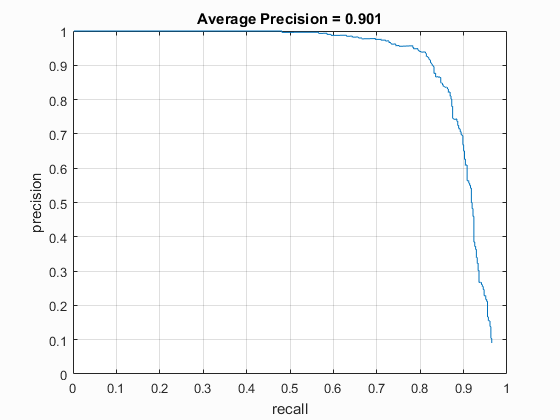
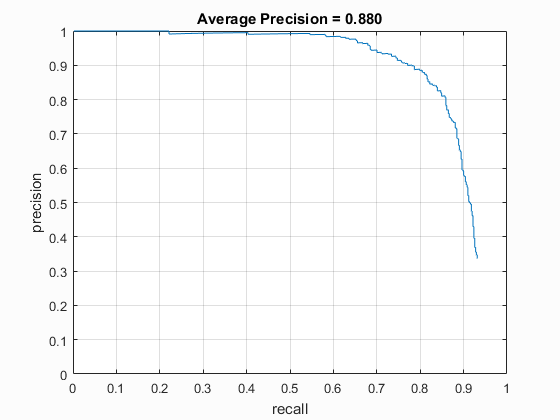
|
Left: HOG template generated when using a HOG cell size of 3. Right: Precision recall curve of the trained classfier using a scale step value of 0.9.
While this increase in resolution does increase the average precision,
Using the Optimal SVM Lambda
As seen in the previous steps, the optimal lambda paramter was determined for the single-scale detector was 0.0001.
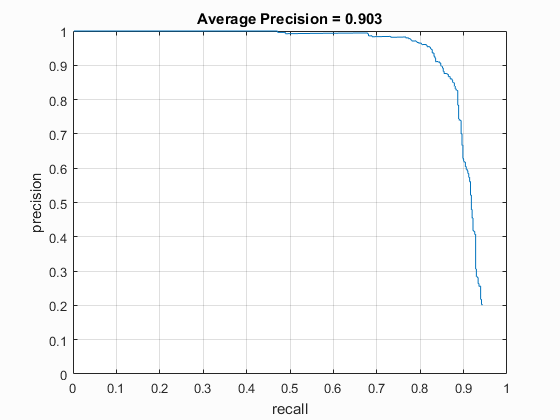
Using a smaller lambda parameter allows for a small increase in the average precision.
Extra Images








