Project 5 / Face Detection with a Sliding Window
In this project, I implemented the following:
- Get Positive Training Samples
- Get Random Negative Training Samples
- Run Trained Detector on Test Images
Get Positive Training Samples
The HOG features are extracted from images using vl_hog with specified hog cell size. To augment the training data, I added the horizontally flipped training images into the training set (thus doubled the size). The images are scaled so that values of pixels lie between 0 and 1 (instead of 0 - 255).
Get Random Negative Training Samples
Similarly, I extracted the features from the negative images, with max negative set size specified. After features for each image are calculated, samples (with size being the specified HOG cell size) are cropped from the features. To ensure that we get maximum information from these samples, I ensured that each of the samples are at least half of the template size away from others.
Run Trained Detector on Test Images
I ran the trained detector on the test images with the following steps
- Create scaled images. The smaller the scale, the larger the detection proposals will be.
- Extract features from the scaled images
- Run sliding window on the extracted features (with window size = template size / cell size). Step size is set to one (so every possible window with the window size is included).
- Run classifier and keep the windows with confidence higher than some threshold. Calculate the correct bounding box in the original unscaled image.
- Non-max suppresion
- Extract features from the scaled images
Result
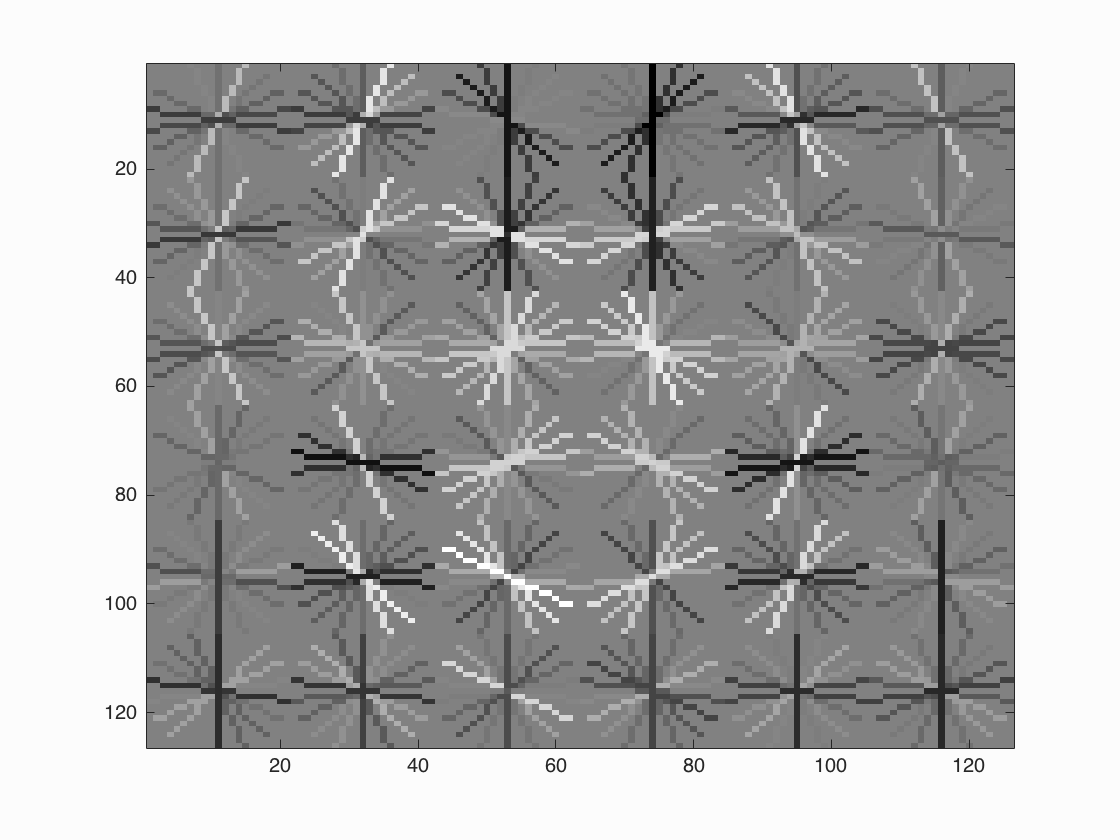
Face template HoG visualization with lambda = 0.0005.
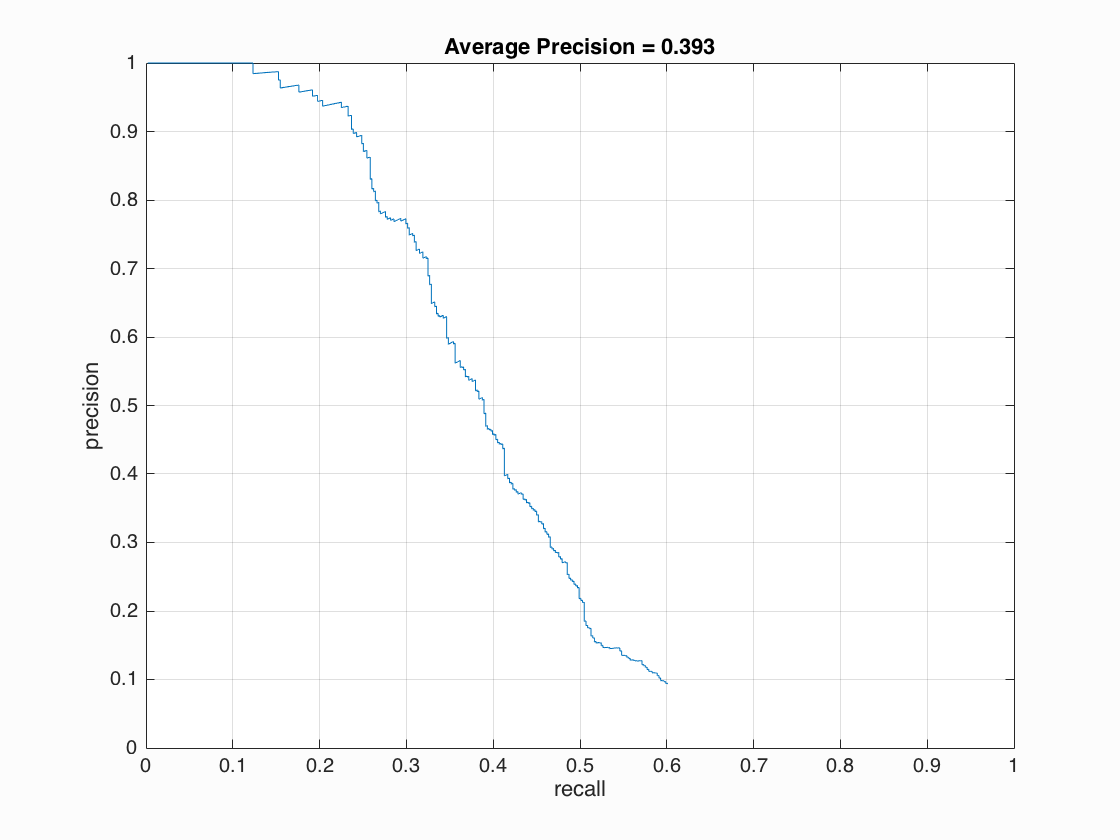
Precision Recall curve with cell_size = 6, lambda = 0.0005, threshold = -0.6 and scale = [1] (i.e. no scaling).
Example of detection on the test set with cell_size = 6, lambda = 0.0005 , threshold = -0.6 and scale = [1].

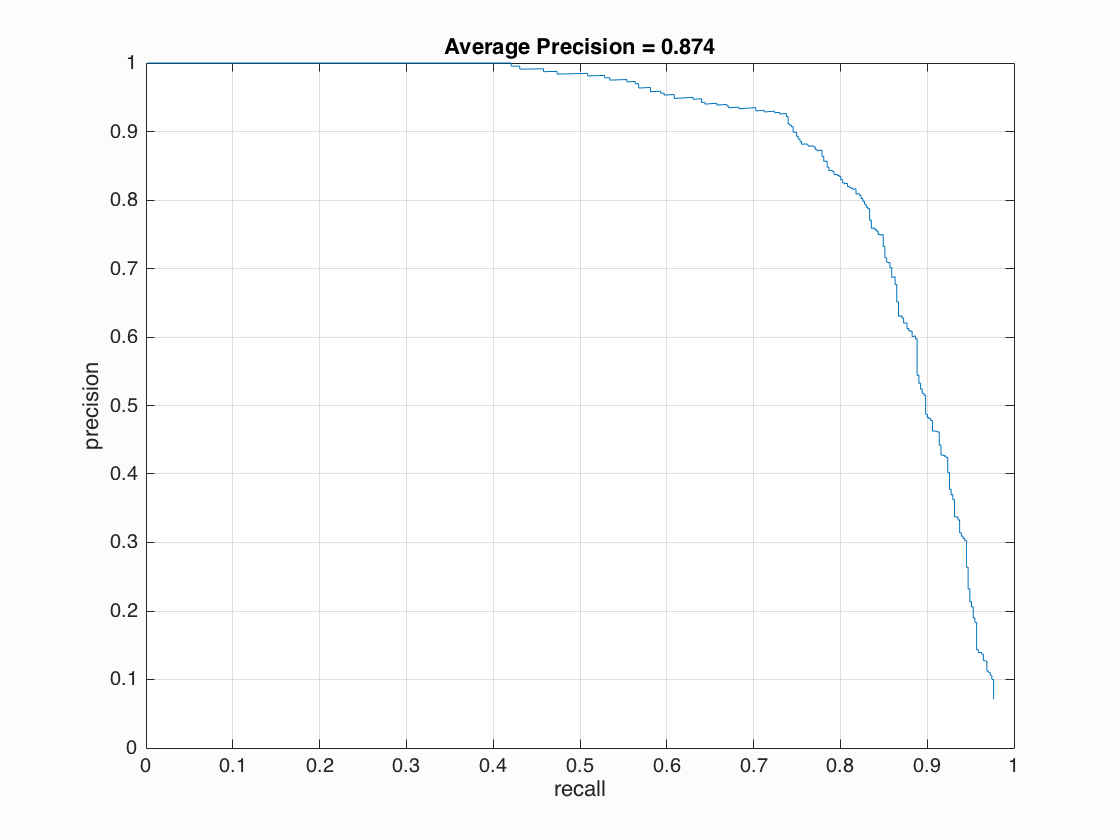
Precision Recall curve with cell_size = 6, lambda = 0.0005, threshold = -0.6 and scale = [1,0.9,0.8,0.7,0.6,0.5,0.4,0.3,0.2].
Example of detection on the test set with cell_size = 6, lambda = 0.0005 , threshold = -0.6 and scale = [1,0.9,0.8,0.7,0.6,0.5,0.4,0.3,0.2].

With higher threshold = 0.7
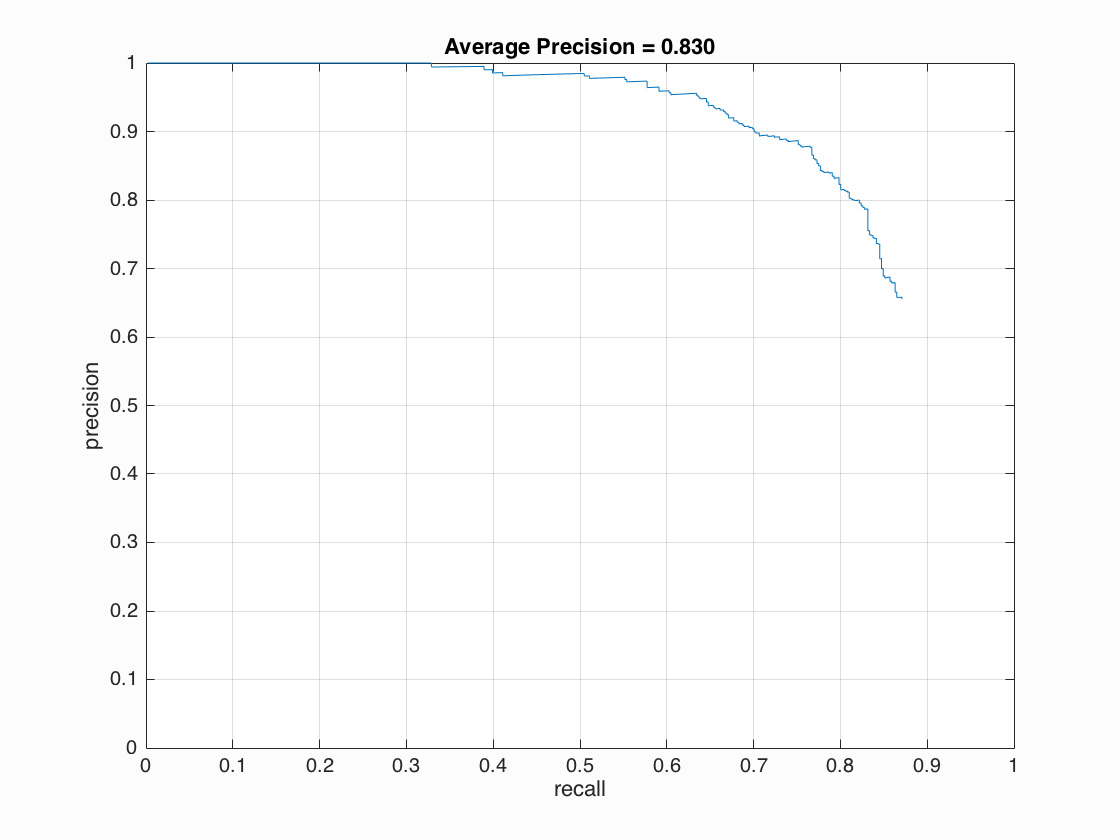
Example of detection on the test set with cell_size = 6, lambda = 0.0005 , threshold = 0.7 and scale = [1,0.9,0.8,0.7,0.6,0.5,0.4,0.3,0.2].

Discussion
Since the values of images are small, small lambda values work better. With trial and error, I set lambda = 0.0005.
Single scale detection only obtains around 0.4 mAP, since smaller faces in image cannot be recognized with a large window.
With high threshold (say 0.7), the number of detected windows are much less and the speed is faster. However, for some images there are no detection windows. It seems that, with strong computational power, it's better to keep more detection windows before throwing them into non-max suppresion (and later threshold the output of non-max suppresion).
Also, it seems that the step size can be made larger, depending on the scale of image. This can further accelarate the detection.
Lastly, using smaller cell size can make the detection finer (and thus have greater mAP).
Some More Analysis
With cell_size = 6, threshold = 0.7 and scale = [1,0.9,0.8,0.7,0.6,0.5,0.4,0.3,0.2], the detector has bad performance on some images.



For the first image, the face almost takes the whole image. So it may be desirable to have smaller scales included during detection. Similarly, there might be small faces in large images. Therefore, adpative scale can be used to solve these issues.
To have better performance on the second image, it may be better to also include vertically flipped images in the training set.
The third image is hard, not only because that the shape is too simple but also because the aspect ratio of the bounding box is not square. It may help if we can run detection with multiple templates (of different aspect ratios).